Training Strategy
@Aiken 2020,
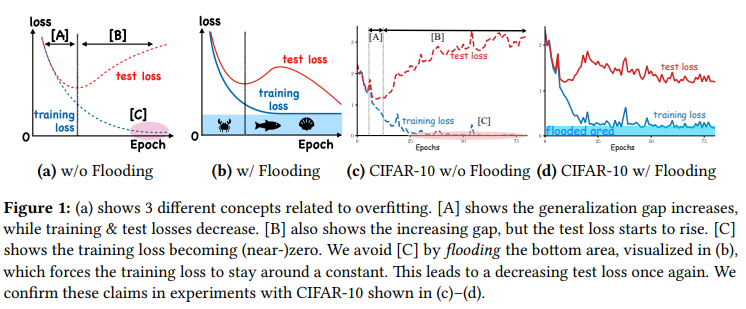
主要针对神经网络的训练过程中的一些基础策略的调整,比如当训练的曲线出现一定的问题的时候,我们应该怎么去调整我们训练过程中的策略。
参数调整过程中最重要的就是优化器(优化或者说是下降算法)和学习率(优化算法的核心参数),此外像是数据增强策略还是Normalization策略,都能极大的影响一个模型的好坏。
优化器
Some Material
实际上虽然有很多的优化算法,但是到最后最常用的还是 SGD+Mon 和 Adam两种:
Adam主要的有事在于自适应学习率,他对我们设计的学习率实际上没有那么敏感,但是在具体实验中往往不会有调的好的SGD那么好,只是在SGD的参数调整中会比较费劲。
但是有了根据patient调整lr的scheduler后,我们基本上可以使用SGD做一个较为简单的调整,只要设计好初始的lr的实验以及用来调整学习率的参数值。
学习率
$\omega^{n} \leftarrow \omega^{n}-\eta \frac{\partial L}{\partial \omega^{n}}$ 其中的权重就是学习率lr,
==Basic==
| 学习率大 | 学习率小 | |
|---|---|---|
| 学习速度 | 快 | 慢 |
| 使用情景 | 刚开始训练时 | 一定的次数过后 |
| 副作用 | 1. Loss爆炸 2.振荡 | 1.过拟合 2.收敛速度慢 |