
IL-MgSvF
@Author & Paper:Arxiv
@Note:Aikenhong 2021/11/12
Intro
旧知识的缓慢忘记和新知识的快速适应的困境:主要探讨Incremental中的Old和New的相互牵制和适应的问题,
旧知识的缓慢遗忘会导致对新任务的欠拟合,而快速适应会导致灾难性的遗忘,如何对这两种策略之间进行权衡,是一个重要的问题。
多尺度混合的解决这个问题:
- Intra-space: 新类别的特征在同一个特征空间中
- inter-saoce:新旧类别的特征在不同的特征空间中
本文提出的多粒度策略:
- 提出了一种频率感知的正则化操作,加速空间内的增量学习能力
- 新的特征空间组合操作,提升空间间的学习性能
实际上新类和旧类的特征最好是通过自监督或者无监督的特征学习方法归化到同一个特征空间中,在这种情况下对Classifier进行调整可能是一种更好的策略。通过混合特征空间来得到一个泛化能力更高的特征表示器。
传统的策略:无论是累加还是进行数据混合进行梯度计算,这种方式应该是将类别之间的梯度进行直接的叠加。
- 是否可以自行混合不同类别之间的学习梯度?通过对梯度的下降方程求解来得到一个旧类和新类之间的更好的下降方法。
- 具体的操作上就是对step进行处理,通过mixdataset对梯度进行分开计算
- 在混合策略上可以考虑梯度的下降方向,对不同的维度进行加权计算?
- 上述的策略难以实施的点在于框架中的梯度是自动计算的,我们可以对损失进行加权,但是很难重新计算不同节点之间的梯度值
- 退而求其次的方法就是对新旧类的损失进行加权处理, 或者直接的混合数据
- 如果我们能获取梯度的方向, 或许我们能在每次迭代的过程中获得一个更好的加权值
- 首先可以尝试对梯度进行获取,Grad
- 我们在蒸馏的过程中通过MLP对不同的类别进行聚类划分, 这种方式的聚类和传统机器学习聚类的优劣又如何对比解释呢.
- 能不能用PCA方法或者multi-head策略来对特征进行处理, 这种类似因果的方式来分析特征中的冗余维度
- 上述的分析基于Mix Guide make error 的想法, 实际上还有一个问题就是Feature’s capabliity 不足的问题
New Key Word: Few-Shot class-incremental Learning
有大规模训练样本的第一个任务和具有有限样本的新类学习两阶段任务的这种场景
Related Work
- 框架策略:
- 复习策略
- 正则化策略
Main
该文认为统一的特征空间是相互关联的,很难相互解开进行svf分析,同时新知识和旧知识的学习方向通常而言不一致,甚至有时是相互矛盾的,所以他认为需要一个全新的特征空间。
但是在Few-Shot的情境下,新的特征空间的泛化能力可能很差,本身带来的准确率就很有问题把
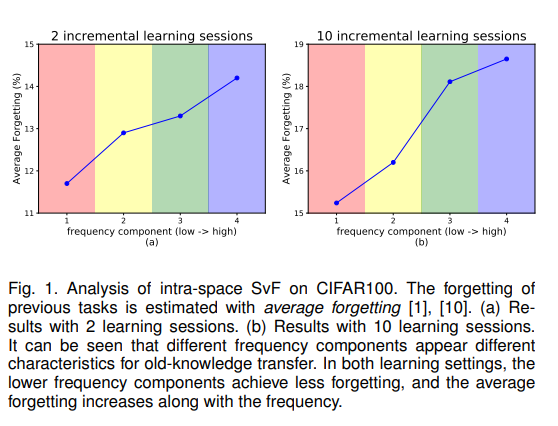
使用离散余弦变化,建立一个空间内的SVF特征分解方案,实现了一个像互不相关的正交频率空间,同时在不同频率上对新旧两种知识的重要性不同,低频分量对于保存旧知识的贡献更大,遗忘率则随着频率的增加而增加。
所以逼近旧特征空间的低频分量的正则项权重更高, 具体而言就是独立的特征空间的更新比其他空间更新更慢, 通过对特征空间的组合来组成上述空间的方法, 是十分灵活的, 即使是简单的串联也能带来巨大的性能提高
这确实是我没想到的, 也就是如果我们使特征并行化, 对最终准确率的提升增益是更大的, 这是为何.
FrameWork
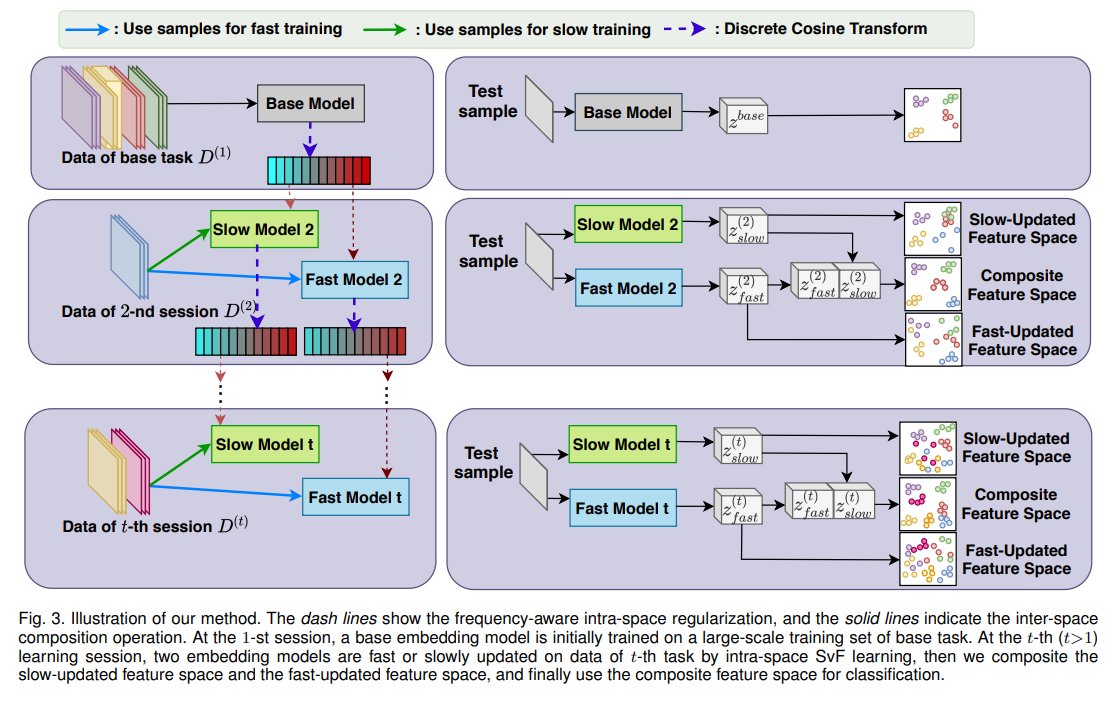
实际上就是维护两个模型, 然后进行特征的串联, 进行分类. 每次只对新的数据进行训练, 不会使用旧的数据.
IL-MgSvF



