
Survey for Few-Shot Learning
@aikenhong 2020
@h.aiken.970@gmail.com
另一个综述文章:https://zhuanlan.zhihu.com/p/61215293
对该文中一些内容有一些补充,可以看看
FSL简介:https://blog.csdn.net/xhw205/article/details/79491649
GCN用于FSL:https://blog.csdn.net/qq_36022260/article/details/93753532
Abstract
FSL的根本目的就是弥合人工智能和人类之间的鸿沟,从少量带有监督信息的示例中学习。像人类一样有很高的泛化能力。这也能解决在实际应用场景中,数据难以收集或者大型数据难以建立的情景。
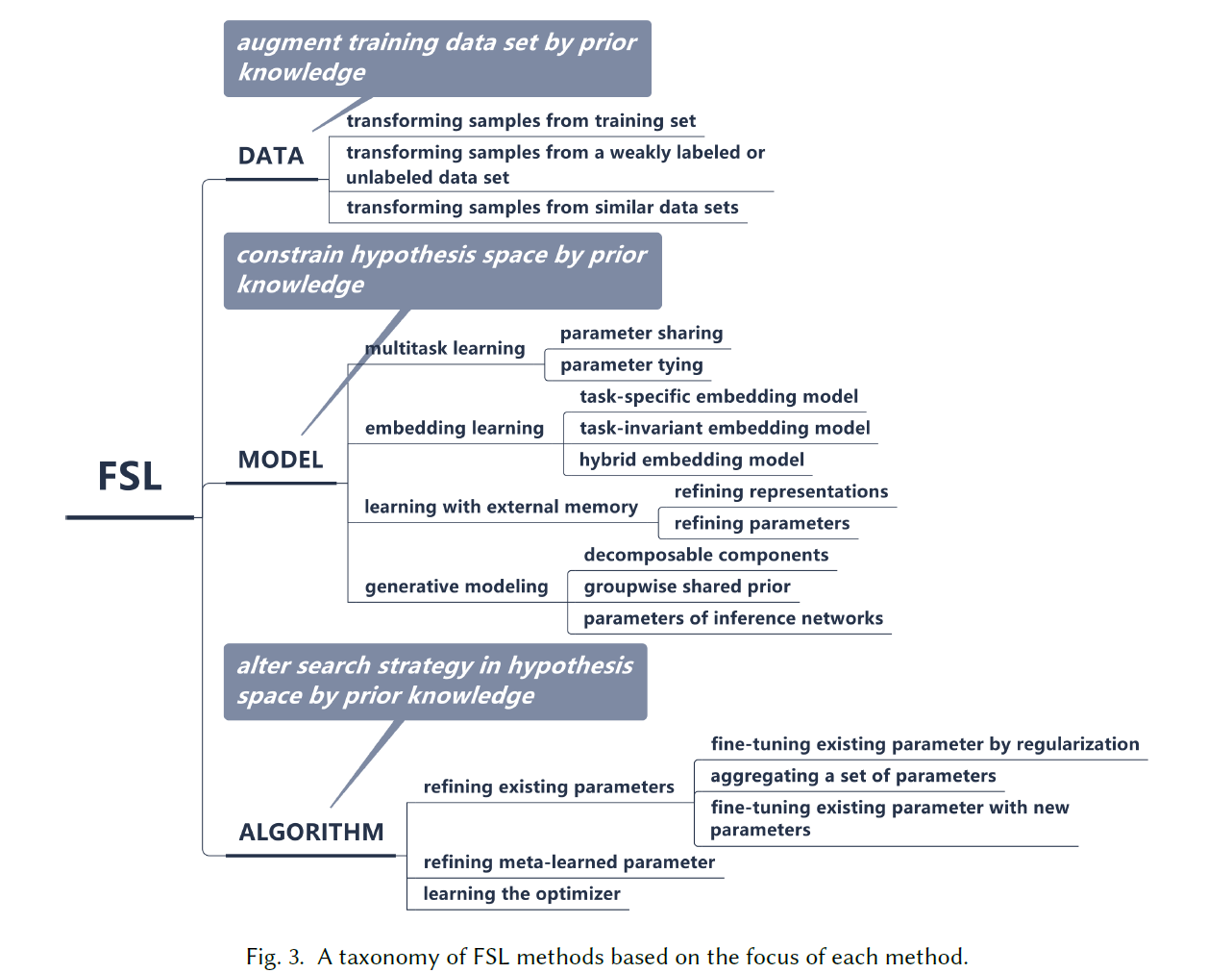
FSL的核心问题是:经验风险最小化器不可靠;那么如何使用先验知识去解决这个问题?
三个主要的角度:
- 数据:使用先验知识增强数据的监督经验
- 模型:使用先验知识来降低假设空间
- 算法:使用先验知识来改变搜索最佳假设(来进行搜索?)
现阶段针对FSL提出的一些相关的机器学习方法:meta-learning; embedding learning; generative modeling etc.
本文的主要工作:
- 基于FSL的原有设定,在现阶段的FSL发展上给出正式定义,同时阐明具体目标以及解决方式
- 通过具体示例列举和FSL的相关学习问题,比较了相关性和差异性,更好的区分问题
指出核心问题:经验风险最小化器不可靠,这提供了更系统有组织的改进FSL的方向。
经验风险最小化器👉:基于ML中的错误分解来分析的整理,更好的理解
- 未来方向
Notation and Terminology

一般基于参数方法(因为非参数方法需要大量数据),在假设空间中搜索最优假设,并基于基于标签的Loss Function 来衡量效果。
Main Body
Overview
2.1:具体定义&示例 2.2:相关问题和FSL的相关性和差异 2.3:核心问题 2.4:现有的方法如何处理这个问题
Definition

基本定义:FSL是一类机器学习(由E,T,P定义),其中E只包含有限数量的带有目标T监管信息的示例。
研究方法:通常使用N-way K-shot的分类研究方法:从少量类别中的少量样本回归出ML模型,
Training Set Contains:KN examples.
Typical scenarios of FSL:
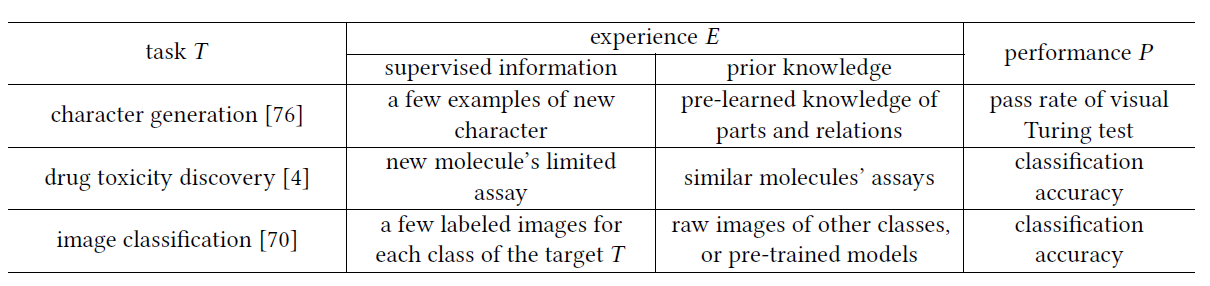
- Reducing data gathering effort and computational cost:
“raw images of other classes or pre-trained models ”
似乎有点迁移学习的味道了,改善从已有的类似数据集过来的model? - Learning for rare cases
- Acting as a test bed for learning like human.
