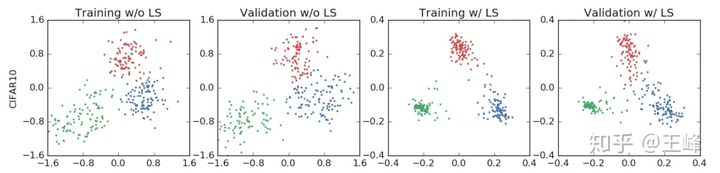
Loss-NCE
@AikenHong 2021
Noise Contrastive Estimation Loss = NCE Loss 噪声对比估计损失,这里的Noise实际上就是Negative Samples.
该损失被广泛的用于对比学习的任务,而对比学习广泛的作为自监督学习的无监督子任务用来训练一个良好的特征提取器,于是对于对比学习的目标和效用的理解十分关键。
What’s NCE Loss
在介绍NCE之前我们可以将其和CE进行一个简单的对比,虽然名称上不是同一个CE,但是在数学表达上却有很相近的地方(softmax-kind of loss)
首先softmax,他保证所有的值加起来为一,结合onehot的ce,实际上j==gt的情况下外层+log也就是ceLoss,也就是 $logSoftmax$
然后看infoNCE,基础的对比学习损失可以写成:
其中 $f_x^T f_y^T$ 为 $sim(x,y)$ 时即转化为带$T$的NCE,即InforNCE.
分子是正例对的相似度,分母是正例对+所有负例对的相似度,最小化infoNCE loss,就是去最大化分子的同时最小化分母,也就是最大化正例对的相似度,最小化负例对的相似度。
从该形式上看,和soft的CE形式上是统一的,当我们把分母看作概率和自身以及和其他的相似性,这样和NCE在形式上和简化后的CE实现了统一。
但是我不认为这和label smooth 后的CE有相关性,而是和原始的CE经由One-hot简化后结构上有相似性。
How it Works
NCE的思想是拉近相似的样本,推开不相近的样本,从而学习到一个好的语义表示空间,这一点上实际上和度量学习的思想是一样的,只是对比学习通常作用在无监督或者自监督的语境中,度量学习这是有监督的。
考虑之前人脸匹配的研究,使用 “Alignment and Uniformity on the Hypersphere”中的Alignment and Uniformity,就是一个更好理解他的角度