# get dataset train_img = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
# get new model pretrained_new = model.expand_dim(dim=out_dim,re_init=True)
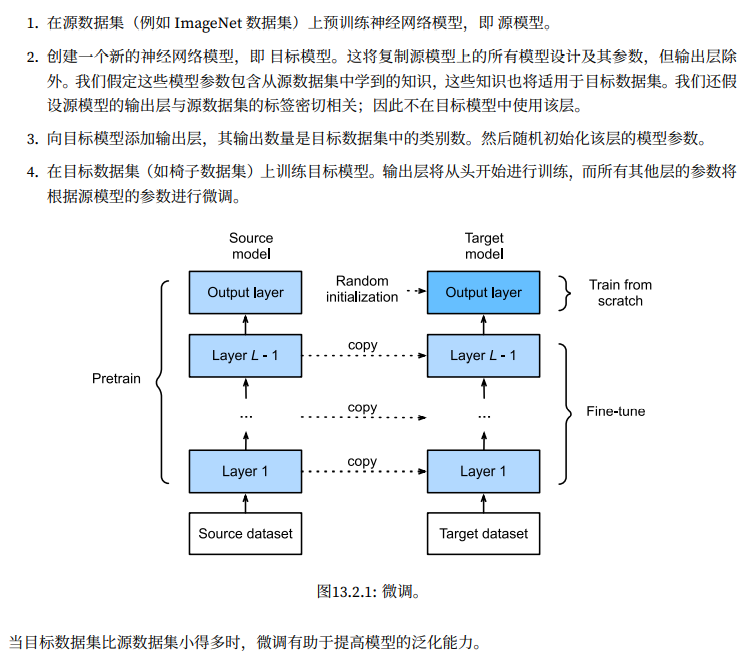
# pre train it 定义一个用于微调的函数 # pytorch可以通过字典的形式来区分对设置lr deftrain_fine_tuning(net, learning_rate, batch_size=128, num_epoch=5, diff_lr=True): # set dataloader train_iter = torch.utils.Dataloader(train_img, batch_size=batch_size, shuffle=True) test_iter = ...
# set loss loss = nn.CrossEntropyLoss(reduction='none')
# set diff lr for diff part of it if diff_lr: params_1x = [param for name, param in net.name_parameters() if name notin ["fc.weight", "fc.bias"]] trainer = torch.optim.SGD([{'params': params_1x}, {'params': net.fc.parameters(), 'lr': learning_rate *10}], lr=learning_rate, weight_decay=0.001 ) else: trainer = torch.optim.SGD(net.parameters(), lr=learning_rate, weight_decay=0.001)