和普通的ML的应用最明显的区别就是E中prior knowledge的应用,将T和先验知识结合起来。(such as Bayesian Learning [35,76])
Attention:Zero-shot:要求E中需要包含其他模态的信息(比如属性,wordnet,word embedding之类的)
Relevant Learning Problems
WSL:Weakly supervised learning:
重点在于learns from E containing only Weak supervised(such as: 不完全,不精确,不准确,或者充满噪声的监督信息),WS 中信息不完全只有少样本这一类情况就是FSL了,在此基础上基于Oracle还是人工干预的方法,可以进一步细分为:Semi-supervised learning:
从E中的少量标记样本和大量未标记样本中学习。示例:文本和网页分类;其中包含Positive-unlabeled learning这种特殊问题,只包含positive label的问题:具体而言就是,只知道用户现在用户中标记的好友,而与其他未标记人之间的关系是未知的。Active Learning:
文章:选择信息量最大的未标记数据区query an ordacle?
个人理解:选择信息量最大(通常用不确定性大的数据表示)来让人标注,从而构建数据集,让算法能够通过较少的数据标注操作实现更好的效果。WSL with incomplete supervision 仅仅包括分类和回归的内容,而FSL还包含RL问题;WSL使用unlabel data 对E进行扩充,而FSL更多的使用各种类型的prior knowledge来扩充E,包括pre-train model ,其他领域的监督数据,未标记数据等等。
Imbalance learning:
数据集的分布不均衡,比如一些y值很少用到的情况。IL从所有可能的y中Train&test,FSL基于少量案例train&test y,同时也可能基于一些先验知识来。
Transfer learning:
transfers knowledge from the source domain/task 👉 target domain/task, where training data is scarce.其中Domin adaptation,是一种TL:source/target tasks are the same but the source/target domains are different.举例说明就是:情感识别,一个基于电影评论,一个基于日用品评论。
Transfer Learning广泛的应用于FSL,[7,82,85]将先验知识从源任务转移到Few-shot task,从一些训练数据丰富的源域转移
Meta-learning:感觉正文中讲的是个狗屎,后续通过附录中的看看
Meta-learning methods can be used to deal with the FSL problem. the meta-learner is taken as prior knowledge to guide each specific FSL task.
Core Issue
- 经验风险最小化
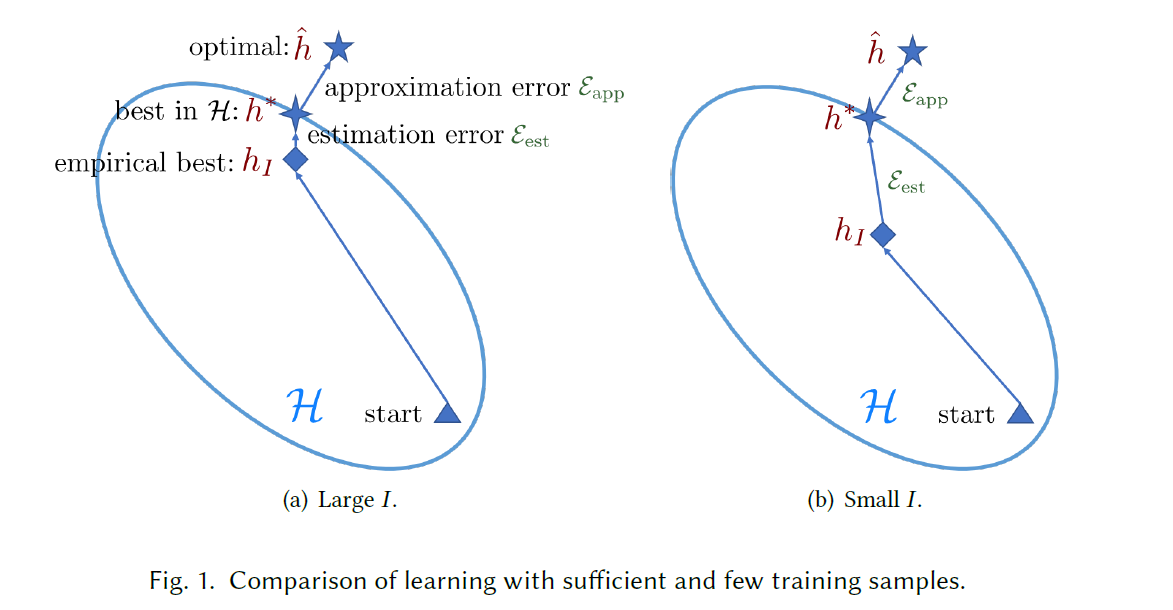
Machine Learning其实是一个经验风险最小化的模型

上面这1 3的区别一个是在全空间上,另一个是在是我们的假设空间中,能取到的最优解。
总体误差可以基于最小预期风险和最小经验风险来表示,如等式3。期望实和训练集的随机选择有关的,the approximation error 衡量了假设空间中的函数能够接近最优假设的程度,the estimation error 衡量了,最小经验误差代替最小期望误差在假设空间内的影响。

- data (which provides Dtrain)数据角度
- model which determines H(embedding function,转换到假设空间)
- algorithm(searches for the optimal h)学习算法,下降方向
不可靠的经验风险最小化
如果数据足够大的话,通过少量样本计算出来的假设空间就可以逼近实际上的最优假设空间,也就能得到一个很好的近似,但是在FSL中,可用的样本数很少,所以可能没办法产生很好的逼近,在这种情况下,产生的经验风险最小化指标hl过拟合,这就是FSL中的核心问题。
Taxonomy
为了解决FSL问题中经验风险最小化工具中hl的问题,prior knowledge是至关重要的,利用先验知识来扩充信息量的不足,基于先验知识的类别和使用方式就能对FSL works进行分类。
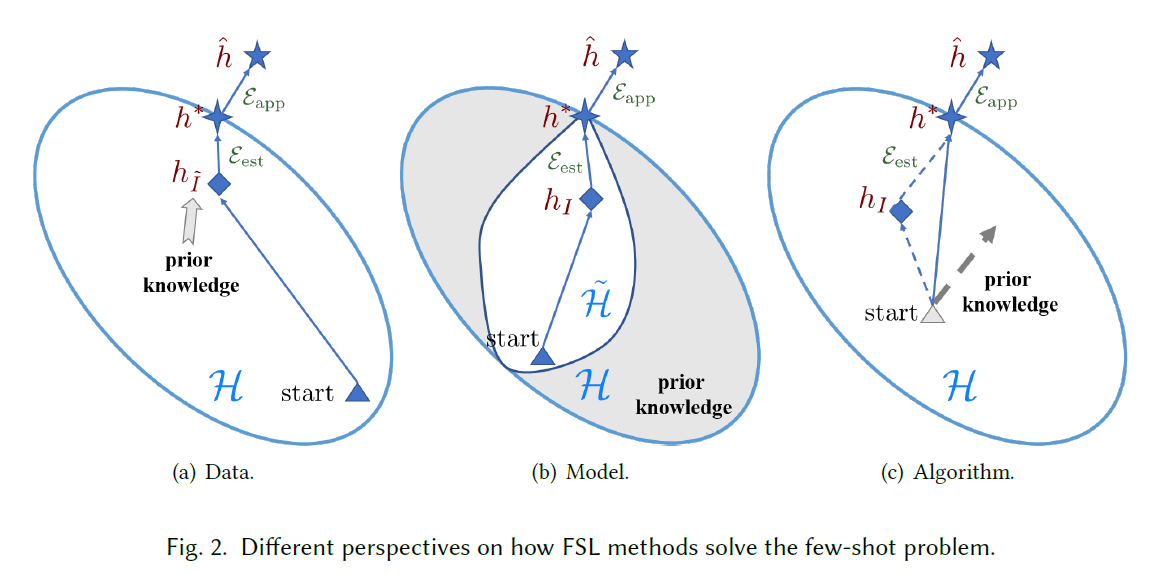
- Data:通过数据增强等方式,增加数据量,从而使得经验风险最小化因子能够更加的准确。
- Model:用先验知识来约束假设空间,使得需要搜索的范围变小,那么基于较少的数据也能够得到一个较好的估计,(相比原来)
- Algorithm:使用先验知识,来搜索最优假设的参数,基于这些先验知识提供一个较好的initialization,或者guiding the searching steps
Data
通过手工指定规则来进行数据增强的方式例如::arrow_double_down: 很大程度上取决于领域的知识也需要人工成本,此外,这样的方式在数据集间的泛化能力很差,一般都是针对性设计,而且这样的不变性,不可能由人工穷举出来,所以这样的方式不能完全解决FSL问题。
translation, flipping, shearing, scaling, reflection, cropping, rotation.
