
PyTorch Handbook 00 (Archive)
Basic Part基础设定部分
@AikenH 2020 + 2021
this part is about pytorch basic unit, help me to code deep learning better.
Tensor张量计算
两个tensor的数乘
计算两个tensor的矩阵乘法,注意其中的batch要相互对应,如果不考虑batch,就是另一个函数
1 | |
view和permute的使用实际上都是不改变原值,要用赋值的方式去做,主要是使用方式要对,一个是按照顺序去做。
张量命名
1 | |
类型转换
1 | |
维度堆叠
Stack,普通的维度堆叠的测试代码如下
测试代码如下,实际上dim=0就是基本的堆起来,dim=1就是按照行来堆,dim=2就是按照列来堆
1 | |
list的情况下的维度堆叠测试代码如下
相应的测试代码如下,实际上一般是按照dim=1来进行堆叠
1 | |
Cat
实际上应该也是类似的堆叠思路
基本的张量函数
torch.split() 划分tensor
torch.randperm进行list的乱序处理
1 | |
.fill_()按照输入的值对张量进行填充
选取划窗
nn.unfold拆解卷积中的划窗步骤
1 | |
Torch环境设置
pytorch中的随机种子初始化
yTorch 和 Python的随机数生成器就算随机种子一样也不会产生一样的结果。
我们可以这样来设置Pytorch的随机数种子:(通常和GPU一起使用)
1 | |
nn.parameter()
- Main idea:parameter的作用,主要是将参数和model绑定在一起,我们就知道这个模型中,可能需要训练的参数有哪些,可以需要进行训练的参数加进去,但是当我们想要freeze it的时候就使用detach或者直接修改require_grad来让参数不在接受训练就好了, require_grad是其中的一个属性。可以结合上面的代码分析。
- tensor变量是不可训练的,只有修改成parameter才能进行训练。
- 自带的网络结构中的一些weight和bias应该都是parameter的变量
nn.Softmax中的dim
其实没那么复杂,就和数据的维度是一样的,我们需要把那一个维度的数据之后的数据全部加起来处理就用哪个维度去做。
IMAGE = N* DATA,dim=1 说明dim = 0 的Channel 是需要被排外的。也就是我们的softmax是基于data进行的。可以找寻源码进行进一步分析解释。
测试、验证模块
基本编写
model.eval()和model.train()的区别
通常在模型测试的时候会执行model.eval()切换模型的状态,而在训练的时候会执行model.train(),model在这两个状态下的区别主要有:
在train状态下会启用BN和Dropout,而在eval不启用这两个模块;
- 启用BN指的是:用到每一个Batch数据的均值和方差;不启用则指的是使用整体的均值和方差(同时停止更新mean和var)
- 而对于Dropout来说:启用的时候指的是会随机进行dropout,而关闭的话就会用到全部的网络链接
with torch.no_grad()
上下文管理器,wrap起来的部分不会track grade
主要用于停止autograd模块的工作,被with包裹起来的部分会停止梯度的更新,得到进一步的加速把,因为我们实际上在验证的时候不会执行step()等操作,所以能够节省计算模型梯度的时间。
模型的保存和读取专题
@Aiken 2020
基于onenote笔记,我们知道关键在于如何自由的读取模型中的参数,并选择性的取出来。
pytorch 模型部分参数的加载_LXX516的博客-CSDN博客_pytorch 加载部分参数
1 | |
GPU相关的设置
@written by Aiken, 2020 this document is about Pytorch‘s CUDA, & GPU setting.
