
YOLOv4
@AikenHong 20200726
基于YOLO v4 掌握一些CV方面训练的Trick,同时针对Typora的使用进行一个熟悉掌握。GITHUB CODE
一些相关的参考资料
⚡️https://zhuanlan.zhihu.com/p/150127712
⚡️https://www.zhihu.com/question/390191723/answer/1177584901
本文中一些其他的收获
• 其他可替代的Object Detection的SOTA算法有哪些
• BoS,BoF方法
• 简直是一个Tricks的综述
Abstract
本文对近期再CNN上的一些Feature方法进行了尝试组合,并实现了新的SOTA,其实就是一些通用的**Trick**的组合尝试,包括
• 加权残差连接(WRC)
• Cross-Stage-Partial-connection,CSP
• Cross mini-Batch Normalization,CmBN
• 自对抗训练(Self-adversarial-training,SAT)
• Mish 激活(Mish-activation)
• Mosaic 数据增强
• DropBlock 正则化
• CIoU 损失
基于该文章我们可以了解一下这些方法的主要思路和后续的应用价值。YOLOv4 更快,更准确,只需要比较小的计算需求即可

INTRODUCTION
• 更快更强,从速度和准确率,以及训练需求上提升实际运用价值
这里有一些其他的SOTA可以列一下:EfficientDet、ATSS,ASFT,CenterMask
• AP:平均准确率 FPS:每秒传输帧率嘛?
主要贡献可总结如下
建立了一个高效强大的目标检测模型。它使得每个人都可以使用 1080Ti 或 2080Ti 的 GPU 来训练一个快速准确的目标检测器。
验证了当前最优 Bag-of-Freebies 和 Bag-of-Specials 目标检测方法在检测器训练过程中的影响。
Bag-of-freebies: 仅仅只增加training cost或者只改变training strategy的方法。典型例子:数据增强
bag-of-specials: 增加少量推理成本,但能提高准确率的插件模块(**plugin modules)和后处理方法(post-processing method)**被称为BoS。修改了 SOTA 方法,使之更加高效,更适合单 GPU 训练。这些方法包括 CBN、PAN、SAM 等。
PAN: Path aggregation network for instance segmentation
SAM: CBAM: Convolutional block attention module
RELATED WORK

基本架构
object detector 通常由backbone和head两部分构成,其中backbone是再imagenet上预训练的骨架
- GPU: VGG [68], ResNet [26], ResNeXt [86],or DenseNet [30]
- CPU: SqueezeNet [31], MobileNet[28, 66, 27, 74], or ShuffleNet [97, 53]
head则是用来预测物体类别和边界框的网络架构
- One-Stage: YOLO [61, 62, 63], SSD [50],and RetinaNet [45]
- Anchor-free:CenterNet [13], CornerNet [37, 38], FCOS [78], etc.
- Two-Stage: R-CNN [19] series: fast R-CNN [18], faster R-CNN [64], R-FCN [9],and Libra R-CNN [58] anchor-free: Rep-Points[87]
近年来在backbone和head之间插入neck用以收集不同stage的feature-maps FPN、PAN、BiFPN、NAS-FPN、etc.
To sum up, an ordinary object detector is composed of several parts:

