
MIM-V-MAE
@Author:Facebook AI Research-Kaiming He
Kaiming-MAE
Conclusion
总而言之这是一种大模型的训练方法, 通过在少量数据的基础上实现大模型的训练.
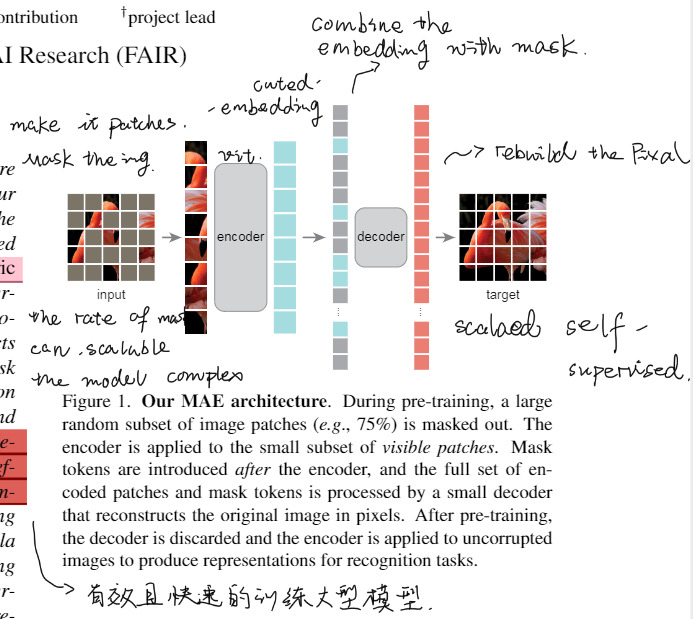
整体的架构上是参考了NLP中的AutoEncoder机制,将原图切分patch,用mask掩盖原图,通过少量可见的Patch进行Encoder后和Mask融合,再通过非对称的Decoder进行pixel的还原。
这种设计的有点在于mask的scala是可变的,同时这种mask能减少我们训练过程中对显存和计算复杂度的损耗,同时问题本身是一个比较复杂的问题,得以训练复杂的大模型,这种方式最终呈现的效果就是训练的效率高且效益好。
体现了自监督学习在这方面的优越性,同时这种方法得以实现也是由于ViT模型对于CNN模型的取代,才使得这种序列化切块的方式容易实现和验证。
这种方式在最终体现了自监督学习对于有监督与训练的优越性,使用这种方式能够更好的得到一个模型的通用表征。
在这里论文中也说明了和NLP的不同点以及这样的模型对于decoder的要求实际上是比NLP更高的
experiment
Masking:对于输入的图像进行均匀的切分并均匀的随机采样
MAE encoder: 简单的ViT模型,对输入图像进行编码后和Mask进行混合得到一个完整的令牌集合,从而确保Decode能够得到对应的位置信息。
MAE decoder:轻量级的架构,可以独立于编码器进行设计,我们使用更窄更浅的网络,计算量比编码器10%更小,这样能够更快的进行训练。解码器的最后一层是先行投影,输出的数量==补丁中像素值的数量,最后会resize层原图的维度。
MIM-V-MAE