查看GPU状态
设置默认GPU设备
一般使用GPU之前,我们需要知道系统中有多少GPU设备,因为默认的GPU设备是0,而且,大家一般都直接使用这张卡,所以我们如果只使用单卡的话,切换一下默认的GPU设备,能够避免一定的冲突。
1 | |
设备基本信息
查看是否存在GPU,数量,类型
1
2
3
4
5import torch
# 查看是否存在GPU,数量,类型
torch.cuda.is_available()
torch.cuda.device_count()
torch.cuda.get_device_name(0)查看指定的GPU的容量和名称
1
2torch.cuda.get_device_capability(device)
torch.cuda.get_device_name(device)设置当前系统的默认gpu_devices,推荐使用os来设置(实际上是命令行中的操作)实际上是系统设定针对当前进程的可见GPU,其他的GPU会对当前的程序隐藏,所以默认的0
1
2os.environ['CUDA_VISIBLE_DEVICES'] = "id" #推荐用法
# 可以在vscode的launch.json中设置env注意事项:该命令需要在所有调用了CUDA的代码、子程序之前,包括
import,所以很多代码的import都是在main()中的。
GPU使用率优化(注意事项)
缓存爆炸问题
GPU使用途中需要注意的地方,在每次iteration之后记得清除在GPU中占用的memory,cache等,不然有时候会导致缓存和内存的递增和爆炸。
具体操作:
1 | |
运行效率优化
cudnn.benchmark、pytorch论坛 pytorch中文网、zhihu究极分析文
基本使用思路:
在程序的开始,让cudnn花费一点额外的时间,找到适用于当前配置的最佳算法,从而优化运行效率。
注意事项:
但是如果我们的input_size在每个iteration都存在变化的话,那么每一个iteration都要执行一次搜索,反而得不偿失。
具体操作
1 | |
设置使用GPU的方式
设置相应的随机种子
1 | |
CUDA转换
使用.cuda()来对模型,数据,Loss进行赋值,或者使用to_devices()来设置到相应的GPU设备
将模型转化到cuda中要在优化器的建立之前执行,因为optimizer是对于模型建立的,对模型执行cuda后已经和原本的参数和模型都不是同一个了,所以一定要在建立优化器之前就对模型进行Cuda 的转化。
是否要对loss转换到CUDA,取决于一下的两种情况:
- 损失函数是Functional:这样的话只要传入的参数是CUDA的就会再CUDA上计算
- 损失函数是Class with params:如果类内有参数的话,也要转换到CUDA才能一起在CUDA上计算
1 | |
多GPU并行
主要使用的命令nn.DataParallel()
1 | |
CPU
偶然会由于pin_memory 的设置来致使CPU的不正常运行(满载等等),并非总是这样。
核心和线程数设置
限制或增加pytorch的线程个数!指定核数或者满核运行Pytorch!!!_lei_qi的博客-CSDN博客
1 | |
网络定义模块
数据定义模块
利用TorchVision读取本地数据
torchvision.datasets.imagefolder() 这个函数实际上能代替我们之前写的函数,但是由于自己写的有一部分统一规则可以使得我们的自定义程度很高,所以目前我们在绝大多数情况下不使用该方法来进行替代。
但是由于是一个重要的函数,我们在这里还是介绍一下该工具的使用方式:
torch 自定义Dataset后的使用
- 自定义dataset的继承以及后续调用需要注意的是不能忘记将其转换成dataloaer,然后进行iter命令的执行。
- 也可以用enumerate函数来进行调用,就是记得调用的格式是什么就好
- 可以参考basicunit中的对shuffle的认知对该函数进行进一步的理解。
1 | |
Dataloader中的transformer():
疑惑解答 用compose集成的所有transform,都会应用,有个to_tensor,切to_tensor会自动转换PIL中的channel和数值范围。
- compose中的变换组合的顺序关系
- PIL处理的图像变换(比如数据增强之类的方法)
to_tensor()- 处理tensor的方法:
normalize
示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13data_transforms = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip().
transforms.ToTensor(),
transforms.Normalize([a,b,c],[A,B,C])])
# 然后直接加入dataset中的参数,或者是我们自定义的部分
# 在dataset中的写法如下,我们可以在自己的dataset中进行定义
if self.transformer is not None:
img = self.transform(img)
# 具体的源码细节表现如下
for t in self.transforms:
img = t(img)
return img
Dataloader中的参数
shuffle机制
主要解决问题:
- 是否每次调用的时候都进行随机的操作,还是只有在初始化的时候才进行随机
- 两种不同使用Dataloader的方式是否会对shuffle的方式进行区分
结论:
- 每次对dataloader进行重新调用(重新放到enumerate),或者重新定义iter,都会重新进行shuffle。
num_worker
参考资料1 参考资料2:pytorch中文文档👇
num_workers (int, optional) – 用多少个子进程加载数据。0表示数据将在主进程中加载(默认: 0)
用num_worker个子进程加载数据,所以能够将数据在主进程展示还没有调用到该数据之前就将后续的数据存入RAM,所以在数据读取上会比较快,但是占用的RAM和CPU资源会比较大。
samples:
torch.utils.data - PyTorch 1.9.0 documentation
一文弄懂Pytorch的DataLoader, DataSet, Sampler之间的关系
官方的解释是:
sampler (Sampler or Iterable, optional) – defines the strategy to draw samples from the dataset. Can be any Iterable with len implemented. If specified, shuffle must not be specified.
