
Loss-WhyZero
Loss :Why Zero Loss?
@Comments: ICML2020 《Do We Need Zero Training Loss After Achieving Zero Training Error》
@Noteby:AikenHong2021
如何解决训练损失下降,但是验证损失上升的问题(过拟合like)的问题,该文章实际上可以作为我们损失设计中的一个trick,只需要简单的一行代码,来提升代码的泛化能力;
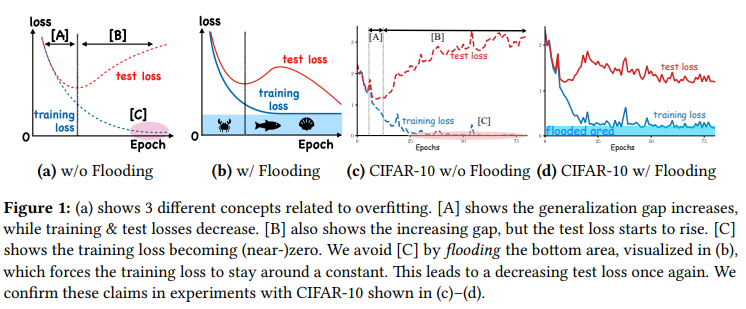
这张图体现了本文的灵魂(思路),主要体现在我们在算法趋于稳定后继续训练可能验证损失会反而上升;
所以本文提出了一种flooding方法,当我们training loss 大于阈值的时候我们使其正常下降,当低于阈值的时候,flooding的设计会反过来使得梯度上升,让训练损失保持在flooding附近,让模型持续进行random walk,希望模型最终能优化到一个平坦的损失区域,这样发现test loss进一步的进行下降。
理解:
当我们的训练损失低到一定的程度,然后随着lr的下降,模型会很难跳出当前的极小值,这种情况下我们的泛化能力也会被限制住,采用这种方法在牺牲测试精度的同时能提升算法的泛化能力。
损失公式表示如下
具体的代码表示只需要添加一层:
1 | |
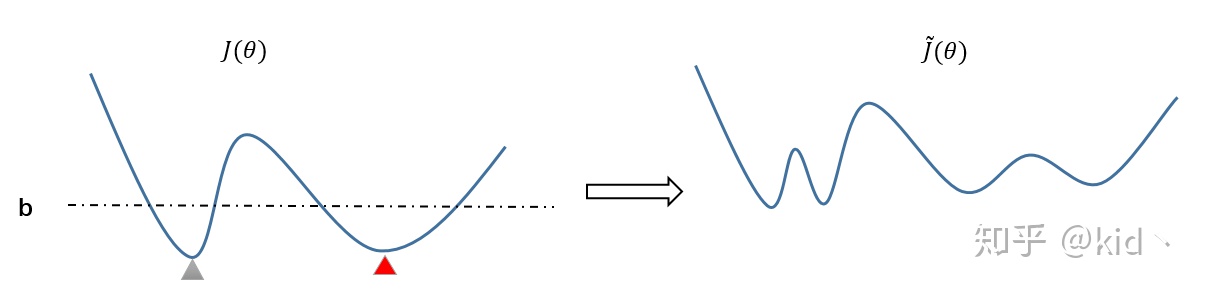
损失中怎么设置b值
摘自知乎回答,我觉得这种方式说好也好,说不好也不好,算是一种治标不治本的trick把,通过这种方式可以勉强缓解那种代码陷入极小值无法调整的情况,但是实际上算法原理并不是一个很solid的
看了下评论,不少人关心b值应该如何设置,首先论文给出说法是b做为超参数需要在一定范围内遍历选优,对于b得取值范围文中也仅有一个限定是:b值要小于测试损失,这个范围显然太宽泛了。也有人说应该在Validation Error 开始上升的时候,设置b值在此附近,进行flooding,因为此处说明已经开始过拟合,避免在错误方向上渐行渐远。个人觉得有道理,但是在自己的本地任务上尝试下来发现,通常来说b值需要设置成比”Validation Error 开始上升”的值更小,1/2处甚至更小,结果更优;想下来原因应该是:Validation Error开始上升的原因不仅仅使说明过拟合情况的发生,还有可能是验证机和训练集不满足独立同分布(这种情况更见),当原因是后者时,往往需要沿着梯度下降方向继续学习,也是解释通了实际使用种为何b值要设置的更小。
和参数正则化之间的差异在哪里。
Loss-WhyZero



