
OWL-survey
@AikenHong2021 OWL
分析现有的OWL特点,和当前自己的研究做一个区分,也汲取一下别人的研究的要点,
Reference
- arxiv @ self-supervised feature improve open-world learning
- arxiv @ open-world semi-supervised learning
- arxiv @ open-world learning without labels
- arxiv @ unseen class discovery in open-world classification
- arxiv @ Open-World Active Learning with Stacking Ensemble for Self-Driving Cars
- www @ open-world learning and application to product classification
- cvpr @ open world composition zero-shot learning
- cvpr @ Towards Open World Object Detection
- cvpr](https://openaccess.thecvf.com/content_CVPR_2019/papers/Liu_Large-Scale_Long-Tailed_Recognition_in_an_Open_World_CVPR_2019_paper.pdf)) @ Large-Scale Long-Tailed Recognition in an Open World
Conclusion
Papers
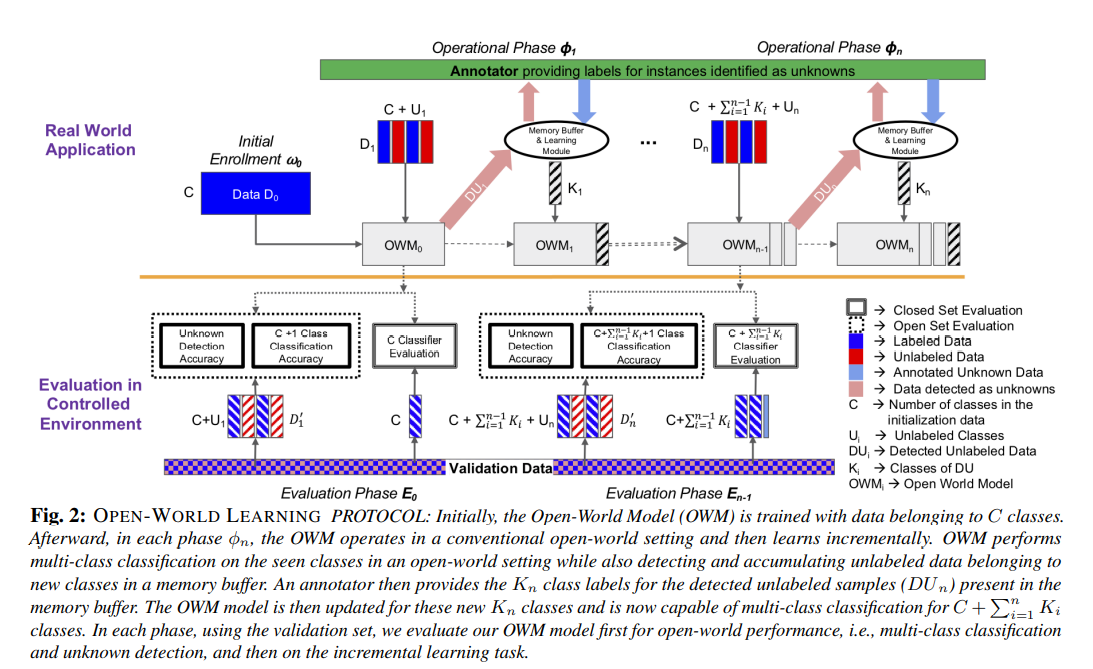
Mulit Open world Learning Definition
拒绝未见过的类的实例,逐步学习新的类扩展现有模型
:zap: Large-Scale Long-Tailed Recognition in an Open World
Large-Scale Long-Tailed Recognition in an Open World (liuziwei7.github.io)