定义从数据集(还是最开始的哪个数据集,不能是额外的数据集)中提取样本的策略:是否能通过该Method去实现Hard-Task或者像Meta-Task一样的采样过程呢?从Meta-Transfer-Learning中看来是可以的,可以学习一下它的写法。
collate_fn()
collatefn的作用就是将一个batch的数据进行合并操作。默认的collatefn是将img和label分别合并成imgs和labels,所以如果你的__getitem方法只是返回 img, label,那么你可以使用默认的collate_fn方法,
但是如果你每次读取的数据有img, box, label等等,那么你就需要自定义collate_fn来将对应的数据合并成一个batch数据,这样方便后续的训练步骤。
- 编写collate_fn可以参考qidong的文章主要是接受数据和标签列表,将其整合成一个矩阵的形式;
- 如果对传参有需求,可以参考
lambda的形式或者是类定义的形式去传入
1 | |
using collate_fn, we can augment the dataset more flexible.
编写模型
模型基本单元
nn.conv2D:
- kernel_size[1]应该指的是卷积核的宽(不一定都是正方形的)
模型参数共享:
pytorch:对比clone、detach以及copy_等张量复制操作
1 | |
网络定义的方式对比分析
@Aiken 2021 主要对比的是ModuleList和Sequtial
结论:通常使用的话,这里我个人推荐使用的是sequtial结合collection中的orderdict来构建的方法,这个方法集成了内部的forward,同时通过`orderdict也能给print带来更好的可视化效果。
但是还是有一些特殊的使用场景我们会用到ModuleList
详解PyTorch中的ModuleList和Sequential
主要区别:
- nn.Sequential内部实现了forward函数,因此可以不用写forward函数。而nn.ModuleList则没有实现内部forward函数。
- nn.Sequential可以使用OrderedDict对每层进行命名,上面已经阐述过了;
- nn.Sequential里面的模块按照顺序进行排列的,所以必须确保前一个模块的输出大小和下一个模块的输入大小是一致的。而nn.ModuleList 并没有定义一个网络,它只是将不同的模块储存在一起,这些模块之间并没有什么先后顺序可言。网络的执行顺序按照我们在forward中怎么编写来决定的
有的时候网络中有很多相似或者重复的层,我们一般会考虑用 for 循环来创建它们,而不是一行一行地写,这种时候就使用ModuleList:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class net4(nn.Module):
def __init__(self):
super(net4, self).__init__()
layers = [nn.Linear(10, 10) for i in range(5)]
self.linears = nn.ModuleList(layers)
def forward(self, x):
for layer in self.linears:
x = layer(x)
return x
net = net4()
print(net)
# net4(
# (linears): ModuleList(
# (0): Linear(in_features=10, out_features=10, bias=True)
# (1): Linear(in_features=10, out_features=10, bias=True)
# (2): Linear(in_features=10, out_features=10, bias=True)
# )
# )
基本使用:
nn.sequential
可以通过list和*以及add moudle来进行迭代的定义,同时这种定义方式,会方便我们的重复注册
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24from collections import OrderedDict
class net_seq(nn.Module):
def __init__(self):
super(net_seq, self).__init__()
self.seq = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
def forward(self, x):
return self.seq(x)
net_seq = net_seq()
print(net_seq)
#net_seq(
# (seq): Sequential(
# (conv1): Conv2d(1, 20, kernel_size=(5, 5), stride=(1, 1))
# (relu1): ReLU()
# (conv2): Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1))
# (relu2): ReLU()
# )
#)nn.ModuleList:与python自带的List不同的地方在于他会自动将网络注册到Parameter中,成为网络,但是需要自己去编写forward过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33class net_modlist(nn.Module):
def __init__(self):
super(net_modlist, self).__init__()
self.modlist = nn.ModuleList([
nn.Conv2d(1, 20, 5),
nn.ReLU(),
nn.Conv2d(20, 64, 5),
nn.ReLU()
])
def forward(self, x):
for m in self.modlist:
x = m(x)
return x
net_modlist = net_modlist()
print(net_modlist)
#net_modlist(
# (modlist): ModuleList(
# (0): Conv2d(1, 20, kernel_size=(5, 5), stride=(1, 1))
# (1): ReLU()
# (2): Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1))
# (3): ReLU()
# )
#)
for param in net_modlist.parameters():
print(type(param.data), param.size())
#<class 'torch.Tensor'> torch.Size([20, 1, 5, 5])
#<class 'torch.Tensor'> torch.Size([20])
#<class 'torch.Tensor'> torch.Size([64, 20, 5, 5])
#<class 'torch.Tensor'> torch.Size([64])
Detach & detach_
这个模块在后续进行pretrain或者transfer的时候应该会经常被用到,所以这种方法还是需要熟练掌握的
detach是产生一组不需要下降的“Copy”:如果要修改原值的话就要进行赋值操作。
detach_则是修改本身参数的属性(require_gradetc.)执行函数就能将参数修改为不需要下降的情况,不需要执行赋值处理。
模型调用的Tips
使用list进行多模型的混合调用
由于python默认的是引用赋值,也就是浅拷贝的方式?
