
IL Collection
@AikenHong 2022
[[Draft/IL 总结]]: Thx 2 wyz to provide some clus for learnning Incremental Learning.
In this Doc, we may add some related knowledge distill works which is used to design our Incremental Structure.
在这个文档中,我们可能还会添加一些知识蒸馏的相关工作的文献,这些实际上对于我的增量学习架构有一个比较大的启发
- DER
- SPPR 没有 get 到方法到底是怎么做的
Introduction 👿
在很多视觉应用中,需要在保留旧知识的基础上学习新知识,==举个例子==,理想的情况是,我们可以保留之前学习的参数,而不发生==灾难性遗忘==,或者我们基于之前的数据进行协同训练,灾难性遗忘是 IL 中最核心的问题。
Incremental 的基本过程可以表示如下[4]: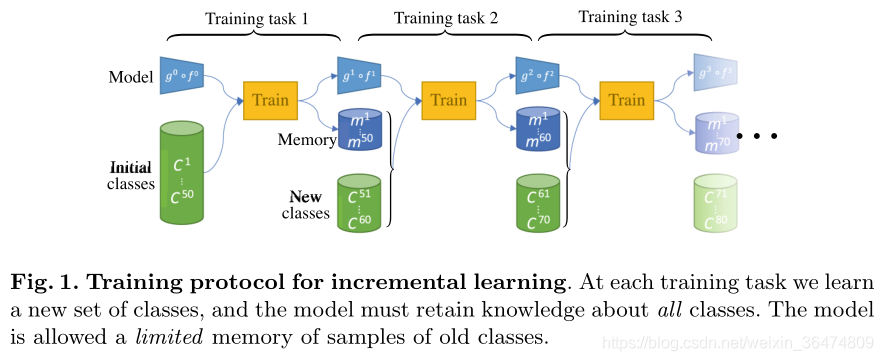
我们将模型可以划分为以下的两个部分[1]:backbone 和 classifier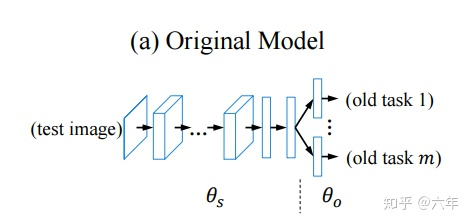
从 LWF 中我们可以知道经典的 Paradigm,主要有下面的三种来对$\theta _S$ 和$\theta_o$来进行更新:
- 仅重新训练分类器:仅更新$\theta_o$
- 微调特征提取器,重新训练分类器
- 联合训练
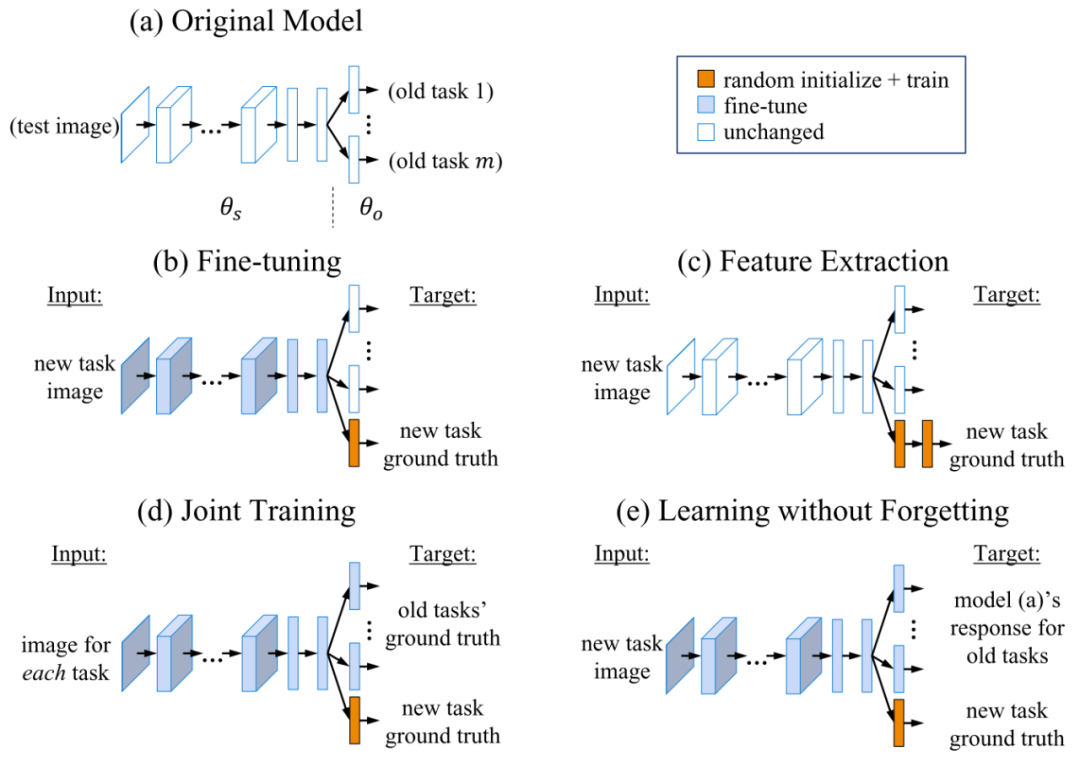
基于蒸馏架构的方法
这一系列的方法实际上是 IL 最经典的发展路线,实际上从初始的蒸馏架构开始,最后逐渐的发展到结合回放的策略中,我认为结合rehearsal才是该类方法最后的归宿,所以我将基于蒸馏正则化的 Pod 和 LWF 也放到了这一部分。
Motivation
《Learning without Forgetting》LWF 主要带来的就是将 KD 损失引入 Joint Training 的范式,也就是我们印象中最原始的增量学习的途径,利用 expand_dim 训练最后输出的新的节点,但是这个范式是不需要旧数据。
这里的蒸馏使用的是最终的 pred 输出,后续对于蒸馏损失的有 KDC 的变体,根据新旧样本的比例来赋予权重,考虑模型优化的权重。
其中 $\lambda^2 = \frac{|C{old}|}{|C{old}|+ |C_{new}|}$
这就是最经典的 Incremental Learning 的范式,我们首先继承一部分分类器的参数,然后通过这个损失对整个框架进行协同训练。
引入旧样例
《ICaRL: Incremental Classifier and Representation Learning》在 LWF 基础上引入部分旧数据来避免灾难遗忘的问题
- 基于特征提取器对新旧数据的训练集提取==平均特征向量==(Kmeans + KNN)
- 基于最近邻均值分类算法 NME 计算出新旧数据的预测值 计算 LWF 的经典损失,优化模型
本文的亮点主要在于引入了旧的数据进行复习(有一个比较好的数据选取策略),以及最后使用的不是全连接层而是最近邻分类器来作为预测。(Will This Get Better?)