Advance data augmentation:
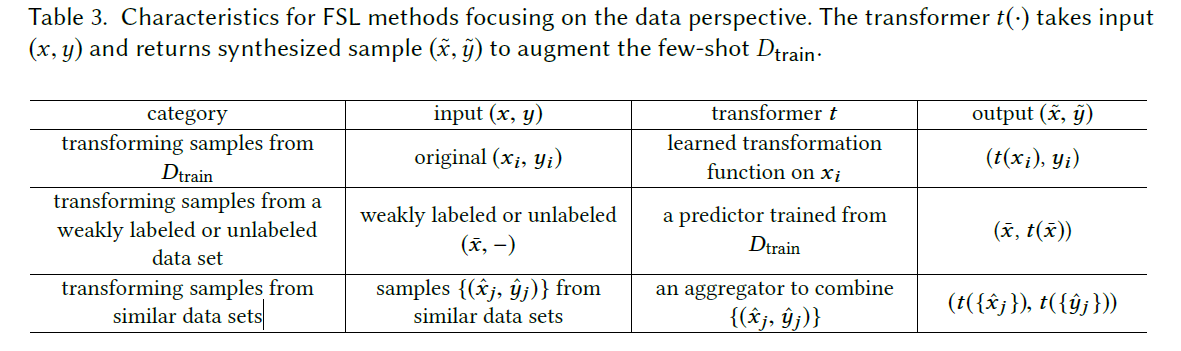
Transforming Samples from Dtrain
对训练集的数据进行几何变化处理,生成其他的样本,构建一个更大的数据集。
从相似类中学习一组编码器(每个编码器代表一个类内可变性),将这些习得的变化量添加到样本中形成新的样本。
基于差异从其他类别中转移过来
从一个样本变成多个;连续属性子空间来添加属性变化
基本思路是一致的,通过变换,在原本数据的基础上,构建新的数据,只是有着不同的构建方式。详细的各种类型的构建可以看参考文献。
Transforming Samples from a Weakly Labeled or Unlabeled Data Set
基于弱标签或者无标签的数据来进行数据增强的情况,类似视频中有些事件之间变化比较大的情况,可以将这样的数据添加到训练集中来更清楚的预测。
:dagger:但是如何筛选哪些有需要的弱监督数据?
⭐基于训练数据训练一个svm进行筛选,然后将具有目标的示例添加进数据集
⭐Label Propagation,直接使用未标记的数据集
⭐也有文章采取逐步从信息量最大的数据中筛选的做法
Transforming Samples from Similar Data Sets
:tada: 汇总和改造相似的数据集,来扩充Few shot情况,基于样本之间的相似性度量来确立权重,典型的方法就是:使用GAN,生成器将Few-shot的训练集映射到大规模数据集,另一个生成器将大规模数据集的样本映射过来,从而训练出可以辅助样本迁移的模型。
Summary1
这些方法的使用取决于具体任务;
:x: 缺点:通常是针对数据集量身定做的
:+1: 针对这个问题有人提出了AutoAugment
:heavy_multiplication_x: 缺点:文本和音频的情况下就很难做这样的生成了
MODEL
:fire: 如果仅仅基于简单的假设去考虑的话,那么可能在我们的假设空间中的最优和实际的最优(不足以模拟现实社会中的复杂问题)会有比较大的距离,但是如果考虑复杂多样的假设空间,那么标准的机器学习模型也是不可行的(数据量不足以优化到最优解),考虑使用先验知识,将复杂多样的假设空间H 约束到较小的情况下进行学习,这样的话经验风险最小化器将会更加的可靠,同时也降低了过拟合的可能性。
根据先验知识的类型,可以划分成如下几种FSL:
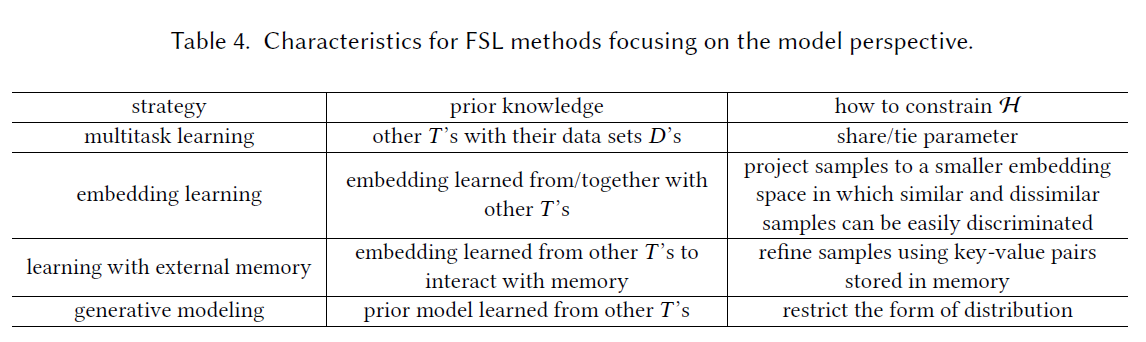
Multitask Learning
:fire: 多个相关任务协同训练,基于特定任务的信息和通用任务的信息来一起学习,其中利用某些/其他任务的大量数据(源任务),在训练过程中,通过学习到的参数来对只有Few-shot(target task)进行约束。基于训练中参数对target的约束方式可以分为
parameter sharing参数共享 160 61 95 12
基本的网络架构如下图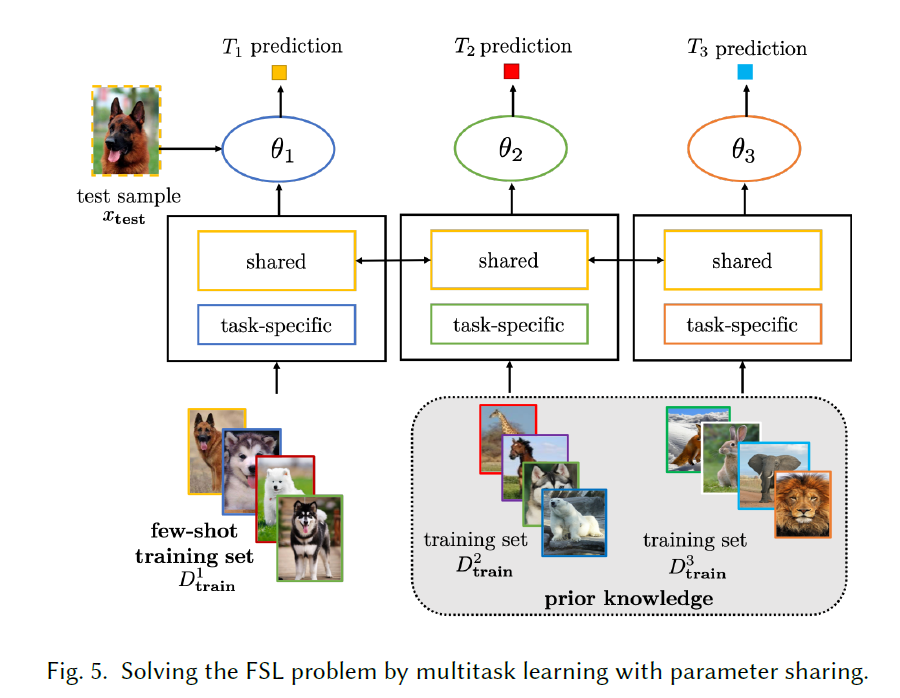
