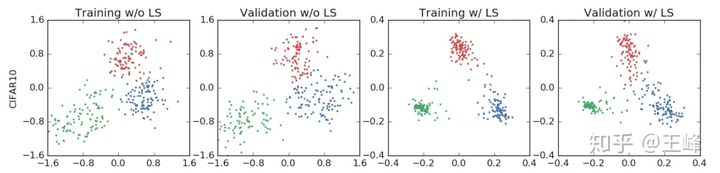
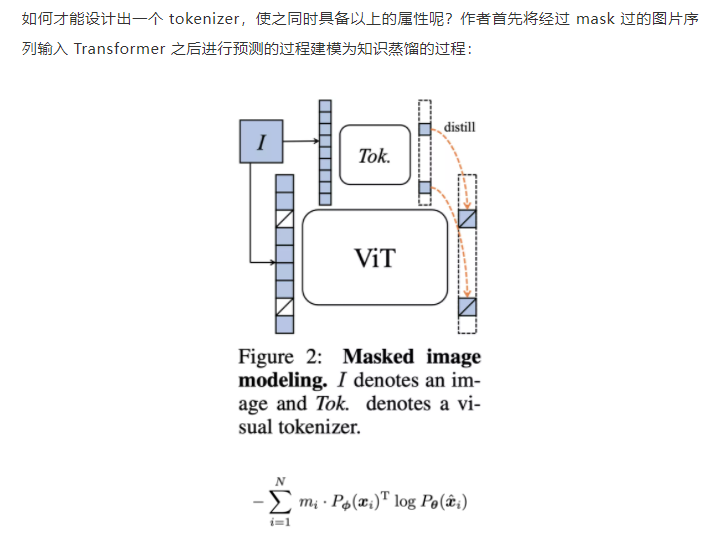
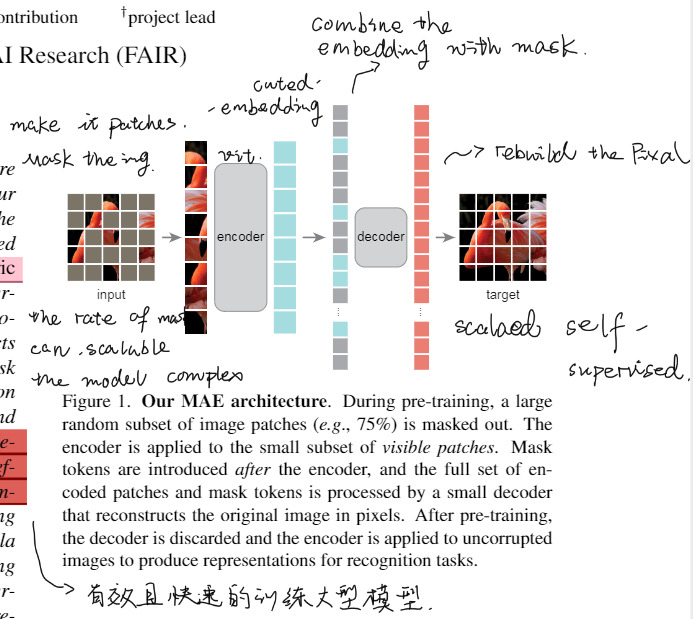
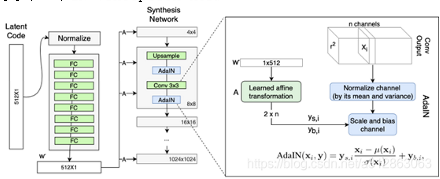
