UniFramework 01
Here's something encrypted, password is required to continue reading.


@Author: MSRA Zhenda Xie
@Source:Arxiv, Code TBP,Blog_CVer
@Read:AikenHong 2021.11.22
“What I cannot create, I do not understand.” — Richard Feynman
继MAE和iBoT之后,MSRA也提出了一个图像掩码建模的新框架,SimMIM,该方法简化了最近这些提出的方法,不需要特殊设计,作者也验证了不需要那些特殊设计就已经能让模型展现出优秀的学习能力
通过这种MIM方法可以实现在大量无标注的数据上得到一个表征能力up的通用特征模型,这种方式的backbone可以广泛的应用到图像上的各种子任务中(按照NLP)的经验来说,而为了类似的方式在图像上的大放异彩,我们首先需要分析Vision和Language的不同
掩码选择:同样的掩码的策略还是基于Patch进行的,对于掩码的设计来说,太大的掩码快或者太密集的掩码快,可能会导致找不到附近的像素来预测,实验证明32是一个具有竞争力的size,和文本任务的信息冗余程度不同也带来了覆盖比的选择,NLP通常是0.15,而在V中,32size可以支持0.1-0.7的覆盖率。
任务选择:使用原始像素的回归任务,因为回归任务和具有有序性的视觉信号的连续性很好的吻合。
预测头选择:使用轻量的预测头如(linear),迁移性能与繁琐的预测头相似或者略好,同时训练上更加的块。虽然较大的头或更高的分辨率通常会导致更强的生成能力,但这种更强的能力不一定有利于下游的微调任务。

@Read: AikenHong 2021
@Author: https://arxiv.org/abs/2111.07832
@解读:Machine Heart
基于NLP中的MLM(Masked Language Model)的核心训练目标: 也就是遮住文本的一部分, 然后通过模型去预测和补全, 这一过程是模型学到泛化的特征, 使用这种方法来进行大规模的与训练范式.
在基本的思想上和MAE采用的是一样的设计, 但是本文中坐着认为visual tokenizer的设计才是其中的关键.
不同于 NLP 中 tokenization 通过离线的词频分析即可将语料编码为含高语义的分词,图像 patch 是连续分布的且存在大量冗余的底层细节信息。而作者认为一个能够提取图像 patch 中高层语义的 tokenizer 可帮助模型避免学习到冗余的这些细节信息。作者认为视觉的 tokenizer 应该具备两个属性:(a)具备完整表征连续图像内容的能力;(b) 像 NLP 中的 tokenizer 一样具备高层语义。
文中对tokenizer的设计为一个知识蒸馏的过程:
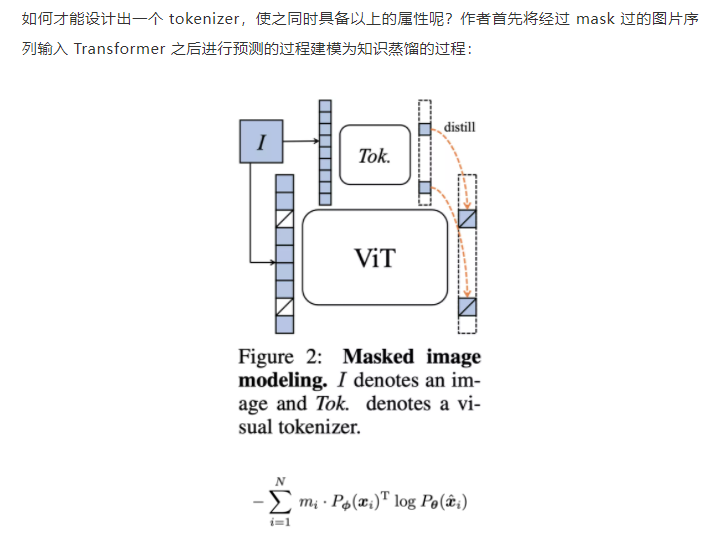
文中使用这种在线tokenizer同时来监督这样的MIM过程, 也就是两部分协同学习, 能够较好的保证语义的同时并将图像内容转化为连续的特征分布, 具体的, tokenizer和目标网络狗狗想网络结构, 有移动平均来得到实际的tokenizer.
该形式近期在 DINO [3]中以自蒸馏被提出,并被用以针对同一张图片的两个不同视野在 [CLS] 标签上的优化:
在该损失函数的基础上, MIM同样也是用这种自蒸馏的方式去优化, 其中在线tokenizer的参数为目标网络历史参数的平均.
基于上述的这些训练目标,提出了一种自监督预训练框架iBOT, 同时优化两种损失函数。

