并行训练
How to Train Really Large Models on Many GPUs? (lilianweng.github.io)
对于浮点运算,模型参数的存储和中间计算输出(梯度和优化器状态)的存储的在 GPU 内存上的大量需求使得我们需要并行化,下面我们参考一些常用的并行化范式:
数据并行策略:
在Multi-GPUs上Duplicate模型,然后分别feed数据,进行运算,每个batch同步或者异步的进行多卡间的梯度传递和模型同步。
同步可能会导致每个batch需要停止训练,异步则是可能会使用陈旧的梯度进行一段时间的训练,增加了计算时间。
而在PT1.5以来,使用一种中间的方式:每隔x次迭代,进行多卡间的全局同步梯度一次,使用这种梯度积累的策略,根据计算图来进行计算和通信调度的优化,提高吞吐量。
模型并行范式:
是为了解决单模型过大无法存储在单一的Node上的问题,但是这样会有GPU间的顺序依赖,虽然减少了内存的占用和计算量,但是这种IO的需求导致计算资源的利用率严重不足。
在这种pipeline中,就存在利用率的bubble,也就是空白的部分
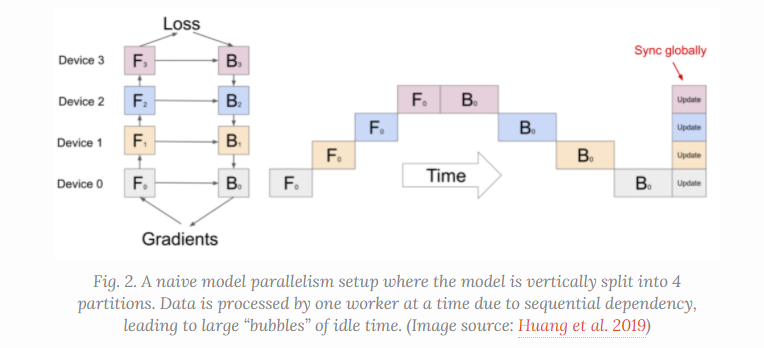
Pipeline并行策略:
混合模型和数据并行的策略,来减少低效时间的泡沫,也就是,将一个batch切分成多个小batch,然后分发到每个node上,减少相应的等待时间,只要我们对计算量和运行速度有合理的把握,就能极大的降低这个inefficient time bubbles. 多个mini-batch的梯度聚集起来最后同步更新. 最有情况下甚至可以忽略气泡的开销
m个mini-batch和d个分布, bubble的比例将如上述所示
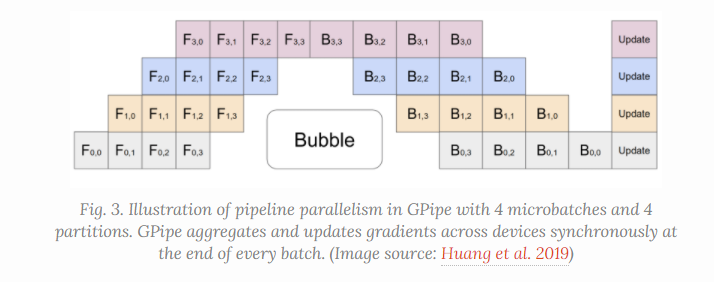
这种方式能实现吞吐量和设备数量的几乎线性加速, 但是如果参数模型不能均匀的分布的话, 她并不总是能保证.
pipedream下面的这种方法, 虽然没有在最后进行全局的梯度同步, 可能会有之前提到的异步并行的问题, 使用不同的模型权重, 但作者也提出了一些相应的解决方案, 包括权重存储和垂直同步等等方法.
详细的需要的时候对原文进行参考.
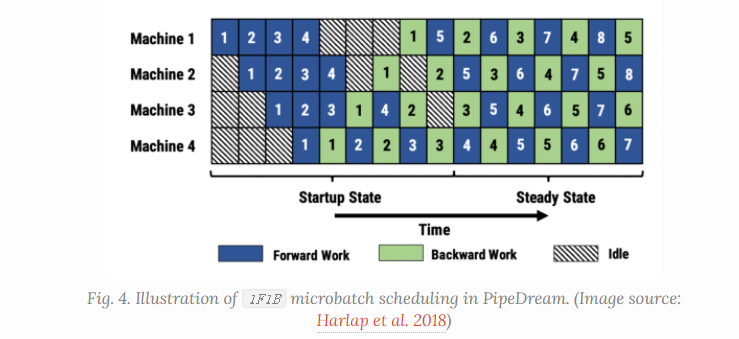
后续还有两个对其的不同设置的改进*PipeDream-flush* | *PipeDream-2BW*
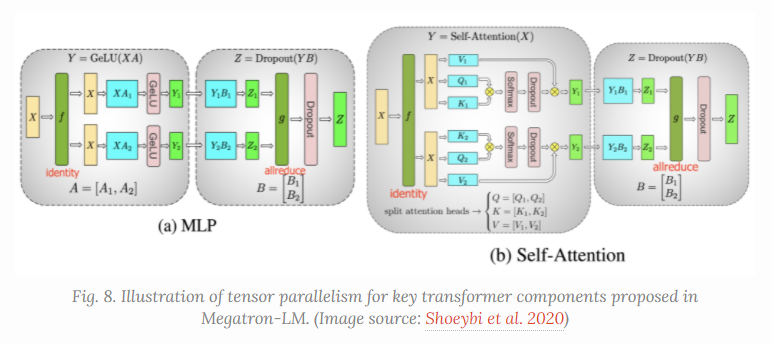
Tensor并行范式
前面都是纵向的对模型进行切割, Tensor并行是横向的对Tenosr以及相应的矩阵运算进行切割.
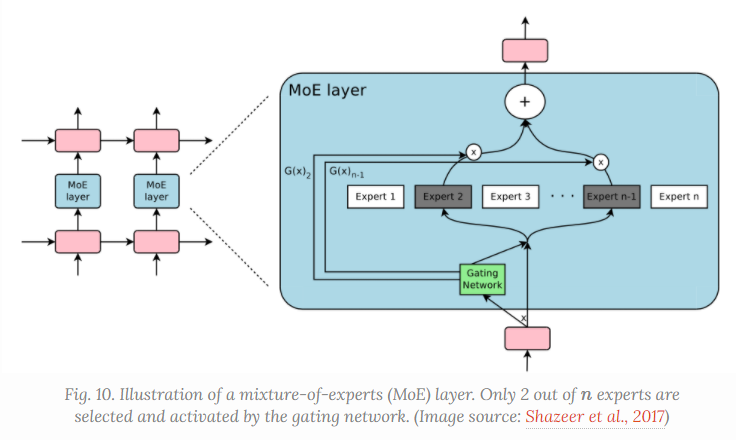
Mixture of Experts
结合弱监督学习器来得到一个强学习器, 采用一个专家门控机制来实现, 用一个门控网络G来学习n个专家的概率分布, 将网络的流量导向对应的专家
Other Memory Saving Designs
- CPU offloading: 异步的将一些GPU存不下的放到cpu上, 但以不影响Training Process为基准
- Mixed Precision Training: 混合精度训练, 实际上应该就是APEX采用的策略.