后续在 ==《End-to-End Incremental Learning》== 中,将最近邻分类器替换成分类层,其动机就是对 ICaRL 进行优化。
memory 保存旧样本 -> CE+KD -> reBalance + Fine-tune

由于数据量上的有偏,导致分类器会严重有偏与 New-Classes,但是我认为这个可能是对于场景设定的不同,加入新的需求和发现少量的数据两者是一个比较大的不同。
这里的 样本选择策略 可能在后续会比较有用。
- 在 ICaRL 中选择的是最确信的样本来 rehearsal,也就是使用特征中心的 KNN 方法来选取样本。
- 而在==《Rainbow Memory》==[8]中则是选择最难的样本,其 motivation 是选择最接近判别界样本
RM 的最终实现的思路是通过 Data Augmentation 对样本进行变化,将不同 Augmentaion 后的预测的偏差(不确定程度)来衡量一个样本是 Hard or Simple Task,基于这种方式来选择 Hard-Task(Uncertainty)
具体而言,标签为 c 的样本,经过 perturbed 后,被网络预测为 c 类的次数越多,则不确定性越弱。
优化分类器
由于新类的大量数据带来的偏差,==《Large Sacale Incremental Learning》== 试图解决这个问题
- 将训练集划分一个 rebalance 的 dataset 作为验证集,并用该数据集训练一个 Bias Correction Layer 得到修正的参数,
该层的输出如下,实际上就是一个线性回归层,只有两个参数
训练该层的时候固定 CLF 和 BB,使用 CE 损失即可,但是模型在大数据集上的表现更佳,在 cifar100 的小数据集上表现一般。
另外还有借助 Long-Tailed 中的策略,从$||W||$的角度矫正偏差的文章 ==《Learning a Unified Classifier Incrementally via Rebalancing》==
动机是由于:1)imbalance:new classes 的权重的大小远远高于 old classes 的权重。2)特征与 old classes 的权重关系没有保留。3)一些 new classes 的权重与 old classes 的权重相近(容易混淆的类别),导致歧义性。
引入了 Cosine Normalization 分类器,实际上就是进分类器之前进行正则化,加入 Margin 损失(可以参考人脸比对的 Cosine Face 之类的)最终损失为:
更简单的有==《Maintaining discrimination and fairness in class incremental learning》==,通过对于分类器中的新旧模型的weight 做 Rescale 使其再 W 上达成一致来维持一个较好的效果
优化特征提取器
其实Incremental现阶段的任务也倾向于使用两阶段的架构,基于这样的架构,我们首先提名最重要的就是基于SCL的这篇文章[9],这篇文章主要的思路是:
训练的Batch就是普通的Memory+New,但是值得一提的是,这篇文章对Memory的数据选取做了消融实验,得到了这样的结果:
随机选取Memory的效果>GSS(NIPS2019)和ASER(AAAI2021),是一个令人惊讶的结果.
