
OW Object Detector
@Aiken 2021
框架撞车系列,主要看看这一篇论文中怎么解决如下的问题👇,并从中借鉴和优化的我框架设计
思路分析
Motivation
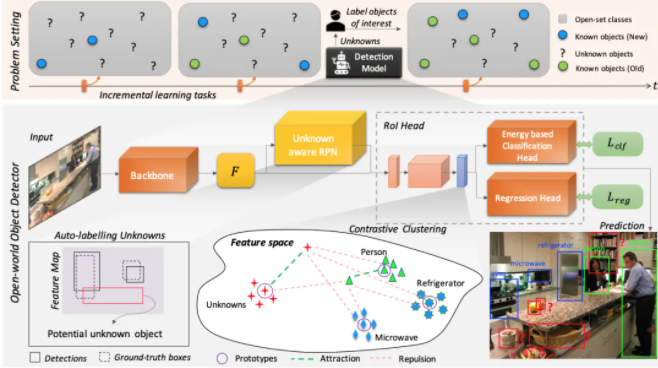
模型实现的主要的两个TASK:
- Open Set Learning : 在没有明确监督的时候,将尚未引入的目标类别识别为未知
- Incremental Learning:类别增量学习
实现这两个问题的主要思路:
- 自动标注:借鉴RPN的class-agnostic,以及检测和分类的显著性指标的差异,找到并自动标注NewClass
- 对比聚类:使用prototype feature来进行聚类,同时计算Distance损失
it seems like contain a unknown prototype. - energy based:亥姆霍兹自由能公式?
ENERGY BASED
Feature:$F$, Label: $L$ , Energy:$E(F,l)$
能量函数倾向于将已知的类别分类到低熵的分布上,然后我们可以根据特征在能量空间上的划分来区分新类和旧类。然后我们可以根据logits表达的softmax形式,找到输出和Gibbs distribution的相关性:
通过这个相关性,我们对自由能进行一个定义,以logits的形式表达
g实际上表示特征最后输出的logits,通过能量的映射函数,我们将聚类转移到能量域上做,置信度较高的类别和未知的新类实际上有一个比较明显区分的分界线。
实际上我觉得就是类似熵的形式,在本文中将softmax的形式和gibis自由能做了一个对比,然后相当于对logits映射到了能量的维度去做特征的对比聚类,同时也能看出,在能量这个隐层空间中,在能级上能对已知类别和未知类别之间有一个明显的区分,所以在能级上进行划分是一个比较合理的空间映射形式。
Alleviating Forgetting
参数正则化方法:exemplar replay:动态扩张网络;元学习
增量学习中提到的一些贪婪的参数选择策略好像对SOTA的方法都有很大的优势;后续又有人发现存储少量的示例和replay的有效性在相关的Few-Shot Detect中式有效的。
本文采用相对简单的ORE方法来减缓灾难性遗忘的问题,也就是说存放了一组平衡的范例,在每个增量步骤后对模型进行微调,确保每个类最少有$N_{ex}$个示例出现在例子集中。
实际上说的就是每次增量学习之后都会进行数据集的混合然后朝着原本的方向进行一定的微调;好像也没有什么特别的把,具体的实现可能要参见代码。
Workflow
我认为是通过RPN和class-aware之间的插值直接直接标注的一个未知的类别,然后在后续直接让人类区标注感兴趣的样本,可能是从少到多的,并没有一个特定的POOL,原本的模型可能有预留的Unknown Class或者说是相应的预留输出节点,然后在获得新的数据标注之后,进行更新模型的训练,然后使用避免灾难性遗忘的策略去做,从而使得模型对新的类别存在认知,也不会忘记旧的类别的知识。
OW Object Detector