通过list来进行模型的批量构建,通过list来将模型整合起来,是不会使用额外的存储空间的,它们指向同一个地址。基于这样的假设,我们可以基于list来简化代码,通过LOOP来执行,相关的调用操作,比如生成器或者预测之类的,来简化代码结构。
1 | |
Warm-up factor
对于这一部分的概念我还是有些不了解,是否和冷启动和热启动的概念是相关的,如果不是的话,顺便就学习一下冷启动和热启动的概念。
具体解析:
pytorch学习率调整方法(warm up) ,label smooth、apex混合精度训练、梯度累加_xys430381_1的专栏-CSDN博客
神经网络中 warmup 策略为什么有效;有什么理论解释么?
Weight decay(L2)
实际上就是对权重进行L2正则化,让权重衰减到更小的值,在一定程度上减少模型的过拟合问题,所以权重衰减实际上也叫L2正则化。
具体的数学推导后续将集成到GoodNote笔记上,将正则化单独作为一个模块去整理。
权重衰减(L2正则化)的作用
作用: 权重衰减(L2正则化)可以避免模型过拟合问题。
思考: L2正则化项有让w变小的效果,但是为什么w变小可以防止过拟合呢?
原理: (1)从模型的复杂度上解释:更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合更好(这个法则也叫做奥卡姆剃刀),而在实际应用中,也验证了这一点,L2正则化的效果往往好于未经正则化的效果。(2)从数学方面的解释:过拟合的时候,拟合函数的系数往往非常大,为什么?如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
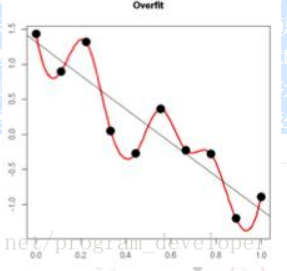
image-20201205175236273
内容来自: 正则化方法:L1和L2 regularization、数据集扩增、dropout
Learning Rate Decay
当我们选择了一个合适的lr,但是损失训练到一定程度以后就不再下降了,就在一个区间中来回动荡,可能是出现了一下的问题:
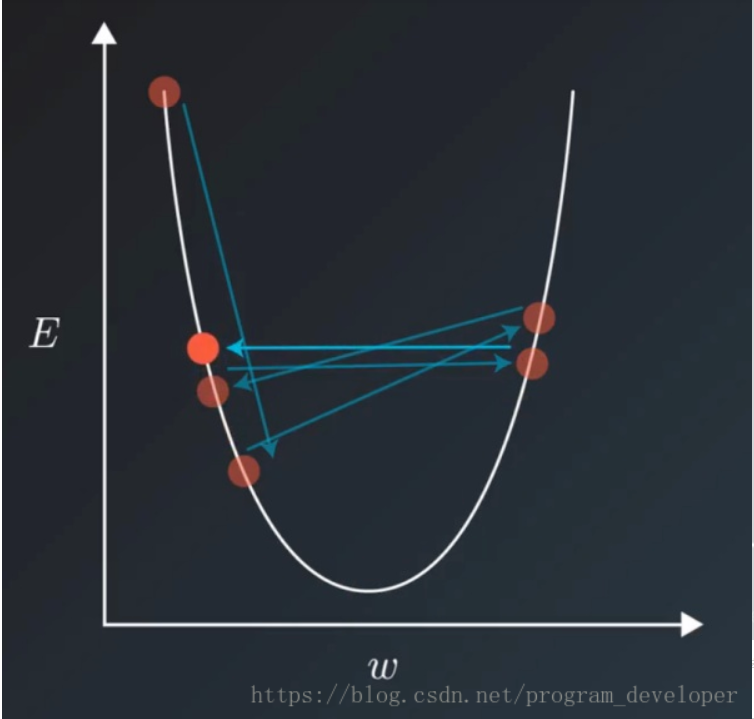
image-20201205175605729
对这种问题的解决就是通过学习率衰减来实现的:将学习率随着训练的进行来进行衰减,这个方法就比较直观了。具体的方法描述可以在 ../project_note/训练参数调整策略.md中找到。
也可以参考如下连接:详细理解pytorch的六种学习率pytorch
损失函数
nn中自带的Loss Function比如说MSE之类的,计算出来的值本身就已经对batch取了平均值,同时我们进行交叉熵的计算的时候,我们不需要实现对他进行softmax,因为再CE中已经集成了softmax的操作。
CrossEntropy交叉熵
这里会介绍一下Pytorch中的CE损失的具体实现的方法,这里给出三种方式的对比。
1 | |
可以发现三种方式计算出来的损失是一样的,这就说明了我们在计算的时候要记住,ce中是自己集成了softmax的操作,同时在Nll中是存在了取negative的操作的。按照这个操作手册去实现自己相应的损失函数设计