:zero: 有多种不同的架构,整体都是由共享层(参数是一致的)和特定于任务的层一起构建的,简单的描述一下如下:- 初始共享然后分配到特定任务;2. 源任务(pre训练)训练共享层,目标任务训练目标层;3.分别单独学习再有共享的编码器嵌入成一体。
parameter tying参数绑定 45 151 85
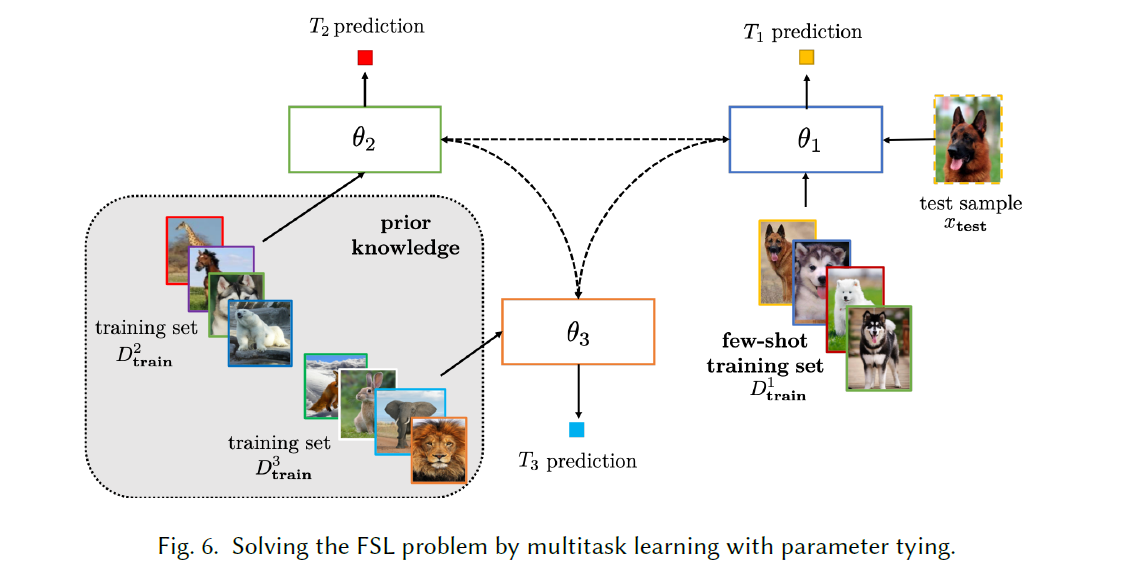
⭐基本思路:鼓励不同任务之间的参数存在相似性。对参数进行正则化是一种流行的方法。:one: 有的方法对成对参数之间的差异及逆行了惩罚,从而确保参数分布的相似性
:two: 有的方法通过针对源任务和目标任务设置不同的CNN,之间使用特殊的正则化术语对齐。
Embedding Learning
基于先验知识(同时可以额外使用Dtrain中的任务特定信息)构建样本的一个低维嵌入,这样便能得到一个较小的假设空间,同时相似的样本会紧密接近,而异类的样本更容易区分。
Key Components:
- 将测试,训练样本用embedding函数(f,g)嵌入。f,g可以统一,但是分离的时候可以受获更好的准确度
- 相似性度量在嵌入空间(一般都是维度更低的空间)进行,
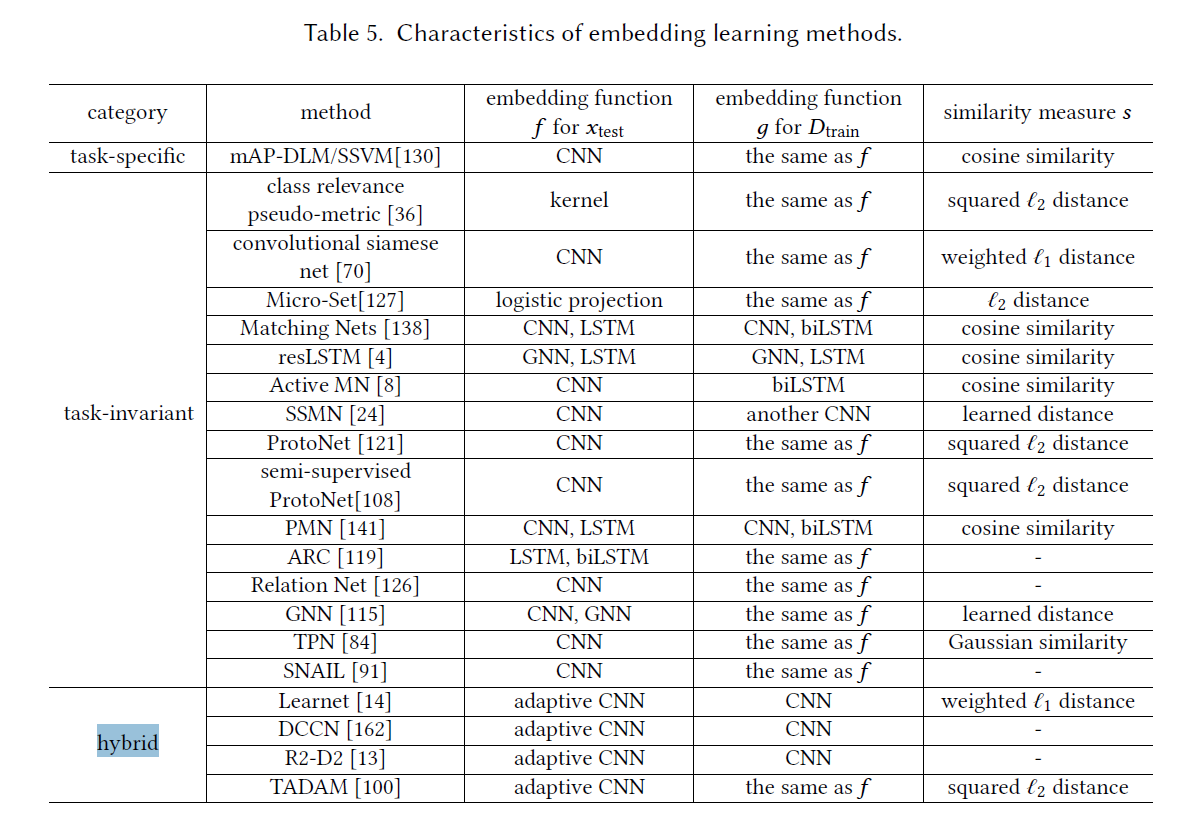
可以根据embedding函数的参数是否随任务变化分类
针对任务的嵌入模型
仅仅使用来自该任务的信息来学习针对性的嵌入模型。通用的嵌入模型(task-invariant)
使用有足够样本且具有各种输出的大规模数据集,学习通用的embedding function,然后直接用于Fewshot。Recently, more complicated embeddings are learned [70, 150] by a convolutional siamese net [20]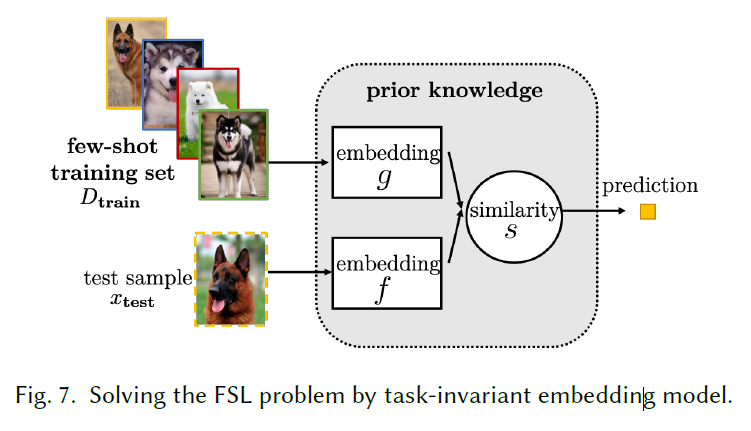
通常而言,task-invariant不会使用Few-shot的数据集来更新embedding function参数,但是,其中很多情景都会模拟few-shot 的情景来训练embedding从而确保对此类任务有更好的概括性能。
⭐Mathching Nets
meta-learning / resLSTM / AL /set-to-set⭐Prototypical Networks
embedding(xtest)不与每个g(xi)对比,而是每一类别的训练数据都有一个”原型“(原型公式如下),与原型对比,减少计算量。有两种变体:应用到matching-net 和 semi-supervised-108(软分配未标注的样本用以增强Dtrain)
:zap:Other Method
ARC:利用attention+LSTM将xtest的不同区域和原型进行比较,然后将比较结果作为中间嵌入,在使用biLSTM(双向LSTM)进行最终嵌入;
Relation Net 使用CNN将Xtest和Xi拼接在一起,再使用另一个CNN输出相似度得分。
GNN:利用GNN使用临近节点的信息