这篇文章很可能作为后续我们比较的baseline,通过对这篇文章的数据和代码复用和同等环境下的处理,来进行算法优劣的比较。但是实际上该论文的定位和我们也并非完全相同,因为改论文将开放世界的类别识别为未知类,主要的问题是如何避免将未知类别分类到少样本类别中。
我们希望将开放类作为新类别数据处理(Few-Shot),增加了Incremental的部分,这是他们论文中缺少的一部分,同时这篇论文的思路面向的任务是识别而不是分类,他们在识别上的信息实际上是更完善的,但是对于分类任务来说,如果不基于相应的标签先验,实际上容易带来问题。

使用动态元嵌入的策略来结合两个部分处理尾部识别的鲁棒性:
- 从输入图像计算得到直接特征(这一方面上FS的类别缺乏足够的监督)
- 视觉记忆相关的诱导特征(来源于基于memory的meta-learning),这种特征(visual-memory)具有直接的判别中心,学习一种方法从直接的特征中学到相关的记忆摘要,通过这种meta-embedding来处理尾部的类别。
我们的测试过程是否也可以看作管理一个Memory,通过对Memory的定时定量的Dynamic-Evaluation来做后续的Incremental Learning,通过这种策略来将整个框架整合起来,从最初的模型到后续的模型增量就能更好的结合在一起。
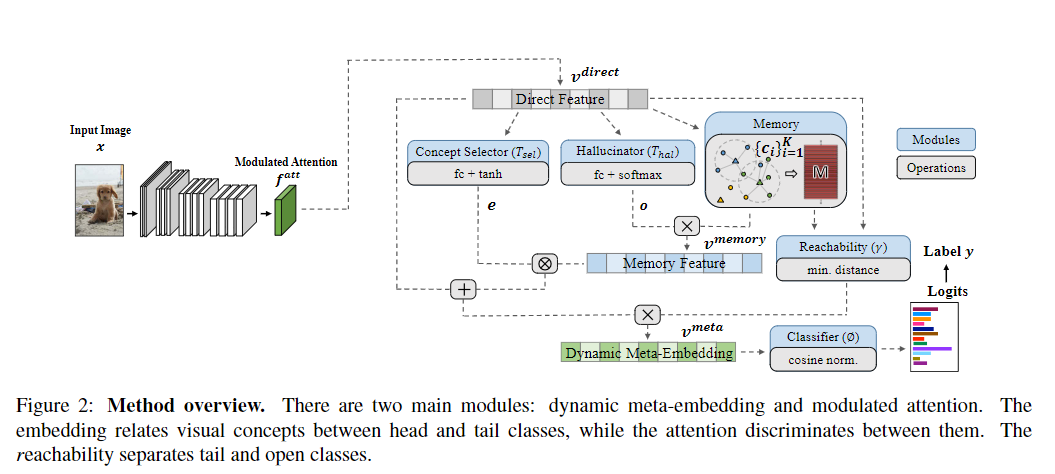
这个方法主要是在进行分类的同时维护一个嵌入图,通过对应的距离关系来计算类别的质心,来做作为另一个角度的特征,然后讲特征整合后作为最终的特征依据
:zap:Open-world Learning and Application to Product Classification
重点:该模型维护一组动态可见类,允许添加或删除新类,而无需重新训练模型。每个类由以小组训练示例表示,在测试中元分类器仅使用已维护的可见类,进行分类和拒绝。
基于metric进行判别和分类
实际上是一种prototype的方法,通过维护类别原型,使用metric的方法进行是否是已知类别的判断。
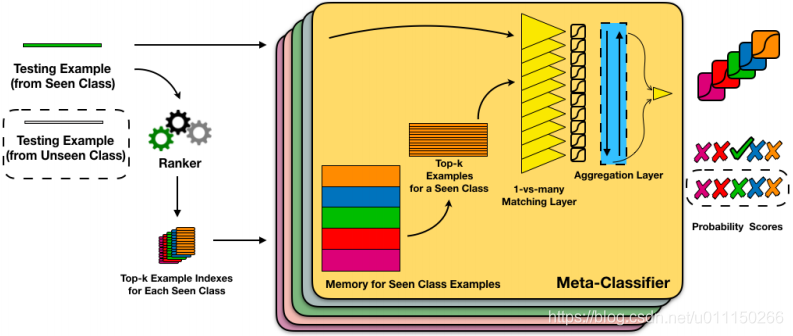