@Author:Facebook AI Research-Kaiming He
Kaiming-MAE
总而言之这是一种大模型的训练方法, 通过在少量数据的基础上实现大模型的训练.
整体的架构上是参考了NLP中的AutoEncoder机制,将原图切分patch,用mask掩盖原图,通过少量可见的Patch进行Encoder后和Mask融合,再通过非对称的Decoder进行pixel的还原。
这种设计的有点在于mask的scala是可变的,同时这种mask能减少我们训练过程中对显存和计算复杂度的损耗,同时问题本身是一个比较复杂的问题,得以训练复杂的大模型,这种方式最终呈现的效果就是训练的效率高且效益好。
体现了自监督学习在这方面的优越性,同时这种方法得以实现也是由于ViT模型对于CNN模型的取代,才使得这种序列化切块的方式容易实现和验证。
这种方式在最终体现了自监督学习对于有监督与训练的优越性,使用这种方式能够更好的得到一个模型的通用表征。
在这里论文中也说明了和NLP的不同点以及这样的模型对于decoder的要求实际上是比NLP更高的
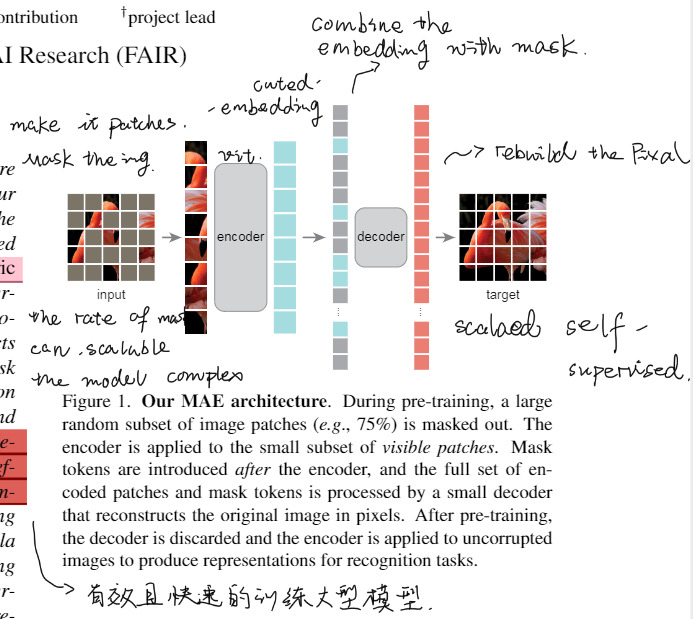
Masking:对于输入的图像进行均匀的切分并均匀的随机采样
MAE encoder: 简单的ViT模型,对输入图像进行编码后和Mask进行混合得到一个完整的令牌集合,从而确保Decode能够得到对应的位置信息。
MAE decoder:轻量级的架构,可以独立于编码器进行设计,我们使用更窄更浅的网络,计算量比编码器10%更小,这样能够更快的进行训练。解码器的最后一层是先行投影,输出的数量==补丁中像素值的数量,最后会resize层原图的维度。
@AikenHong2021 OWL
分析现有的OWL特点,和当前自己的研究做一个区分,也汲取一下别人的研究的要点,
Mulit Open world Learning Definition
拒绝未见过的类的实例,逐步学习新的类扩展现有模型
Large-Scale Long-Tailed Recognition in an Open World (liuziwei7.github.io)
@Aiken 2021
框架撞车系列,主要看看这一篇论文中怎么解决如下的问题👇,并从中借鉴和优化的我框架设计
模型实现的主要的两个TASK:
实现这两个问题的主要思路:
Tags: Paper
URL1: https://arxiv.org/pdf/1905.11946.pdf
URL2: https://arxiv.org/pdf/2104.00298.pdf
提出了一种模型缩放策略,如何更高效的平衡网络的深度、宽度、和图片分辨率
**1. Efficient Net: Rethinking Model Scaling for Convolutional Neural Networks
@Aiken H 2021 find detail to code his
除了提出了缩放策略以外,还使用神经架构搜索还建立了一个新的baseline network,得到了一系列模型。
平衡网络宽度、深度、分辨率至关重要,这种平衡可以通过简单的恒定比率缩放维度来实现,于是我们提出了一种简单有效的复合缩放方法。
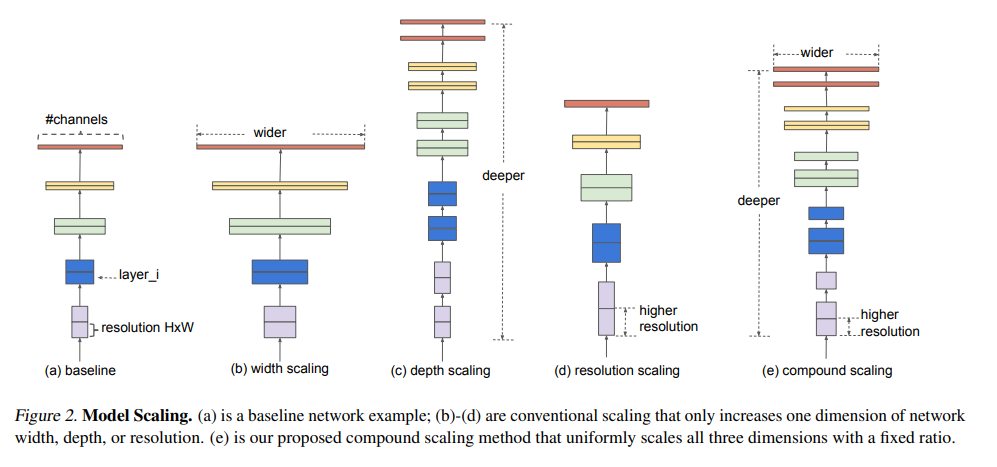
复合缩放的物理意义:输入图像更大的话就需要更多层来增加感受野和更多通道,从而能在更大的图像上捕获更多细粒度的图案,而宽度和深度(对于表达能力来说很重要)之间也存在着一定的关系,“我们”是第一个对此进行了建模的。
从各个维度单独的进行缩放能发现都存在着增益瓶颈,如何去得到这么一个合适的等比缩放增益

@Aiken 2021 究极万恶的撞车论文
Motivation :Tackle the problem of 发现无标注数据中与给定(已知)类别不相交的新类。
Related Research:
现有的方法通常1. 使用标记数据对模型进行预训练; 2. 无监督聚类在未标记的数据中识别新的类
作者认为label带来的essential knowledge在第二步中没有被充分学习利用到,这样模型就只能从第一步的现成知识中获益,而不能利用标记数据和未标记数据之间的潜在关系