SNAIL简单神经注意力学习器(RL通常看重时间信息):temporal convolution +Attention,聚合临近步长和通过Attention选择特定时间步长的信息。混合嵌入模型,可以编码 task-specific 和 task-invariant 的信息
虽然task-invariant可以再迁移的时候减少计算成本,但是针对一些特殊的少样本情况,他是无法直接适应的,比如说原本就是小概率事件(异常),这种情况下,基于Dtrain训练的先验知识来adapt通用的embedding模型,从而组成一个混合的结构,如下图所示。
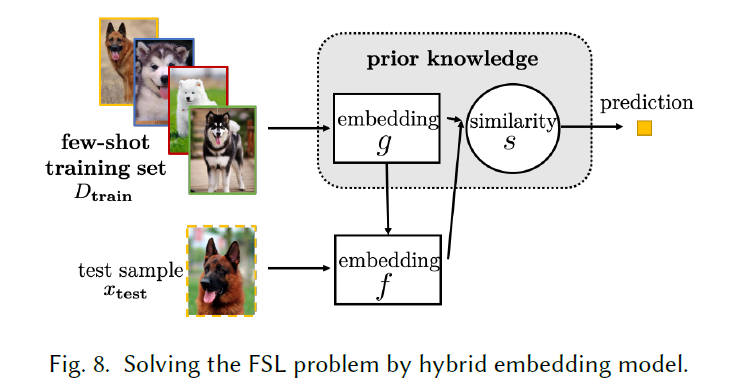
Learnet从多个meta-training set中学习meta-learner,并将训练实例映射成网络中的参数(convolutional Siamese net),这样f的参数就会随着输入改变。还有一些针对其的改进
TADAM:将类别原型平均化到嵌入中,并使用meta-learned 映射成圆形网络的参数
DCCN:使用固定的滤波器,并从Dtrain中学习组合系数。
Learning with External Memory
基于Dtrain 训练一个Embedding function,提取出 key-value的知识,存储在外部存储器中,对于新样本(test),用Embedding&相似度函数查询最相似的slots,用这些slots的组合来表示样本,然后用简单的分类器(like softmax)进行分类预测。由于对M操作成本高,所以M通常尺寸较小。当M未满时,可以讲新样本写如空闲的存储插槽。
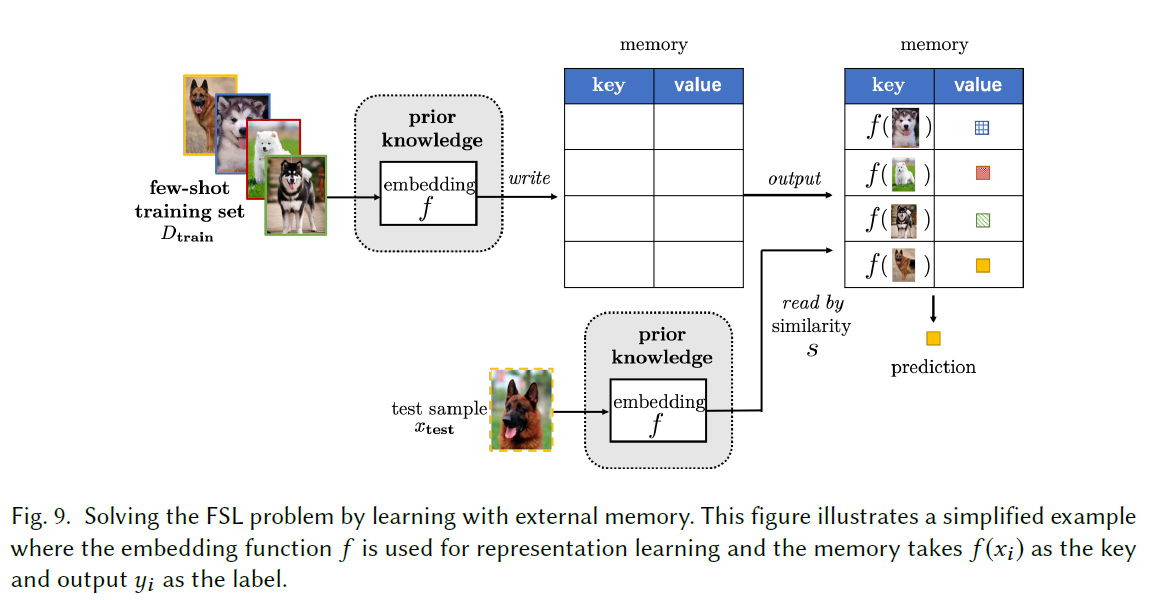
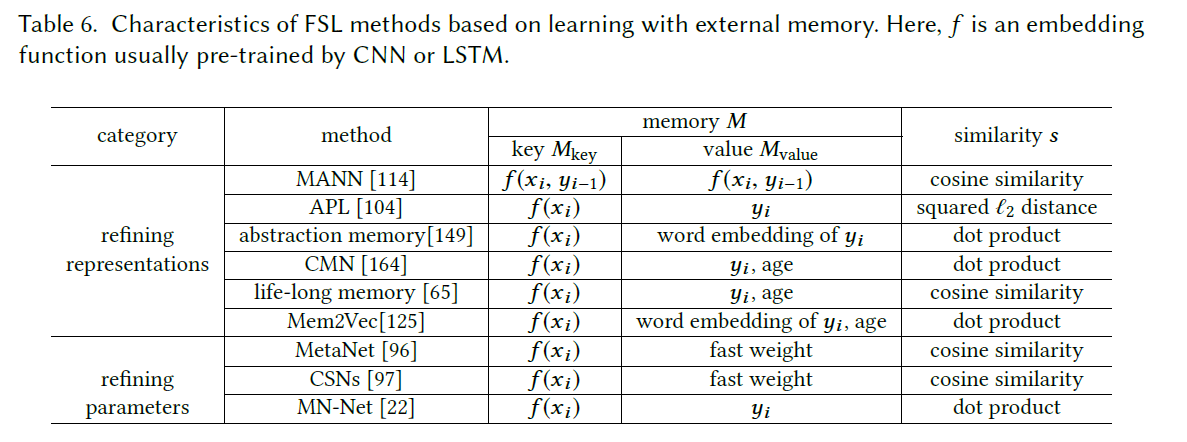
key-value的表征,也就是memory中的定义在这个方法中至关重要,它决定了键值对对test的表征水平。根据存储器的功能,将这类方法分成两种类型:
:one:Refining Representations:
- MANN:meta-learns embedding f,将同类的样本映射到同一个value,同一类的样本一起在内存中优化类表示。可以看成ProtoNet中精致的类原型。
- 当且仅当M不能很好的表征x的时候更新M。
- The Abstract Memory: 使用两个M,一个基于大量数据训练出的固定键值对,另一个从固定键值对对少量类进行精炼提取。为此有的方法会注意保留M中的FS。
- few-shot在M中很容易被其他samples的值表征从而取代,为了解决这个问题,提出的此算法👇
- lifelong memory:通过删除oldest slot来update M,同时给所有slot的期限置为0,当新样本在经过M后输出的表征与实际输出匹配的时候,就合并,而不更新M。(但是还是没有真正的解决这个问题)
:two:Refining Parameters:
- MetaNet、MN-Net: 对特定任务的数据进行fast 学习,而通用任务slow更新,然后结合memory的机制。(参数化学习
Generative Modeling