Ranker的作用是在每个已知类中抽取与一个测试样例的最近邻的k个已知类样例,然后将这些已知类的k个样例存入Meta-Classifier的Memory中。Meta-Classifier将测试样例与Memory中,经过Matching layer与Aggregation layer输出测试样例属于相应已知类的概率得分。
本文最大的新颖之处在于,在解决开集识别问题时,采用meta-learning的思想,训练集、测试集、验证机中的类别完全不相交。这样做的好处是模型具备增量学习的能力,当源源不断的unknown样例进行测试时,完全不必重新训练模型,提供了open-set classification一种新的模式。
:zap:TOWOO
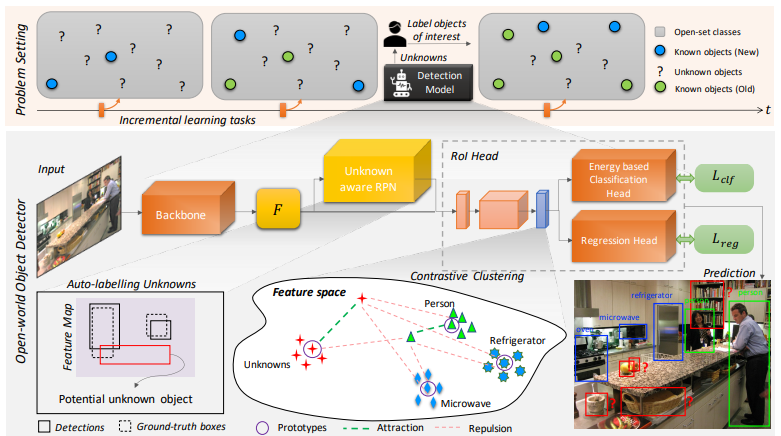
整体思路类似,聚类方法,标记出感兴趣的类别,然后加入数据库
1)将未识别的对象,识别为unknown
2)在逐步接受相应的标签的时候逐步学习这些未知类别,而不会忘记旧的类别。
使用contrastive cluster和energe-base的方法来对新类进行分类,主要的方法是通过将不确定的类别识别为未知类别。
未知类别识别方法(energe-base)
…
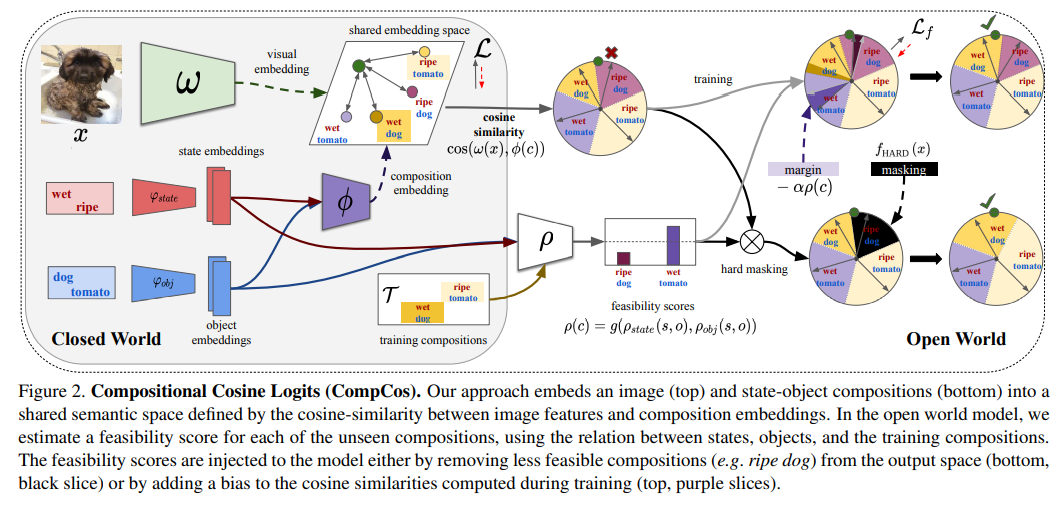
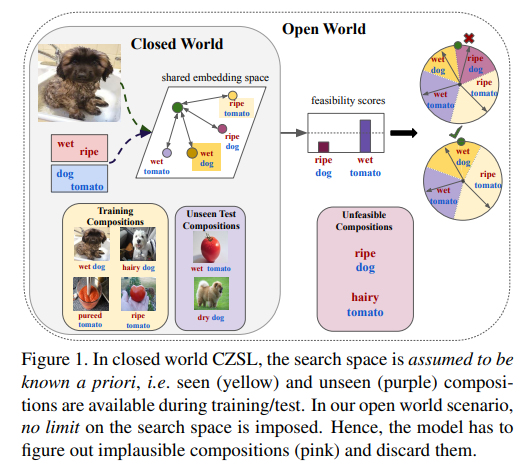
Open World Compositional Zero-Shot Learning
假设搜索空间是先验已知的,也就是存在几种类别是已知的,但是我们训练集中是没有未知类别的,共享特征空间,通过类似A-softmax的方式做匹配分析,通过在已知类别中落入的位置来判断是我们认定的已知类别还是未知类别。
Open World Semi-Supervised Learning
开放世界半监督学习,使用一种同时分类和聚类数据的方法 ORCA:
为了解决这个问题,本文提出了ORCA,一种学习同时分类和聚类数据的方法。ORCA将未标记数据集中的例子分类到以前见过的类中,或者通过将相似的例子组合在一起形成一个新的类。ORCA的关键思想是引入基于不确定性的自适应margin,有效地规避由可见类和新类/簇之间的方差不平衡引起的偏差。本文使用图像分类领域的三个常用数据集(CIFAR-10, CIFAR-100,ImageNet) 进行实验验证,结果表明,ORCA在已知类上的性能优于半监督方法,在新类上也优于新类发现方法。