而类似的,也有使用图像旋转的SSL(缓解ce带来的特征bias)+CE结合Prototype(rehearsal避免遗忘)+ KDLoss的研究[14],证明了结合类似的自监督任务能够有效缓解特征之间的重叠。
使用的SSL任务是常见的Rotate Loss, KD是和上一轮的模型做约束。

同样的C2OL[15] 这篇方法,就用最基本的对比学习的损失来研究该方法对于IL的实用性,也发现了基于CL学出来的特征确实更适合用在蒸馏的任务之上,验证了我们的猜想。
优化损失设计
《PODNet Pooled Outputs Distillation for Small-Tasks Incremental Learning》基于样本回放的方法,改进 KD,定义了 Pooled Output Distillation。
- spatial-based distillation-loss,基于空间的蒸馏损失,改进蒸馏方法
- representation comprising multiplt proxy vectors,代理向量改进了分类器
==part1 Update KD Loss==

假设:$\hat{y} = g(f(x))$ 为分类过程,其中$f(x)$ 代表特征提取过程。
POD 算法则为,不仅将蒸馏应用到特征提取的最终输出,还将其用于$f(x)$的中间过程的输出
中的每一层(如下式)都作为中间的结果,用来做 KD,上标 t 表示 task,下标则表示模型第几层。
对该输出的各层执行各种级别的 POD 蒸馏,作为我们的监督来实现对灾难性遗忘的避免:
显然 pixel 级别对于模型的约束是最强的
pixel 级别的蒸馏对于模型限制比较严格,其他级别的对于模型限制相对较松,需要一个权衡,作者最终选用的是 Spatial 级别的蒸馏,相当于 width 和 height 层面蒸馏 loss 之和
特征提取模型最终的特征则使用 pixel 级别的蒸馏:
将这些蒸馏损失整合起来取代原本的 KD-Loss,再加上我们的 CE 即可:
==Part2 Local Similarity Classifier==
第一个改进点就是将 Loss 修正为 Cosine 的形式UCiR,实际上就是使用的归一化后的 FC 层,但是如果只使用一个 Cos 相似度,好像多样化的需求无法满足,需要类似一个多头的机制
和 LT 的地方一样,IL 近年来的主要架构也是两部分进行分离的,所以我们可以考虑从我们的角度来实现类似 POD-Loss 的架构维持,也就是一定程度上为我们的 SSL-SCL 架构的可行性提供了一定的信心。
该方法迄今为止还是很多增量任务的榜单前几,该方法的蒸馏性能也被验证为有效,但是实际上将该方法用于模型中需要增加大量的特征输出模块,整体架构上修改起来可能会较为复杂。
基于模型结构的方法
这一部分不是我研究的重点,可以看到有一部分设计的拓张模型或者,堆叠模型,用额外的结构来承载对应的新类的研究,可能考虑到一部分参数公用然后实行协同判断的策略把。
或者是其他的图模型,拓扑结构(神经气体网络)等等的方法,拓扑结构等方法可能户籍是未来的一个方向。
特征网络堆叠
- DER 特征网络堆叠的方法
其他方法
- EWC :这类方法一般是对网络中每个参数的重要性进行评估,根据每个参数的重要性,调整梯度信息更新参数。
-
其他问题
这里会收集一部分 IL 中存在的一些现象或者问题
新类优于旧类
模型倾向于时间上接近的模型有更高的敏感度,这可能是训练的过程决定的,也可能是由于再新类的训练上新类的权重要明显高于旧类,导致的某种数据不均衡的现象。
此外在传统的设定中,新类的数据量会大大的大于旧类
Few-Shot Incremental
Few-Shot 的增量情景更贴切于我的场景假设,在这种假设的背景之下,增量学习也会面临一些新的困难,这个篇章中我们可能会简要的总结一些方法对抗小样本和灾难性遗忘的思路和策略。
- 小样本的类别原型不稳定
- 容易和旧类别混淆
在进行总结的同时,我们的调研方向也会有所侧重,比如基于拓扑的神经气体网络方法,我们可能暂时不那么关心(精力有限)

拓扑结构方法
- 《Few-Shot Class-Incremental Learning》[10]
SPPR
《Self-Promoted Prototype Refinement for Few-Shot Class-Incremental Learning》这篇文章的主要贡献有以下的两点:
- 提出了 RESS(随机 episode 选择策略)通过强制特征自适应于各种随机模拟的增量过程来增强特征表示的可扩展性。
