
MIM-V-iBOT
@Read: AikenHong 2021
@Author: https://arxiv.org/abs/2111.07832
@解读:Machine Heart
基本思想
基于NLP中的MLM(Masked Language Model)的核心训练目标: 也就是遮住文本的一部分, 然后通过模型去预测和补全, 这一过程是模型学到泛化的特征, 使用这种方法来进行大规模的与训练范式.
在基本的思想上和MAE采用的是一样的设计, 但是本文中坐着认为visual tokenizer的设计才是其中的关键.
不同于 NLP 中 tokenization 通过离线的词频分析即可将语料编码为含高语义的分词,图像 patch 是连续分布的且存在大量冗余的底层细节信息。而作者认为一个能够提取图像 patch 中高层语义的 tokenizer 可帮助模型避免学习到冗余的这些细节信息。作者认为视觉的 tokenizer 应该具备两个属性:(a)具备完整表征连续图像内容的能力;(b) 像 NLP 中的 tokenizer 一样具备高层语义。
文中对tokenizer的设计为一个知识蒸馏的过程:
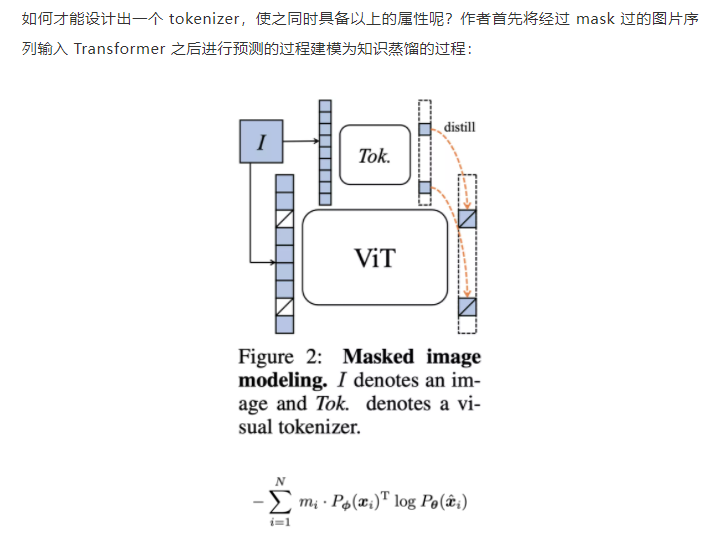
文中使用这种在线tokenizer同时来监督这样的MIM过程, 也就是两部分协同学习, 能够较好的保证语义的同时并将图像内容转化为连续的特征分布, 具体的, tokenizer和目标网络狗狗想网络结构, 有移动平均来得到实际的tokenizer.
该形式近期在 DINO [3]中以自蒸馏被提出,并被用以针对同一张图片的两个不同视野在 [CLS] 标签上的优化:
在该损失函数的基础上, MIM同样也是用这种自蒸馏的方式去优化, 其中在线tokenizer的参数为目标网络历史参数的平均.
基于上述的这些训练目标,提出了一种自监督预训练框架iBOT, 同时优化两种损失函数。
其中,在 [CLS] 标签上的自蒸馏保证了在线 tokenizer 学习到高语义特征,并将该语义迁移到 MIM 的优化过程中;而在 patch 标签上的自蒸馏则将在线 tokenizer 表征的 patch 连续分布作为目标监督 masked patch 的复原。该方法在保证模型学习到高语义特征的同时,通过 MIM 显式建模了图片的内部结构。同时,在线 tokenizer 与 MIM 目标可以一起端到端地学习,无需额外的 tokenizer 训练阶段。
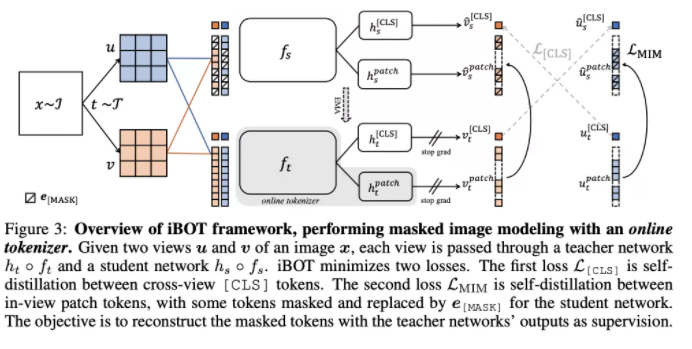
预训练时采用孪生网络结构,其中在线 tokenizer 可以看作教师分支的一部分。教师、学生两分支包括结构相同的 backbone 网络和 projection 网络。作者广泛验证了 iBOT 方法搭配不同的 Transformers 作为 backbone,如 Vision Transformers(ViT-S/16, ViT-B/16, ViT-L/16)及 Swin Transformers(Swin-T/7, Swin-T/14)。作者发现共享 [CLS] 标签与 patch 标签的 projection 网络能够有效提升模型在下游任务上的迁移性能。作者还采用了随机 MIM 的训练机制,对每张图片而言,以 0.5 的概率不进行 mask,以 0.5 的概率从 [0.1, 0.5] 区间随机选取一个比例进行 mask。实验表明随机 MIM 的机制对于使用了 multi-crop 数据增强的 iBOT 非常关键。
MIM-V-iBOT