优化器设计
这一部分主要添加一些常见的优化器参数的设置包括SGD和Adam的对应设置,主要介绍一下设置Adam
实际上Adam的设置对于学习率来说没有那么敏感,但是我们还是要了解参数的意思才知道怎么去设置该优化器
模型参数初始化和架构查看方法
实际上对参数初始化也就是需要对整体的架构进行遍历,所以这两个会归为一个子课题
参数的初始化方法只要使用如下的方式,无论我们采取那种定义的方式,,都能遍历到其中所包含的所有网络层
1 | |
children、modules、parameters:
model.modules会遍历model中所有的子层,而children只会遍历当前层,也就是最外层的情况,所以如果要进行参数的初始化的话,最好是用类内或者类外的两种方法来实现初始化
parameter返回的是模型的所有参数,所以初始化最好使用的是`modules,而parameter一般用来初始化参数
用numel与parameters计算参数的个数
1 | |
初始化原则:(继续调研)
pytorch中的参数初始化方法总结_ys1305的博客-CSDN博客_pytorch 参数初始化
Batch-Normalization:Batch Normalization详解 - shine-lee - 博客园 (cnblogs.com)
- conv:
kaming_normal_ - fc:
constan_,xvaier - bn:
normal_\constant|
典型的参数初始化方法
EnAET中可以看到参考的源码如下,需要注意的是,BN中只有两个参数,所以不需要进行参数的初始化,或者直接置0、1即可.
1 | |
数据类型和维度
在算法编写的过程中,数据的类型和维度的对齐和channel是很重要的,在这里也很容易出现很多的bug,在这里做一个信息的汇总
输入数据的通道
结论:pytorch网络输入图片的shape要求通道是channel_first(通道在前)的,所以如果我们的图片不是这样的话,我们就需要执行相应的变化。
TODO:整理各种数据读取方式读入的channel first 或是 last : skimage,PIL,numpy
整理相应的各种数据类型进行transpose(numpy)的方式
1 | |
标签的形式转换one-hot
进行训练之前要将数据转化为onehot的形式,才能输入训练,而且一般因为是batch_size的形式,所以我们需要转化为矩阵形式的onehot,不能用单个label的转化方法。
1 | |
Visualize 可视化部分
Tensorboard in Pytorch
@Aiken H 2021 review 之前这一部分的projection和model都没有成功显示,这次在新框架中展示一下。
详解PyTorch项目使用TensorboardX进行训练可视化_浅度寺-CSDN博客_tensorboardx
使用 TensorBoard 可视化模型,数据和训练 (apachecn.org)
在pytorch教程中的Projection可以结合后续输出的Feature使用来分析相应的聚类和分类可靠性
