
OW-openmix
@Aiken 2021 究极万恶的撞车论文
Intro
Motivation :Tackle the problem of 发现无标注数据中与给定(已知)类别不相交的新类。
Related Research:
现有的方法通常1. 使用标记数据对模型进行预训练; 2. 无监督聚类在未标记的数据中识别新的类
作者认为label带来的essential knowledge在第二步中没有被充分学习利用到,这样模型就只能从第一步的现成知识中获益,而不能利用标记数据和未标记数据之间的潜在关系
Hypothesis:
有标记的类别和无标记的类别之间没有Overlap,这样导致在两个类别之间很难建立学习关系,(为啥我感觉这个说的都是屁话)
Solution:
Openmix:将标注的数据和未标注的数据同时混合起来得到一个联合标签的分布中,用两种方式来动态合成示例:
- 我们混合标记和未标记数据作为Training Img,混合了已知类别的先验生成的伪标签会比无监督情况下生成的伪标签跟家的可靠?防止在错误的伪标签前提下发生过拟合
- 在第一步的时候我们鼓励具有高类别置信度的无标记example作为可考虑的类别,然后我们将这些samples作为anchor,并将它们进一步的和无标注的samples整合,这使得我们能够对无标注数据产生更多的组合,并发现更精细的新类关系。
Detail
果然在混合的方式上和MixUp的策略进行比对了,就是diss了Mixup使用伪标签的情景可能会进一步的引入不确定性,导致算法的效果反向优化,就是再label和unlabeled数据上混用mixup,而不是单纯的对unlabel数据集进行混合。
首先将没有overlap的标签表现为联合标签分布再进行混合,也就是加长onehot,这样的标签的优越性在?对于unlabelled data引入了确定性,防止标签容易过拟合。也就是给伪标签加入了一个锚定,让他能够变化的更平滑

这尼玛这张图看了不久完事了,bibi一大堆啥的呢。主要分析一下三个损失函数代表的是什么意思。
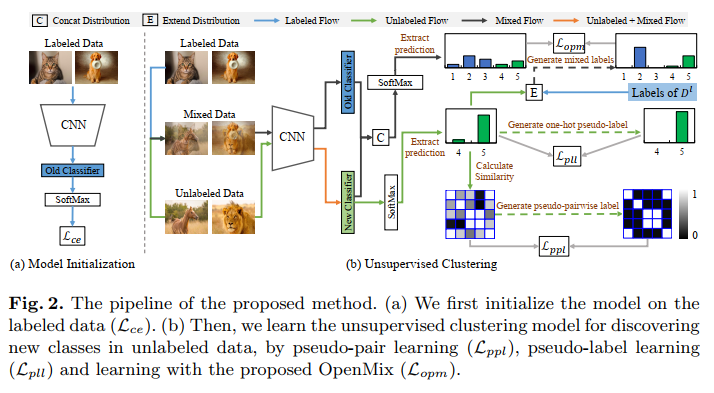

对其中的$L_{ppl}$进行特殊的说明:
- 由于输入的是pair,所以添加的一个损失也就是分类是否属于同一类,二分类ce
- 使用的是cos similarity,通过threshold 来判断是否是同一类,
- 实际上应该也是一个预训练的模块,在实际进行的过程中由于是对无标注数据进行处理,讲道理是无法计算损失的,也没有开源代码。
异同点分析
初步分析结果:
- 不使用无监督聚类的方法对新类进行发现,而是使用其他的策略
- 好像没有使用增量学习的方法进行class-incremental的增量处理,主要的motivation好像是Discovering,并没有Incremental的部分
- 新数据的组合方式是怎么样的这点好像值得研究一下
OW-openmix