借助先验知识,从x的分布中估计先验p(x;$\theta$ )的分布,从而估计和p(x|y)和p(y),基于这样的先验数学模型进行后续的计算。而先验估计过程中通常是从别的数据集获悉的先验分布中,基于某个潜在的参数z迁移过来的如下式,这样就能基于既有的后验分布,约束H假设空间。
通常在识别,生成,反转,重建中有较常见的应用
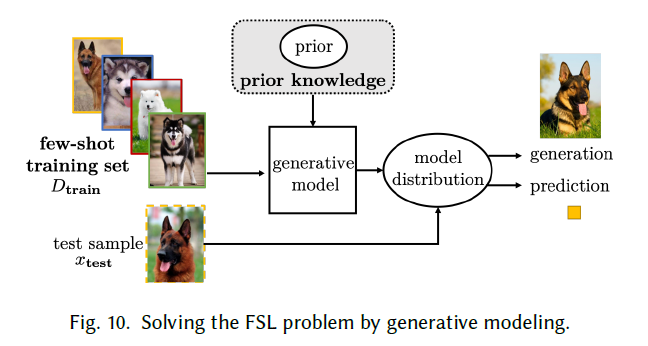
Decomposable Components:
基于人类的认知,将数据分解成组件级别,在进行后续的识别和重组;利用类间的通用性;Groupwise Shared Prior:
新的FS类别,先通过无监督学习分组,共享组内的类别先验,然后基于组内的先验对其进行建模。Parameters of Inference Networks:网络参数推理
为了找到最优的$\theta$ ,必须最大化以上的后验概率:
基于数据对其进行求解,inference network能够高效的迁移到新任务,但是inference network 需要大量的参数,所以通常需要在辅助的大规模数据集训练后才使用。很多经典的推理网络都可以在FSL上应用,比如VAE(可变自动编码器),autoregressive model,GAN,VAE+GAN
Summary2
详细的优缺点,参考文章
- 存在相似任务或者辅助任务:多任务学习
- 包含足够的各种类别的大规模数据集:embedding方法
- 存在可用的内存网络:在内存顶部训练一个简单的模型(分类器),可以简单的用于FSL,主要是要精心设计更新规则。
- 除了FSL还想要执行生成和重构的任务的时候:generative modeling
ALGORITHM
算法层面的改进指的是在最优空间H搜索H*的策略,最基础的有SGD。:x:在FSL的情况下,数据会使得更新次数不够多,同时也没法基于交叉验证找到合适的补偿之类的。:arrows_counterclockwise:本节中的方法用先验知识来影响$\theta$ ,具体体现为::one:良好的初值;:two:直接学习优化器以输出搜索步骤;
:zap:基于先验知识对策略的影响,对算法进行分类
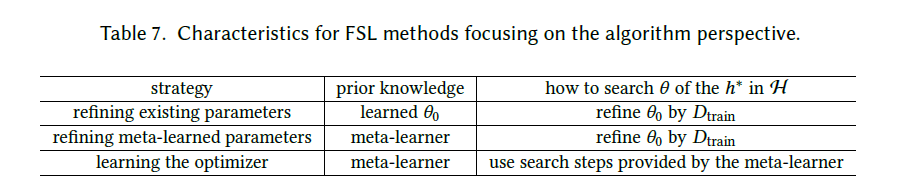
Refining Existing Parameters
:jack_o_lantern:基本思想:从相关任务中预训练模型的$\theta$0作为一个良好的初始化,然后基于训练集的几次训练来adapt。
Fine-Tuning Existing Parameter by Regularization:
如何解决overfit的问题是此类预训练算法设计关键:其中一种方式就是依赖正则化操作来adapt参数。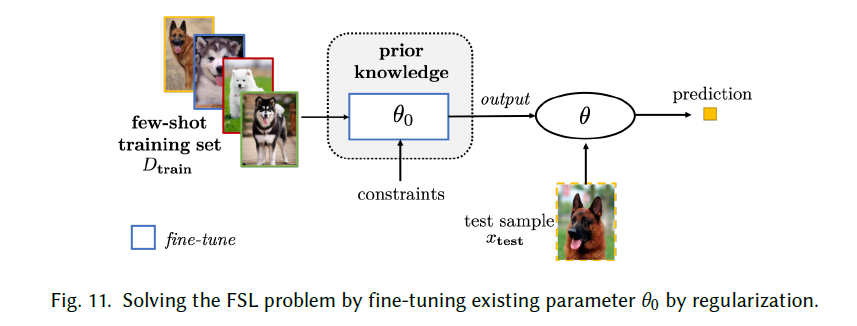
正则化的方式主要有以下几种:| Method | Analysis |
| —————————————————————- | —————————————————————————————— |
| Early-stopping | 监视训练过程,性能没有提高则停止学习 |