可以尝试使用,教程写的很简单易懂。
Histogram 直方图参数统计
一般来说用来统计模型中间的一些参数的分布情况,具体的使用在训练的epoch之间,和val是一个比较类似的机制,具体的代码样例如下:
1 | |
Embedding Projection
@Aiken H 2021 这一部分可能才是神经网络的特征分布的可视化图。
下面这个是Google的Embedding Projection,需要上传.tsv保存的数据,但是实际上就是Tensorboard上也有集成的功能
Embedding projector - visualization of high-dimensional data
Visualizing Data using the Embedding Projector in TensorBoard
PR_CURVE
这里会贴上pr_curve中需要的参数和我们这边编写的示例代码
Add_TEXT
换行失效问题, 这是因为在Tensorboard中这一部分使用的是Markdown的格式, 所以在这里我们在换行符\n之前, 需要保留两个空格才能实现真正的换行
ADD_Figure
有时候我们会发现我们编写的figure在step中没有全部现实出来, 这是我们可以通过启动命令来展示所有的图片
1 | |
可视化神经网络热力图(CAM)
@Aiken2020 为了便于查看神经网络的输出,对于图像的哪一部分更加的侧重,也就是指导网络进行分类的主要是图像的哪些区域,(相应的也可以按照类似的方法查看Attention Network的效果把),就想着可视化一下CAM。看指导分类的高响应区域是否落在核心区域。
参考链接:
算法原理
其计算方法如下图所示。对于一个CNN模型,对其最后一个featuremap做全局平均池化(GAP)计算各通道均值,然后通过FC层等映射到class score,找出argmax,计算最大的那一类的输出相对于最后一个featuremap的梯度(实际上就是最后一个map中哪些对于分类的变化其更大的作用,也就是类似权重的机制),再把这个梯度可视化到原图上即可。直观来说,就是看一下网络抽取到的高层特征的哪部分对最终的classifier影响更大。
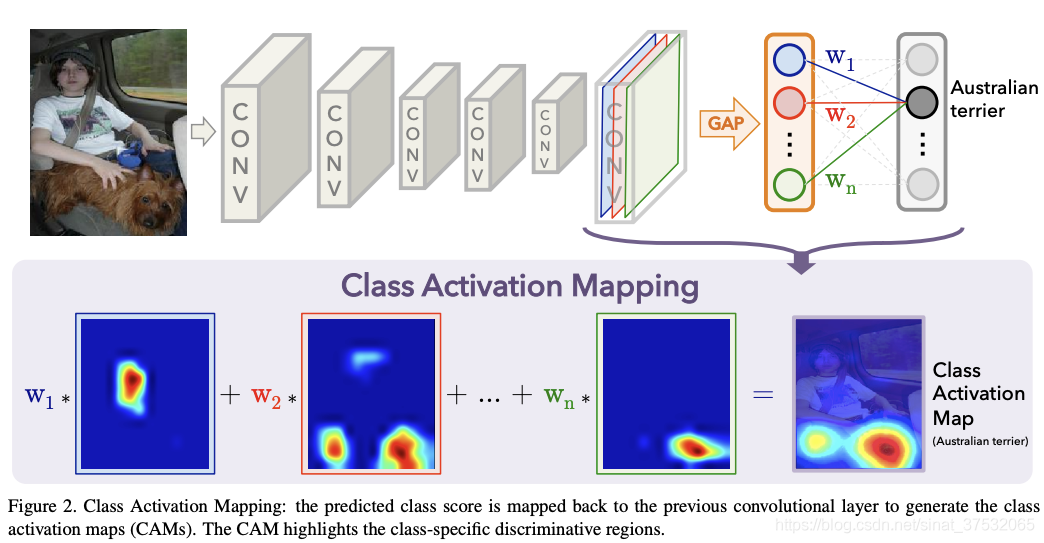
Quote: 找到了一篇基于Keras的CAM实现,感谢:
https://blog.csdn.net/Einstellung/article/details/82858974 但是我还是习惯用Pytorch一点,所以参考着改了一版Pytorch的实现。其中,有一个地方困扰了一下,因为Pytorch的自动求导机制,一般只会保存函数值对输入的导数值,而中间变量的导数值都没有保留,而此处我们需要计算输出层相对于最后一个feature map梯度,所以参考https://blog.csdn.net/qq_27061325/article/details/84728539解决了该问题。
代码实现:
1 | |
BUGs
如果想要展示出所有step的图片, 我们可以在命令行里执行tensoroard的时候执行下列命令.