- 引入了一种自提升的原型细化机制(SPPR),利用新类样本和旧类 prototype 表示之间的关系矩阵来更新现有的 prototypical
RESS 实际上应该是类比 Meta Learning 提出的一种训练策略
SPPR 是本文的核心,为了保持旧类之间的依赖和新类置假你都区分度,要对新类的原型进行提炼
理论上讲 SPPR 更新的应该是模型的参数,但是在代码中我暂时没有找到对应的实现的地方
so we drop this method which is not match our structure
Evolved classifier
由于数据量少的这个特点,我们解耦 BB 和 CLF,每次增量任务只更新分类器。
该文章[12]在多个数据集上实现了 SOTA,提出了 CEC(Continually Evolved Classifier),将图模型用在分类器上,它的分类器是一个无参数的 class mean classifier(听起来像 NCM);

实际上就是在一个较优的特征空间的基础上调整我们的决策边界的一个策略,该方法引入了图注意力模型(GAT),该方法有一个特性是:
- 增加节点而不改变其他的节点,
- 利用拓扑关系,链接关系的不变性,利于保留旧知识
使用 GAT 获得线性变换矩阵和注意力系数来更新模型的权重。
此外提供了一种旋转增强的新型策略,效果特别好==pseudo incremental learning==,可能和 GAT 的一些特性有关,结合 GAT 效果提升巨大,要警惕这种方法是通用的还是特异性的。最好是看看有没有原理分析。
CEBN
采用三阶段的方式来实现小样本的增量学习,根据上述的任务划分图来确定不同的实验阶段:
- 用大量数据训练基准的分类模型,使用的就是 base class
- 学习 novel class 防止灾难性遗忘,只使用新类数据(修正 CE 考虑小样本问题)(使用参数来正则防止 BB 灾难遗忘)
- 混合数据进行训练,这个时候使用一个 balance 的数据集,比如说做多次增量的话,在最后一次使用 balance replay 即可。
第二阶段的损失是这里的关键,基于 CEBN 修改 CE,为啥我看不出区别,我感觉实际上就是 CE,只是虽然只用新数据训练,但是分类器是完整的罢了,其实就是 CE:
正则项则通过对前后的 Backbone 进行约束得到:
最终整合起来的损失如下:
References
📚Awesom Incremental Learning Collections | 🌤️Paper w Code Incremental Learning
- Learning without Forgetting | ZHIHU | ECCV2016
- iCaRL Incremental Classifier and Representation Learning | CnBlog , ZhiHu | CVPR2017
- Ene-to-End Incremental Learning | ECCV2018
- ⭐ PODNet Pooled Outputs Distillation for Small-Tasks Incremental Learning | ECCV2020 | CSDN
- Large Sacale Incremental Learning | CVPR2019 | CSDN
- Learning a Unified Classifier Incrementally via Rebalancing | CVPR2019 |
- Maintaining discrimination and fairness in class incremental learning | CVPR2020
- Rainbow Memory: Continual Learning with a Memory of Diverse Samples | CVPR2021 | CSDN
- Supervised Contrastive Replay: Revisiting the Nearest Class Mean Classifier in Online Class-Incremental Continual Learning | CVPR2021 | CSDN
- Few-Shot Class-Incremental Learning | CVPR2020 | CSDN
- Self-Promoted Prototype Refinement for Few-Shot Class-Incremental Learning | CVPR2021 | CSDN