Method
实际上就是使用半监督SimClr的backbone然后通过设定好的位置类别数目的分类器去做训练,但是这里的损失防止对已知类的偏向性。可以参考文章中的损失
基于对比学习方法SimCLR进行与训练
已知类的分类头用于将未标记的例子分配给已知类,而激活附加的分类头允许ORCA发现新类别。我们假设新类的数量是已知的,并将其作为算法的输入,这是聚类和新类发现方法的典型假设。如果不知道新类的数量,这在现实环境中是经常发生的情况,可以从数据中估计出来。在这种情况下,如果头的数量太多,那么ORCA将不会分配任何例子给一些头,所以这些头将永远不会激活,因此ORCA将自动修剪类的数量。我们在实验中进一步解决了这个问题。
related
了解决这种开放世界的问题,目前有2种思路:(1) OOD检测:能够识别已知类的数据,并且能够将所有未知类的数据检测出来,标为”unknown”。这种方法很好的保证了系统鲁棒性,但是无法充分利用未知类数据进行业务扩展;(2) novel class discovery(零样本,领域自适应问题): 利用源域标记数据来学习更丰富的语义表示,然后将学到的知识迁移到目标域(包含新类别),对目标域数据进行聚类。这种方法不能准确识别出已知类,只是对目标域做了聚类。
Self-Supervised Features Improve Open World Learning
特征提取:使用自监督学习来做特征提取器的训练
将新类发现作为特征空间中的位置标签,我们根据检测到的样本属于哪一个空间来做检测
和我的想法还是蛮贴近的,总之也是把新类的标签放置到存储区中,赋予伪标签的过程,然后微调特征提取器,基于后续的数据添加分类器的权重
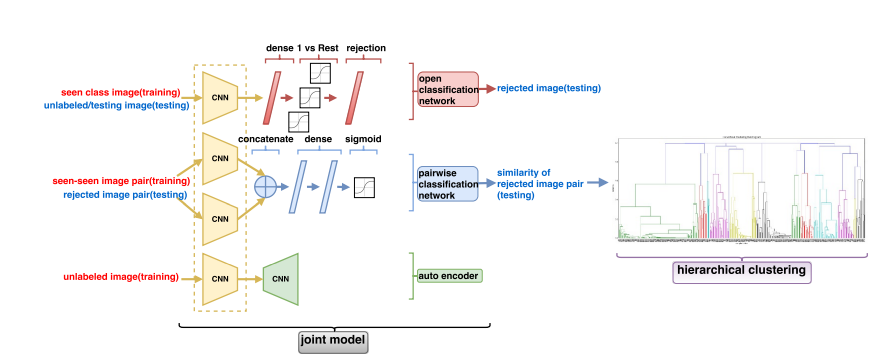
Unseen Class Discovery in Open-World Classification
通过对已知类别的学习,分析已知类别之间的距离差异;
本文的模型提出了一个contrasive模型,对实例属于同一类还是不同类进行分类,该子模型也可以作为聚类的距离函数.
OWL-survey