1 | |
DEBUG
1.ImportError: cannot import name ‘PILLOW_VERSION’
PIL版本过高,换低就可以,他不配是一个棘手的问题
pip install Pillow==6.2.2 --user
2.模型参数&计算量统计 and Debug输出
- 用来计算模型构建中网络的参数,空间大小,MAdd,FLOPs等指标,count_params很好写,然后剩下的计算我们交给两个第三方的库来实现:
torchstat,thop
1 | |
- 也可以使用
torchsummary来查看各层输出的数据的维度数目
1 | |
- 相应的Debug还可以使用
torchsnooper进行:变量的类型和维度追踪这个模块通过@xxxx修饰器的方法调用在指定的method前面,能够在训练过程中输出一些参数值的类型和数值变化的较为详细的信息。个人理解的最佳使用环境是,用于调试或者监控类型之间的错误。
1 | |
3.PyTorch加载预训练模型
具体错误:在于模型Dict中的Key和预训练model中的Key不对应,无法匹配。
1 | |
问题分析:
situation1:可以看到前面多了module这个str,这一般是由于其中一方使用了多GPU训练后直接保存的,也就是DataParallel模式下导致的不匹配问题。
solution1: 参考资料
- load模型后去掉多余的参数在事先的时候发现这个方法还是存在问题的,并不是简单的dict封装的结构,所以没法这样简单的进行赋值处理:x:
- 用空白代替module,暂时还没尝试,但是我觉得会遇到和第一个一样的问题:x:
:zap:最简单的方法:加载模型后将模型进行DataParallel,再进行数据的转化,将数据进行并行化。具体的操作如下
1
2
3
4model.cuda()
# 将ids设置成拥有的GPU即可,但是不知道单GPU的情况可不可以实现这种情况
model = nn.DataParallel(model, device_ids=None)
Situation2: 保存模型格式为.pth.tar,无法载入训练好的模型
Solution2:
原因是因为被保存的模型是在高版本的pytorch下实现的,但是再低版本中读取的模型是.pth格式的,就会出现版本冲突。
解决方法如下👇:
1 | |
xxx is a zip archive(did you mean to use torch.jit.load()?)
使用低版本的Torch去Load高版本(>1.6)保存的模型(.pth.tar)遇到的问题,
这种错误,主要是模型的版本冲突。
解决办法:在高版本的环境中,重新load模型,然后直接save,在保存的时候添加参数
torch.save(model.state_dict(),model_path,_use_new_zipfile_serialization=False)
就可以保存成.pth的模型,也能在低版本的torch环境中使用了
4.some of the strides of a given numpy array are negative.
ver:torch1.2 这个问题可能会在后续的版本中被优化。
Situation:
https://www.cnblogs.com/devilmaycry812839668/p/13761613.html
问题出现在flat操作中,反向切片[::-1]会导致数据存储在内存上不连续,在旧版本中无法实现,对这样数据进行存储。
Solution1:
所以在执倒排切片的时候执行,img2 = np.ascontiguousarray(img) 使得数据在内存空间上连续。
Solution2:
或者执行倒排切片的时候,直接return img.copy()
5.读取loader的时候图像的大小不一
使用Crop对图像进行处理的时候,不注意的话就是会出现这样的问题,图像的size随机改变,导致的输出不统一。也可能是Crop函数写的有问题。
bug info如下
1 | |
Solution:
resize,spp,padding,adaptiveMaxPooling(自适应的pooling,pooling到指定的size(channel除外))
6.bus error dataloader num_worker
原因暂时还不是太清楚,但是我们可以把num_worker设置为0 来解决这个问题.jpg
7.bus error:insufficient shared memory(shm)
这种原因通常会在docker环境中出现,由于未指定shm容量大小,比如ipc=host之类的命令,就会导致docker的shm只有64m,于是在运行的时候就会出问题。这种情况下只能重新run docker(目前只找到了这个方法)。
如果要妥协的话,就只能试着减小batch_size。但是随着模型的设计上,这其实不是一个可以逃避的问题,也会增加莫须有的其他成本,所以。
8.训练过程中Cache和Memory的占用逐渐升高
主要的体现是:逐渐升高这一点,而不是稳定的情况;
有点玄学,但是在这种情况下,我们在每个iteration结束的时候使用清楚显存的函数,竟然就能进行控制了,虽然我不知道为啥清楚显存的函数会顺便连内存中的cache也一起清除了,但是就是,学。
1 | |
9.梯度爆炸问题,算法没有学习效果
梯度爆炸问题,分析可能出现存在的问题:
- 某一部分的学习参数可能的lr过高,权重过高,导致误差快速传播。
- 问题的复杂度过高,算法overpower了把。
针对于第一点的话,我们参考工程笔记中的学习率调整策略即可。
如果是问题的复杂度过高,那么可能是问题对于我们的模型来说已经overpower的,我们可能需要去加深网络的层数,或者对网络进行进一步的设计和对数据的分析问题。
10.类型转换问题汇总
- 比如
scatter_需要将数据从int32的格式转换成int64,我们要掌握一下在Pytorch中进行数据类型转换的技巧。 - Expected object of scalar type Float but got scalar type Double for argument #2 ‘target’ 数据类型不匹配,一个是np.float32,另一个是64
