Windows Configuration01 WSL2
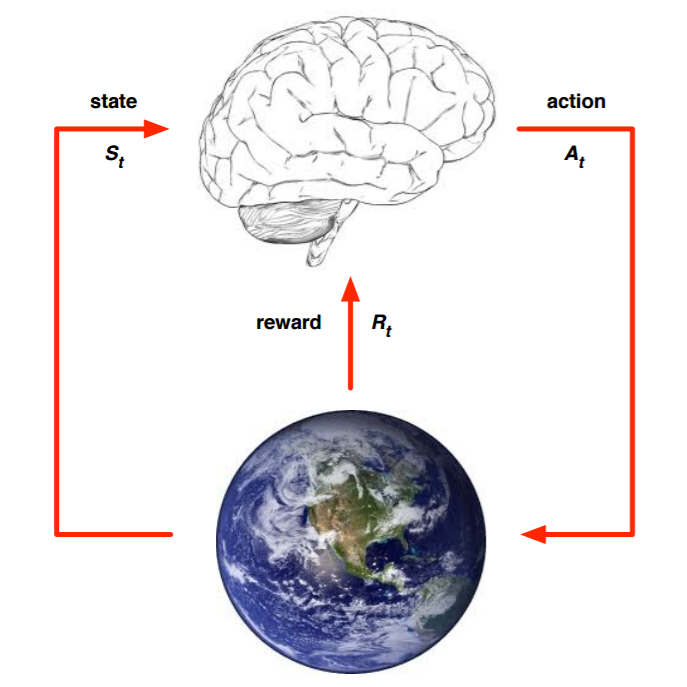
WSL(Windows Subsystem Linux) 将 Linux 环境部署在 Windows 中,Linux 环境在补全了 Windows 开发上的不足之外(Bash 等),还有以下的几个特性极大的便利开发和日常使用,因此强烈推荐启用并安装。
- win11 中 wsl2 已经支持相应主机的 cuda,便利了机器学习的开发;
- 子系统中通过/mnt 挂载了 windows 的磁盘,可以通过子系统访问和管理 windows 环境;
- windows 资源管理器可访问和管理子系统中的文件
- 支持 windows 打开子系统中的 GUI 应用
无论是将 windows 和 linux 分别作为日常和开发的环境来隔离,还是两个协同去做开发和日常,都是一个比较不错的选择,下面就介绍一下如何安装和使用 WSL2。
- 开始之前可以参考 windows terminal 安装一下这个官方的终端模拟器,在 windows 上的表现是比较优秀的
- 如果是考虑在 windows 环境开发的话,也可以参考这个[windows],里面有我个人推荐的一些应用。
启用并安装 WSL2
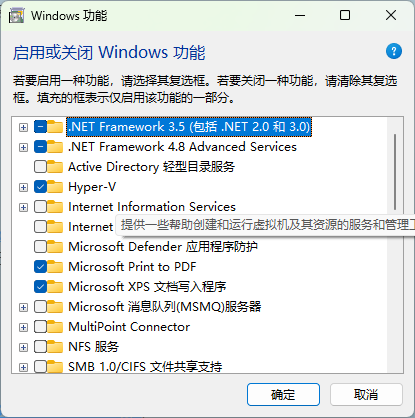
安装和启用 WSL2 需要在 windows 的服务中勾选 Hyper-V 和 Windows Subsystem Linux 支持两个选项,具体操作如下:
- Win + S 搜索 “功能”,打开启用或关闭 windows 功能
- 启用对应功能,功能安装完毕后即可

- 安装 linux 发行版可以在 windows store 安装,也可以通过如下的命令进行安装:
1 | |