| Selectively updating $\theta$ | 根据具体问题,选择需要的部分来更新参数,不更新所有参数 |
| Updating related parts of $\theta$ together | 聚类$\theta$,然后共同更新每个组,BP更新$\theta$ |
| Using a model regression network | 捕获任务无关的transformation,基于function进行embedding的映射? |
| | |Aggregating a Set of Parameters:
聚合相关模型:不贴切的比如眼口鼻到脸;具体使用上,unlabeled/similar label dataset,的pretrain model参数到FSL参数的适应。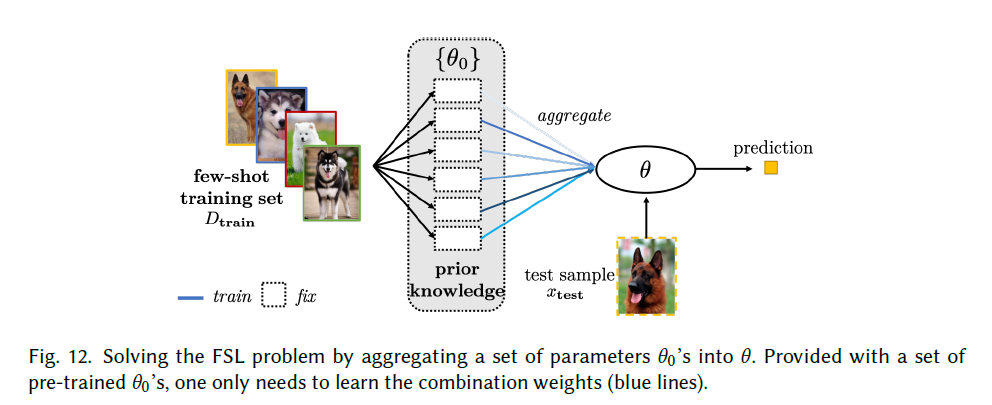
unlabeled dataset:
把相似样本分组聚类,然后adaptsimilar dataset:
替换相似类别中的特征,重新使用已训练的分类器,然后对新类调整分类阈值。
- Fine-Tuning Existing Parameter with New Parameters:
仅仅对模型迁徙可能没办法对FSL完全编码,所以我们在对参数进行adapt的时候加入一个新的参数,然后再Dtrain中同时adapt现存参数和learn新参数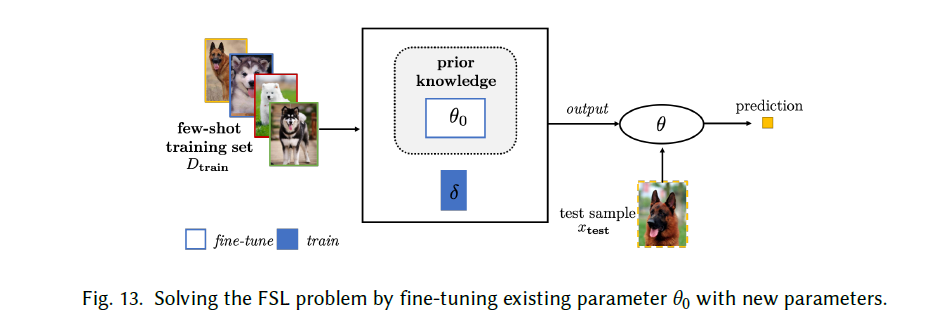
Refining Meta-Learned Parameter
本节中细化meta-learned的参数学习:$\theta$再过程中是持续优化的,不是固定的。
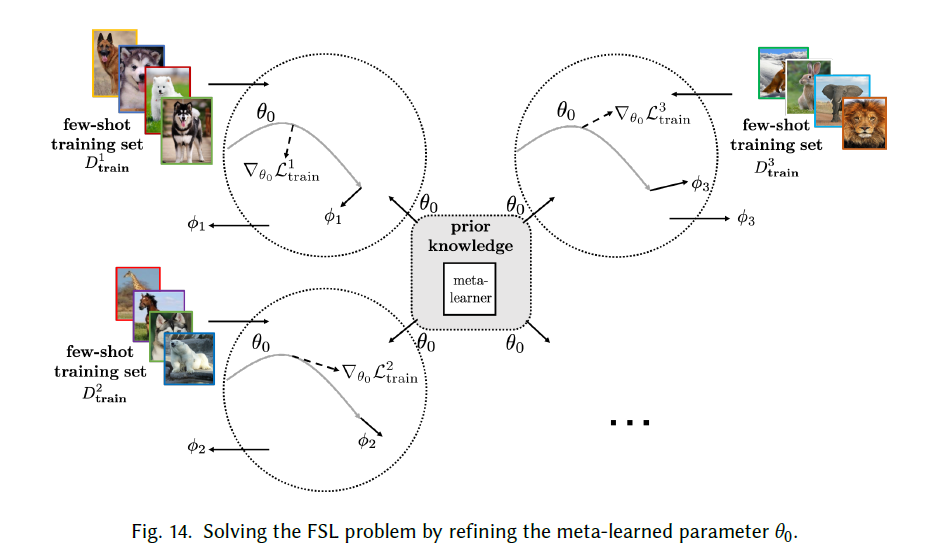
Model-Agnostic Meta-Learning(MAML)通过梯度下降来元学习 $ \theta$ ,基于该参数,得到任务特定参数$\phi~s$,更新公式类似如下形式$\phi{s}=\theta{0}-\alpha \nabla{\theta{0}} \mathcal{L}{\mathrm{train}}^{s}\left(\theta{0}\right) . $ 其中$L^s train$ 是训练样本的损失和, $\alpha $ 是步长,该参数$\phi~s$,对于样本的顺序不受影响,此外元学习中基本的参数更新公式如下$\theta{0} \leftarrow \theta{0}-\beta \nabla{\theta{0}} \sum{T{s} \sim P(T)} \mathcal{L}{\text {test }}^{s}\left(\theta{0}\right)$ ,其中测试误差是整个过程中损失的和。通过元学习将参数转移。
最近针对MAML提出了主要再以下三个方面的改进:
- :zap:合并特定任务的信息:MAML为所有任务提供相同的初始化,但是这样忽视了特异性,所以,从一个好的初始化参数的子集中为新任务选择初值
- :zap:使用meta-learned $\theta$的不确定性去建模:结合AL
- :zap:改进refining过程:对$T~s$使用正则化?