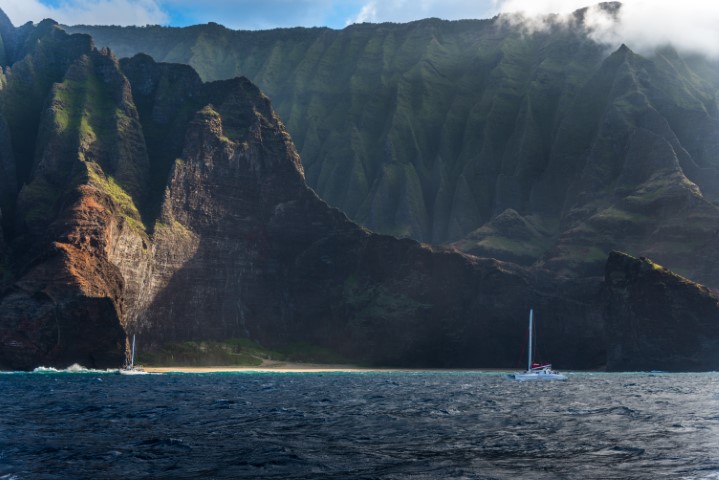Fine Tuning
@Langs: python, torch
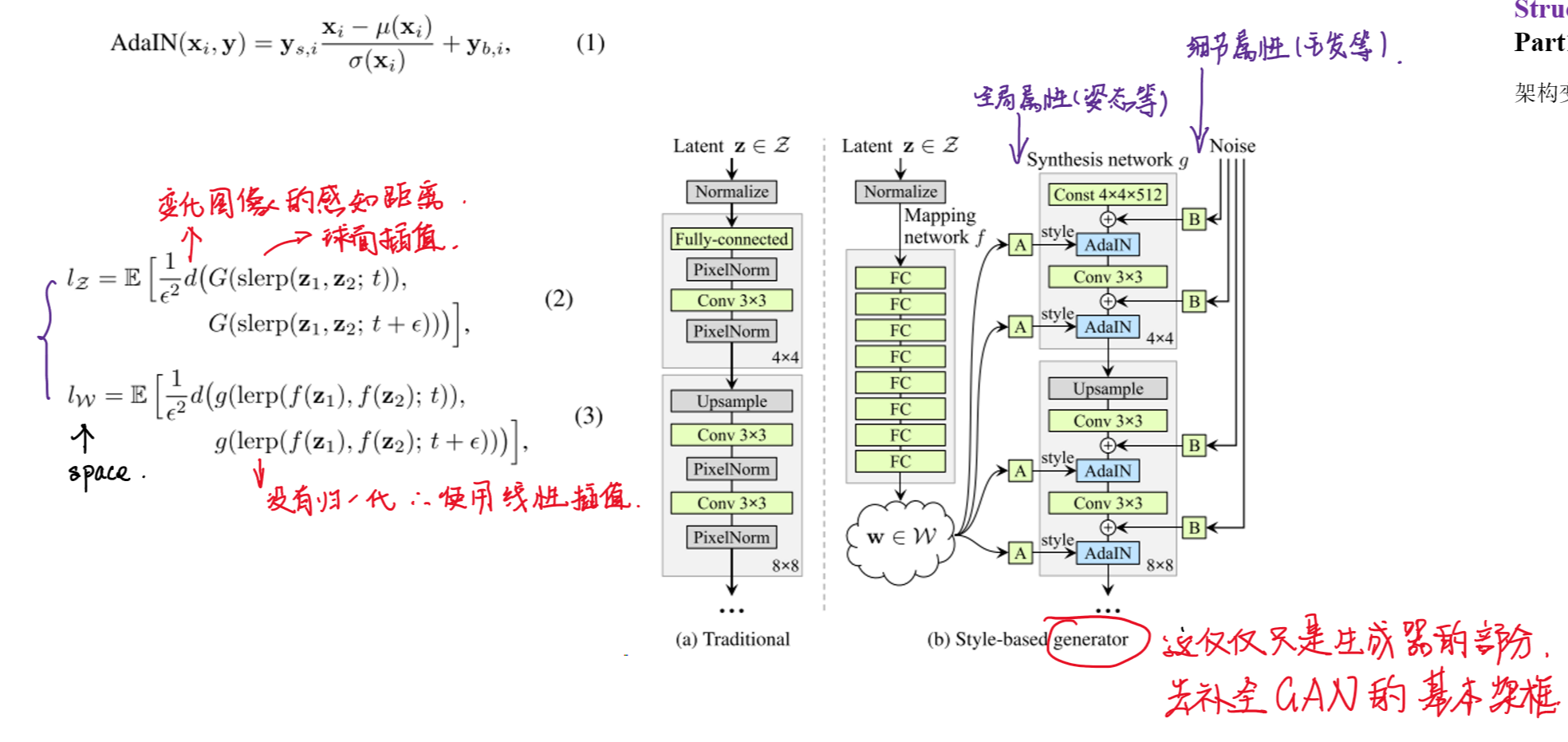
@reference: d2l-pytorch,transfer_torch
This Note focus on the code part.