参考解决方案:重要 Expected object of scalar type Long but got scalar type Float for argument
希望得到的是Long型标量数据,但是得到了Float型的数据(实际上可能是我们进行测试的时候使用了小数带来的,但是我们也能将其转化就是了)1
2
3Longtensor()
type(torch.longtensor)RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.DoubleTensor) should be the same
RuntimeError: Input type (torch.cuda.ByteTensor) and weight type (torch.cuda.FloatTensor) should be the same问题实际上都是和权重的数据类型不匹配,需要将字节型或者是FLoat型向Weight的数据类型转换,但是可能这里的问题实际上出现在就是我们导入的数据类型是不正确的。还是使用type()命令来进行数据类型的转换,但是关键还是:检查输入数据的类型以及数值范围,同时看看在进行dataloader的时候有没有指定to_tensor的变换等等
进行数据转换的几种方式
使用函数
tensor1.type_as(tensor2)将1的数据类型转换成2的数据类型。1
2
3
4tensor_1 = torch.FloatTensor(5)
tensor_2 = torch.IntTensor([10, 20])
tensor_1 = tensor_1.type_as(tensor_2)tensor.type(torch.IntTensor)tensor.long(),tensor.char(),tensor.int(),tensor.byte(),tensor.double()tenosr.to(torch.long)
11.数据维度不对应问题汇总
multi-target not supported at问题实际上可以翻译成:维度上和交叉熵损失函数的需求不对应。在使用交叉熵损失函数的时候,target的形状应该是和label的形状一致或者是只有batchsize这一个维度的。如果target是这样的【batchszie,1】就会出现上述的错误
1
使用squeeze()函数降低维度
12.取出具体数值时候的问题
- RuntimeError: Can’t call numpy() on Variable that requires grad. Use var.detach().numpy()对于输出的结果要转换成具体的数值的时候,如果我们后续还需要这个数值的梯度,就不能转换到
cpu后再转换到numpy,就好比说,我们要取出Loss的时候,我们可以直接使用item()取出具体的数值,而不需要转到CPU上
13.CPU占用99%
问题描述:使用torch自带的dataset中的cifar10的时候,在每个epoch结束的时候,CPU占用率高达99%,并不随着num_workder而改变,问题可能由于pytorch开辟了太多的线程
windows10下pytorch的GPU利用率低,占用率低_stay_zezo的博客-CSDN博客
可能是由于GPU运算太快了,启用了多线程进行加载数据,这种时候启用pin_memory=true 能起到一定的作用把,加快一点数据读取。
最终解决方案 :pin-memory=false 反正原因很神奇,但是最终就是因为这个解决的,可能是因为memory超了,所以每次都需要重新empty_cache 重新装进页,所以反而加重了CPU的负担
14. 预测值全为0,模型收敛到奇怪的地方,损失保持一致(全均等)
这种情况通常是由于模型设计中存在一点问题:
比如这次是由于模型中fc后面添加了relu,这样导致输出的负值全被抑制了,导致学习出现了严重的错误后果。
15.模型部分: 训练中模型准确率不上升
由于框架已经验证过是可以进行正常训练的,在这种情况下出现模型的准确率不上升可能是由于模型本身设计(内部代码编写)上的问题。
16. On entry to SGEMM parameter number 8 had an illegal value
Tracing failed sanity checks!
Graphs differed across invocations!
fc的问题,输入fc和对应的网络输入层不一致,检查阶段数目和feature输出的特征维度
17. CUDA error: device-side assert triggered CUDA kernel errors might be asynchronously reported at some other API call
这个问题的出现的根本原因在于:
维度不匹配:标签的dimension 超出了全连接层最后输出的dimension,这一部分错误的触发,和Loss的计算,Acc的计算,有着强烈的相关关系。
为了解决这个问题,我们在训练相关的验证和训练环节,需要保持训练数据集和验证数据集在类别数目上的一致性,而在我们需要对数据集外的数据进行测试的时候,我们避免进行Loss的计算,在对Acc进行计算的时候,也尽量避免Torch中的自有库,避免产生该类的问题/
RuntimeError the derivative for target is not implemented
问题通常出现在损失计算的过程中,这个错误是由于我们在损失中的第二项 targets不应该有梯度,但是在这个地方却存在梯度导致的.
在这里我们可以通过仅仅取出 tensor的data或者使用detachandcopy来进行数值的传递
Only Tensors created explicitly by the user (graph leaves) support the deepcopy protocol at the moment
该错误是由deepcopy和require_grad, require_fn同时构成, 如果我们对一个需要计算梯度的非叶子节点进行deepcopy就会触发这个错误。
如果我们需要对这个数据进行存储的话,我们可以执行1
save = copy.deepcopy(feature.data.cpu().numpy())
PyTorch Handbook 00 (Archive)