Learning the Optimizer
不使用梯度下降,学习一种可以直接输出更新的优化器,无需调整步长$\alpha$ 和搜索方向。
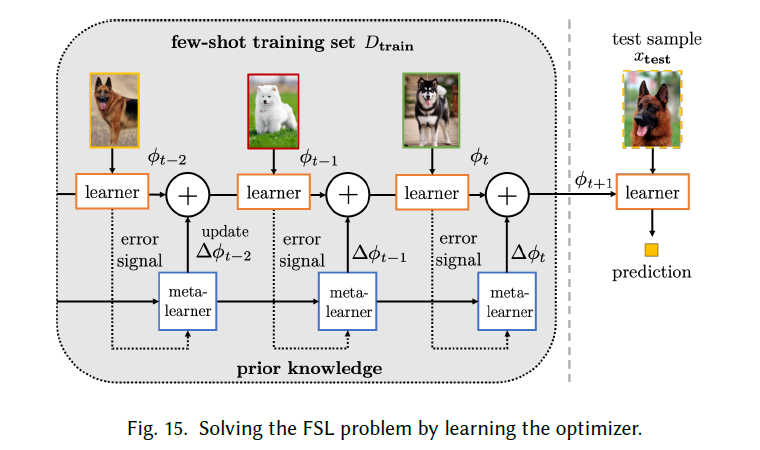
LSTM+Meta-Learner?
Discussion and Summary:
通过对现有参数进行微调,从而减少H需要的搜索量:
- 使用现有$\theta$作为初始化:牺牲一些精度换取速度
- 另外两种策略都是依赖于元学习,元学习可以让参数和指定任务更为接近,还有一种直接充当优化器。
Future Works
- 在未来的FSL中使用多模态的prior knowledge
- SOTA网络架构的使用来改进data,algorithm,model;
- AutoML在FSL任务中的应用
- meta-learning中动态学习中,如何避免catastrophic forgetting
- 在各领域中的应用:CV,bot,NLP,Acoustic signal process,etc
:zap:Theories:
FSL使用先验知识来弥补缺少监管信息的情况;
FSL很多时候和domain adaptation 有关系
FSL的收敛性研究还没有完全了解
Appendix
Reference:

之后整理一些可能需要阅读的reference
只关注小样本的概念学习和经验学习的Another FSL survey:
J. Shu, Z. Xu, and D Meng. 2018. Small sample learning in big data era. arXiv preprint arXiv:1808.04572 (2018).FS-RL,在仅给出少量状态和动作对组成的轨迹的情况下找到一种策略:
[3,33]
Bayesian Learning :
[35,76]
Additional Vocabulary:
| 序号 | 希腊字母 | Markdoown | 序号 | 希腊字母 | Markdoown |
|---|---|---|---|---|---|
| 1 | α | \alpha | 19 | β | \beta |
| 2 | γ | \gamma | 20 | δ | \delta |
| 3 | Γ | \Gamma | 21 | Δ | \Delta |
| 4 | ε | \varepsilon | 22 | ϵ | \epsilon |
| 5 | ζ | \zeta | 23 | η | \eta |
| 6 | Θ | \Theta | 24 | ι | \iota |
| 7 | θ | \theta | 25 | κ | \kappa |
| 8 | Λ | \Lambda | 26 | λ | \lambda |
| 9 | μ | \mu | 27 | ν | \nu |
| 10 | ξ | \xi | 28 | ο | \omicron |
| 11 | Π | \Pi | 29 | ρ | \rho |
| 12 | π | \pi | 30 | τ | \tau |
| 13 | Σ | \Sigma | 31 | Φ | \Phi |
| 14 | σ | \sigma | 32 | ϕ | \phi |
| 15 | Υ | \Upsilon | 33 | Ψ | \Psi |
| 16 | υ | \upsilon | 34 | ψ | \psi |
| 17 | Ω | \Omega | 35 | ω | \omega |
| 18 | φ | \varphi | 36 | Ξ | \Xi |
术语或生词:
- empirical risk minimizer :经验风险最小化器
- ultimate goal :最终目的
- To name a few: 举几个例子
- autonomous driving car:自动驾驶汽车
- tackled:解决
- paradigm:范式
- ethic:道德
- taxonomy:分类
- the pros and cons of different approaches:不同方法的利弊
- with respect to:关于
- the approximation error:逼近误差
- the estimation error:估计误差
- alleviate:缓和,减轻
- aggregation:聚集
- simultaneously:同时,兼
- penalized:受惩罚的
- hybrid:混合的
- interleaved:交错的
- denominator:分母
注意区分:
- sufficient:足够
- terminology:术语
- refine:提炼 提纯
- leverage:利用
- latent:潜在的
FAQ
- [x] Testing Set需要在N-way上进行吗?应该是要的
- [x] AL的query or oracle 是啥意思
- [x] According to whether the oracle or human intervention is leveraged, this can be further classified into the following
此处 oracle到底是什么意思 - [x] Semi-Supervised 又和FSL有什么区别呢
- [x] Imbalance Learning确实不是很理解
- [x] Generative Modeling的具体要素不是很懂
- [x] Core Issue中的三个h的关系还有点疑惑
app:在最优的情况下,能搜索到的最优解和实际最优解之间的差距
est:实际的假设空间中的最优解和基于少量样本的经验得到的假设空间中的最优解之间的距离。 - [x] Parameters of Inference Networks,不知道怎么理解,后续要补充
—
需要思考的点
- [x] Few-shot-learning & meta learning的问题设置,就是多类中都有足量样本,然后随机的从多类中选取few-way和few-shot的data模拟多种meta环境(fewshot和fewway),单次训练都是小样本的情况,进行学习,在这种环境下学习到,一个模式,然后从而减少数据量的要求。(这样就哪里减少了数据量啊,我就没懂了,)
- [x] 那么假如说没有多类动作(怎么构造多类动作):不会,我们可以在网上爬取,或者自己拍摄,因为只需要少量有标注的数据即可,也就是positive数据可以比较容易获得。
- [x] 那么我们在构造增量的时候,也是考虑边际效益,然后当数据量达到一定规模的时候可以采用直接训练分类器的分类器,来对效果进行分类
- [x] Few-shot-learning中,训练集和测试集,标签已知和未知到底怎么弄,从代码中以及定义中分析的话怎么感觉是两个意思。我们需要的应该不能用到那个。
- [x] few-shot-learning应该指的是,新类只有很少的样本,但是旧类还是有大量标注样本的情况这个我们要好好分析。
但是这样的创新点在于更多的是算法的组合,有没有办法提出一个网络结构将这样的思路融合起来。!!!
Survey for Few-Shot Learning