Bag-of-freebies:
仅仅只增加training cost或者只改变training strategy的方法。典型例子:数据增强
- 目标检测中的多种数据增强:包括对图像遮挡的处理,随机擦除和基本的数据增强,也有feature map中类似的操作
- 解决数据存在偏差的问题:例如数据不平衡
- BoundingBox回归方法:MSE-》IoU,也就是一些边界回归上的损失函数,CIoU、GIoU、DIoU、MSE等
Bag of specials
增加少量推理成本,但能提高准确率的插件模块(plugin modules)和后处理方法(post-processing method)被称为BoS。
Plugin modules:例如扩大接受域,引入注意力机制,增强特征集成能力等等,
post-processing method:筛选预测结果的方法
扩大接受域:SPP(将SPM集成到CNN中)、ASPP、RFB。
Attention module:
Channel-Wise:SE
Point-Wise:SAM
feature integration:
将低层的物理特征集成到高层语义特征
- skip connection、hyper-column
- FPN出现后:SFAM、ASFF、BiFPN
- activation function:
- 解决softmax和sigmoid中出现的梯度消失问题:ReLU、LReLU、PReLU、ReLU6、SELU、Swish、hard-Swish、Mish
post-process:
– NMS用于处理预测同一对象的一些BBox,并保留响应速度更快的BBox
– 还有一些相关变体
– anchor-free的方法不需要这部分
Architecture
找到最优的input network resolution,conv layer number, the parameter number(filter size2 * filters * channel / groups) 以及 the number of layer outputs(filters)之间的最有平衡
挑选能够增加感受域的额外单元(additional block),以及最佳参数聚合方法
YoloV4 的基本目标是提高生产系统中神经网络的运行速度,同时为并行计算做出优化,而不是针对低计算量理论指标(BFLOP)进行优化。YoloV4 的作者提出了两种实时神经网络:
(Backbone)
• 对于 GPU,研究者在卷积层中使用少量组(1-8 组):CSPResNeXt50 / CSPDarknet53;
• 对于 VPU,研究者使用了分组卷积(grouped-convolution),但避免使用 Squeeze-and-excitement(SE)块。具体而言,它包括以下模型:EfficientNet-lite / MixNet / GhostNet / MobileNetV3。
分类器和检测器需求上的区别:
架构选择part1
CSPDarknet53<-最终选择的一个较好的模型(backbone)
在cspdarknet52上添加了spp block,用PANet取代v3中的FPN,yolov3作为head
架构选择part2:selection of BoF or BoS
CNN的优化通常有这几个方面:
- Activations: ReLU, leaky-ReLU, parametric-ReLU, ReLU6, SELU, Swish, or Mish
- Bounding box regression loss: MSE, IoU, GIoU,CIoU, DIoU
- Data augmentation: CutOut, MixUp, CutMix
- Regularization method: DropOut, DropPath [36], Spatial DropOut [79], or DropBlock
- Normalization of the network activations by their mean and variance:
Batch Normalization (BN) [32], Cross-GPU Batch Normalization (CGBN or SyncBN) [93], Filter Response Normalization (FRN) [70], or Cross-Iteration Batch Normalization (CBN) [89]
- Skip-connections: Residual connections, Weighted residual connections, Multi-input weighted residual connections, or Cross stage partial connections (CSP)
架构选择Part3 :额外的改进
使得架构能够更适合在单个GPU上进行运算,设计了一些改进
• 新的数据增强方法:mosaic &SAT(self-Adversarial Training)
• 在遗传算法中使用了最佳的超参数
• 修改SAM,PAN和CmBN使得设计适合更有效的训练和检测
Mosaic(马赛克)数据增强,把四张图拼成一张图来训练,变相的等价于增大了mini-batch。这是从CutMix混合两张图的基础上改进;
Mosaic数据增强
Self-Adversarial Training(自对抗训练),这是在一张图上,让神经网络反向更新图像,对图像做改变扰动,然后在这个图像上训练。这个方法,是图像风格化的主要方法,让网络反向更新图像来风格化图像(对风格化感兴趣,可以看看我写的一篇介绍谷歌的一个实时任意风格化的文章);对自身实行对抗攻击
跨最小批的归一化(Cross mini-batch Normal),在CBN的基础上改进;
BN, CBN,CmBN的对比
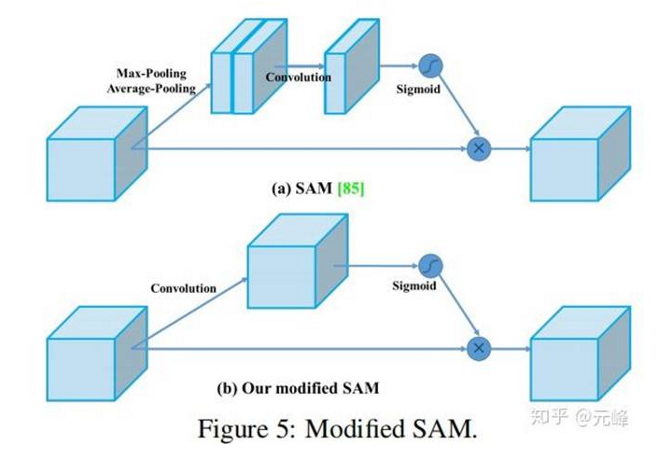
- 修改的SAM,从SAM的逐空间的attention,到逐点的attention;
[image: https://pic4.zhimg.com/50/v2-440bfacec2a426272ef06e94a16837bb_hd.jpg?source=1940ef5c]
SAM和修改的SAM对比图
- 修改的PAN,把通道从相加(add)改变为concat,改变很小;
[image: https://pic4.zhimg.com/50/v2-a1f0ccf10cea594c1aebcc98111c6dd5_hd.jpg?source=1940ef5c][image: https://pic4.zhimg.com/80/v2-a1f0ccf10cea594c1aebcc98111c6dd5_720w.jpg?source=1940ef5c]
PAN和修改的PAN
最终整体架构表示:
Experiments
实验中的一些参数设置和具体的表达就从文章中看吧,还有各种trick的表达效果,其实很重要,可以省下很多的研究时间。
• Influence of different features on Classifier training
• Influence of different features on Detector training
• Influence of different backbones and pretrained weightings on Detector training
• Influence of different minibatch size on Detector training
FAQ
• reception field 的理解,以及作用






