
MIM-V-simMIM
@Author: MSRA Zhenda Xie
@Source:Arxiv, Code TBP,Blog_CVer
@Read:AikenHong 2021.11.22
“What I cannot create, I do not understand.” — Richard Feynman
Intro & Simple Conclusion
Conclusion
继MAE和iBoT之后,MSRA也提出了一个图像掩码建模的新框架,SimMIM,该方法简化了最近这些提出的方法,不需要特殊设计,作者也验证了不需要那些特殊设计就已经能让模型展现出优秀的学习能力
- 采用中等大小的掩码块(32),对输入图像进行随机掩码,能使其成为强大的代理任务(pretext task)
- 直接回归预测原始像素的RGB值的效果并不比复杂设计的Patch分类方法差
- Projector Head可以是轻量的Linear Layer,效果并不一定比MLP(多层)的差
Motivation
通过这种MIM方法可以实现在大量无标注的数据上得到一个表征能力up的通用特征模型,这种方式的backbone可以广泛的应用到图像上的各种子任务中(按照NLP)的经验来说,而为了类似的方式在图像上的大放异彩,我们首先需要分析Vision和Language的不同
- 图像有更强的局部关系:相互靠近的像素是高度相关和近似的,我们可以通过简单的copy padding复制一部分缺失
- 视觉信号是原始,低层次的,而文本分词是高级概念:对低层次信号的预测是否对高层次的视觉识别任务有用呢?
- 视觉信号是连续的,而文本的分词是离散的: 如何基于分类的掩码语言建模方法来处理连续的视觉信号
Theoretical Design
掩码选择:同样的掩码的策略还是基于Patch进行的,对于掩码的设计来说,太大的掩码快或者太密集的掩码快,可能会导致找不到附近的像素来预测,实验证明32是一个具有竞争力的size,和文本任务的信息冗余程度不同也带来了覆盖比的选择,NLP通常是0.15,而在V中,32size可以支持0.1-0.7的覆盖率。
任务选择:使用原始像素的回归任务,因为回归任务和具有有序性的视觉信号的连续性很好的吻合。
预测头选择:使用轻量的预测头如(linear),迁移性能与繁琐的预测头相似或者略好,同时训练上更加的块。虽然较大的头或更高的分辨率通常会导致更强的生成能力,但这种更强的能力不一定有利于下游的微调任务。
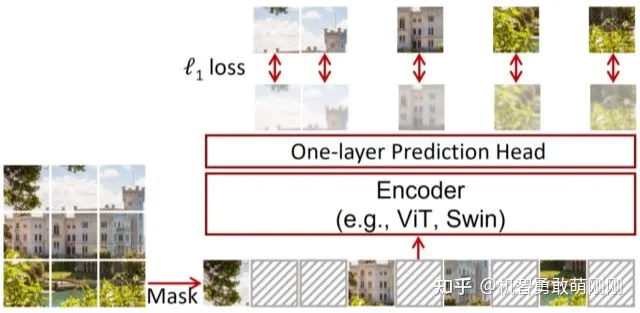
Structure Design
SimMIM方法就是掩码表示学习,实际上就是掩码图像然后预测原始信号,主要的组成部分、
- Masking Strategy,选择图像掩码掩码区域,并实现掩码,将掩码后的图像作为图像的模型输入
- Encoder Architecture, 提取特征表示,用来预测原始信号,主要采用
vanilla VIT和Swin Transformer - Prediction Head,用于预测潜在的特征表示,表示掩码区域中的原始信号
- Prediction target,定义了要预测的原始信号的形式,可以是原始像素值也有可以是元素像素变换。同时定义了损失:分类
ce,回归l1,l2
Masking
使用可学习的mask token vector代替每个掩码区域,这个token向量的维度和其他的可见patch,经过patch embedding后的维数相同,主要测试了以下的几种策略:

Projector Head
形式和大小任意,只要输入和编码器的输入是一致的,其输出达到预期目标即可,只是本文的作者证明了预测头可以做成轻量的单层线性层。
也测试过2layers-MLP,inverse Swin-T/B
Projector Targets
原始像素之回归,一般情况下视觉框架生成下采样分辨率的特征图,ViT为16*其他架构为32*
为了预测输入图像全分辨率下的所有像素值,
将feature map中的每个特征向量映射回原始分辨率,并让该向量负责相应的原始像素的预测
例如,对于Swin Transformer编码器生成的32×下采样的feature map,作者使用输出维数为3072 = 32×32×3的1×1卷积(线性)层来表示32×32像素的RGB值。对原始图像分别进行{32×, 16×, 8×, 4×, 2×}下采样,考虑分辨率较低的目标。
在掩码像素上使用L1-Loss,

- 可以使用其他的预测目标:
- Color clustering. 在iGPT中,利用大量自然图像,通过k-means将RGB值分成512个簇。然后每个像素被分配到最近的簇中心。这种方法需要一个额外的聚类步骤来生成9位调色板。在实验中,作者使用了在iGPT中学习到的512簇中心。
- Vision tokenization. 在BEiT中,采用离散VAE (dVAE)网络将图像patch转换为dVAE tokens。token可用作为分类目标。在这种方法中,需要预训练一个额外的dVAE网络。
- Channel-wise bin color discretization. 将R、G、B通道分别进行分类,每个通道离散为相同的bins,例如实验中使用的8和256 bins。在·
MIM-V-simMIM