模型微调和模型预训练,在Pytorch中的使用方式对比汇总。
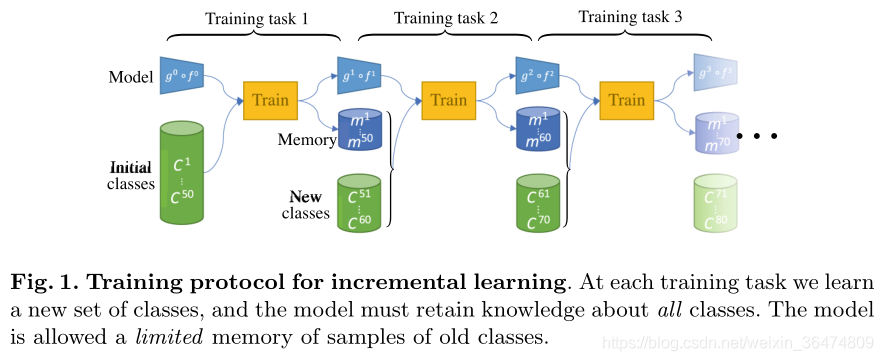
How to Design the Fine Tune
这一部分主要集中于我们对于微调任务的拆解,有几种不同的预训练和微调的方式,在不同的情景下,对应的参数应该怎么设置和调整是问题的重点。
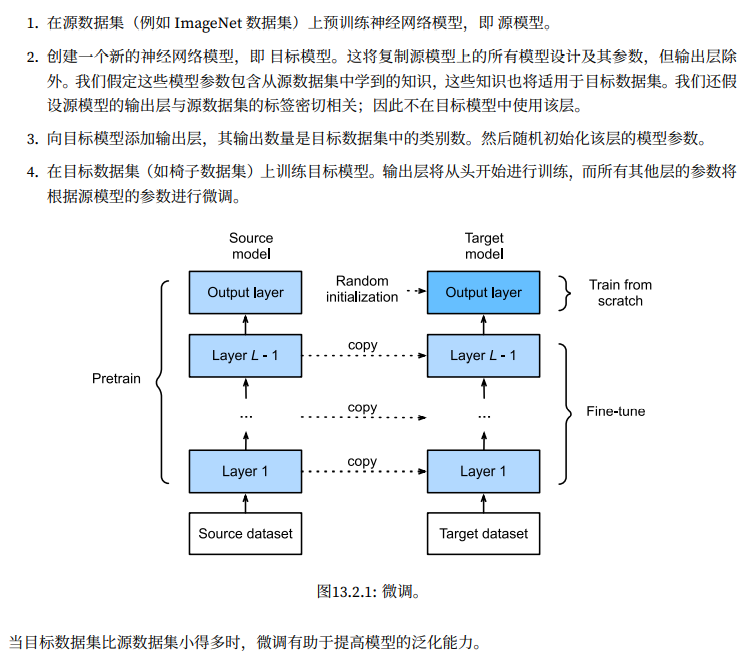
基于这种Transfer的策略,我们能够学习到一个更通用,泛化能力更强,有助于识别边缘,色彩,等等有助于下游任务的通用特征提取。
在Transfer任务中,有几种不同的调整方式:
- 固定Bakcbone,只训练Classifier
- 同步微调网络
- 区分学习率,微调Backbone,训练Classifirer
为了实现这几种不同的Transfer方式,需要用到以下的几种方式:梯度截断,lr区分设置等。
Code Part
不同lr设置
微调Backbone,训练Classifier作为最经典的Transfer设定,在Code上也较为复杂,所以我们首先举个这种例子。