- Few Shot Incremental Learning with Continually Evolved Classifiers | CVPR2021 |
- Generalized and Incremental Few-Shot Learning by Explicit Learning and Calibration without Forgetting | ICCV2021 | CSDN
- Prototype Augmentation and Self-Supervision for Incremental Learning | CVPR2021 | ZHIHU
- Contrastive Continual Learning | ICCV2022 | CSDN
一些总结笔记
- Classic Incremental Papers
- Background and Dilemma
- Online Continual Learning An Empirical Survey | 2021 | Notion 这篇综述给人的感觉比较一般把,或者可能是总结文档里没有写出比较关键的一些看法和证据。感觉不是特别推荐阅读。
- Incremental Learning in 20-21 | 下面的图也来自这篇文章



to be placed in the right place
将一些新的研究先放在这里,到时候看看要组织到笔记的那一部分。
class-Incremental learning via Dual Augmentation
该文章认为,类增量学习中灾难性遗忘可以被总结为两个方面带来的:特征表示上的偏差和分类器上的偏差。
- 增量过程中如果不对特征提取器进行适应,则对新特征的提取能力不够;如果进行适应则会产生灾难性的遗忘
- 分类器如果不进行更新,会和新的特征表示不适应,而由于没有旧类的数据,就没有更新旧类的方向
解决的思路是:
- 训练的阶段做mixup来做混合类的学习,通过这种预先训练,来帮助模型得到一个较为稳定的表征。
- 分类上将历史数据的均值和方差记录下来,对模型更新的时候,通过分布信息生成语义特征维持决策边界,防止对旧类分成新类。
第二部分具体细节的实现上还不是很清晰,后续可以看代码,但是目前来看不是我们需要的。
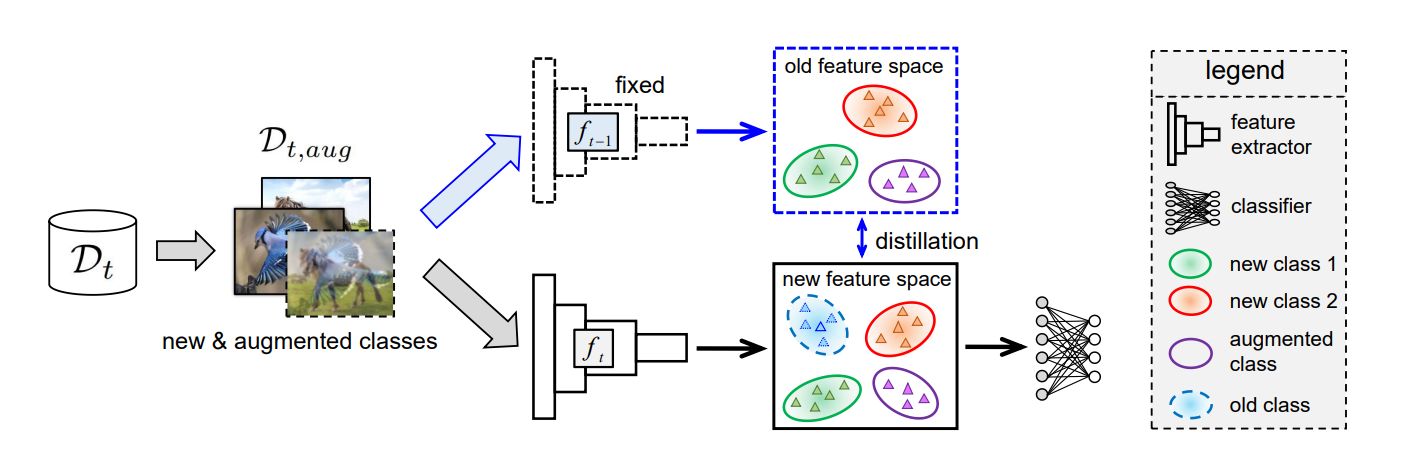
Looking back on learned experiences for class/task incremental learning
主要贡献:无数据的增量学习,支持经验重放,不需要平行网络输出蒸馏监督。
kd使用的是最小欧拉距离:L2范数的平方作为损失。
Overcoming Catastrophic Forgetting in Incremental Few-Shot Learning by Finding Flat Minima
在基础模型训练阶段,企图找到一个损失的下降平坦点而不是简单的一个极小值,平坦极小值的模型的鲁棒性能会比普通的模型优异一些,具体对于平坦点的定义可以参见下面的这张图:
这种平坦点的研究,实际上和NotZeroLoss的设定具有相当的相似性,帮助模型学习到一个更加稳定的解,而该解在后续进行增量学习的过程中,会减少对应的灾难性遗忘的现象。
Distilling causal effect of data in class-incremental learning
也是通过因果分析来筹建分类结果,通过TDE的方式消除类别偏差,这一部分实际上和我们的Causal模块和统计均值模块应该是起到了相同的作用,这里暂时不深入进行解读。
==the two below== is important for our research:
Do not Forget to Attend to Uncertainty while Mitigating Catastrophic Forgetting
Papers using attention and the bayes formula to calculate the Uncertainty or something else.
Continual Learning in the Teacher-Student Setup: Impact of Task Similarity
Papers do a lot for the loss, which we should pay attention for it.
IL Collection



