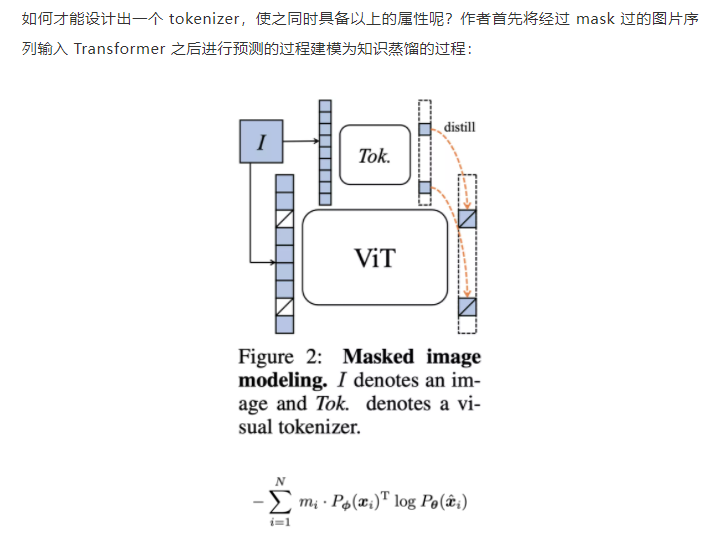
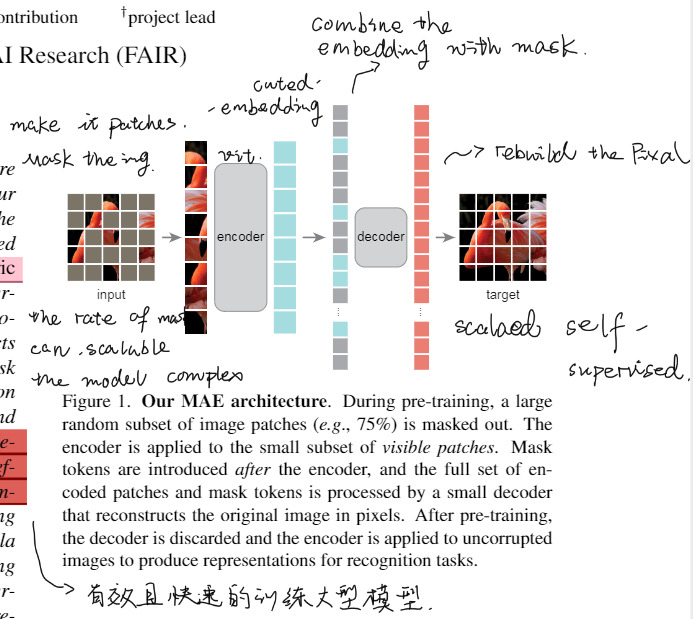
Transformer
@aikenhong 2021
References For Transformer:
- NLP The Transformer Family (lilianweng.github.io)
- VIT Transformer眼中世界 VS CNN眼中世界
- 李沐 NLP Transformer论文精读
- Suveys cver1, cver2,cver3
This blog will divided into several part : lil’s blog, the survey for ViT, we using those article to help us understand the transformer.
综述我们以最新的一篇为准进行阅读,其他的可能后续进行查缺补漏把,如无必要,勿增烦恼。
Intro导言
主要参考文章2来进行我们简单的导入
基本问题
Transformer原本是NLP中的重要模型, 作为LSTM的后继者, 用于处理Seq2Seq的数据类型和情景, 若是要将Transformer运用到Vision的领域中, 首要的问题就是如何:
将Image作为序列化的Token输入Transform中 , 而达成这个目的主要有三种典型的方法:
- 像素点作为token,
- 使用VAE离散化图片作为token再输入
- ViT: 将图片切为一个个
Patch在经过线性的projector之后组成一个embedding表示进行交互
CNN的异同分析
差异分析和计算主要靠CKA向量相似度计算来计算模型和表征之间的差异,这里的理论分析暂且不赘述,后续有需求的话可参考论文Similarity of neural network representations revisited或当前文章.