
Pooling
DownSampling:Pooling的全面调研
@Aiken 2021 笔记摘录:
深度神经网络中的池化方法:全面调研(1989-2020) - 知乎 ;相同论文的简单中文Version
16页综述,共计67篇参考文献。网络千奇百怪,但基础元素却大致相同!本文全面调研了1989至2020年一些著名且有用的池化方法,并主要对20种池化方法进行了详细介绍(这些方法,你都知道么?) 注1:文末附【计算机视…
来自 https://zhuanlan.zhihu.com/p/341820742
原文:《Pooling Methods in Deep Neural Networks, a Review》
池化的根本目的(Motivation)
卷积神经网络是DNN的一种特殊类型,它由几个卷积层组成,每个卷积层后都有一个激活函数和一个池化层。
池化层是重要的层,它对来自上一层的特征图执行下采样,并生成具有简化分辨率的新feature maps 。该层极大地减小了输入的空间尺寸。 它有两个主要目的。 首先是减少参数或权重的数量,从而减少计算成本。 第二是控制网络的过拟合。
- 池化可以增加网络对于平移(旋转,伸缩)的不变性,提升网络的泛化能力。
- 增大感受野;
- 降低优化难度和参数数目,
理想的池化方法应仅提取有用的信息,并丢弃无关的细节。
特征不变性、特征降维、在一定程度上防止过拟合,更方便优化
主流的池化方法
Average Pooling 平均池化
没啥好说的,就是每个block取一个均值。如下图所示:更关注全局特征
Max Pooling 最大值池化
更关注重要的局部特征
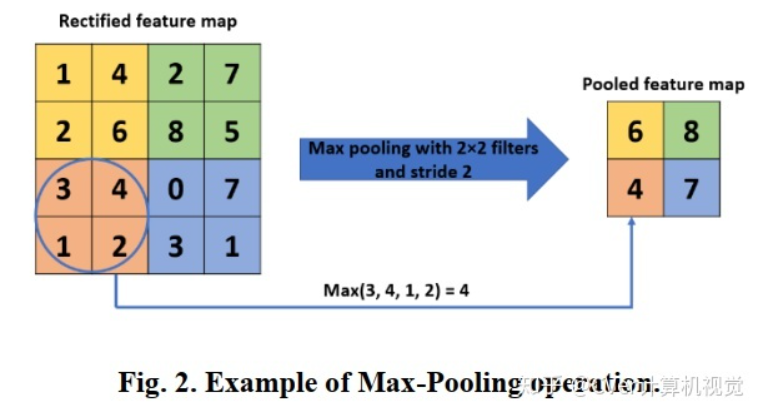
image-20210219153154458
Mixed pooling
在max、average pooling中进行随机选择,来组合pooling
L_p pooling
作者声称这个泛化能力比Max Pooling要好,输入的平均值权重(也就是和分之一)来进行,算是推广的公式。
Stochastic Pooling
feature_map中的元素按照其概率值大小随机选择,元素被选中的概率与数值大小正相关,这就是正则化操作了。
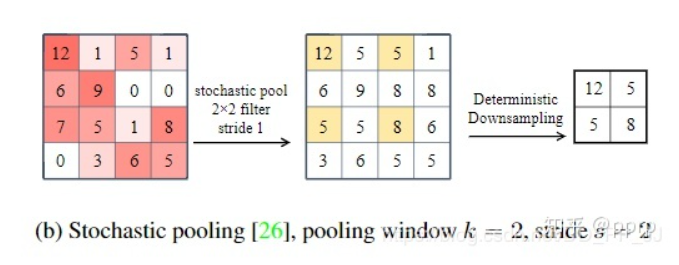
image-20210219160011182
Spatial Pyramid Pooling (SPP)
SPPNet在RCNN之后提出的,用于解决重复卷积计算和固定输出的问题,具体的方法是:在Feature_Map中通过Selective Search获得窗口然后输入CNN中。
这个池化方法实际上就是多个空间池化的组合,对不同的输出尺度采用不同的划窗大小和步长来确保输出的尺度相同,同时能够融合多种尺度特征,提供更丰富的语意信息,常用于:
- 多尺度训练
- 目标检测中的RPN
实际上也就是(全图pooling一次,全图分成22块Pooling,全图分成44块以后 做Pooling,然后就是固定尺寸的了,前面的输出是256-d 然后就是(4+16+1)* 256 最后的特征
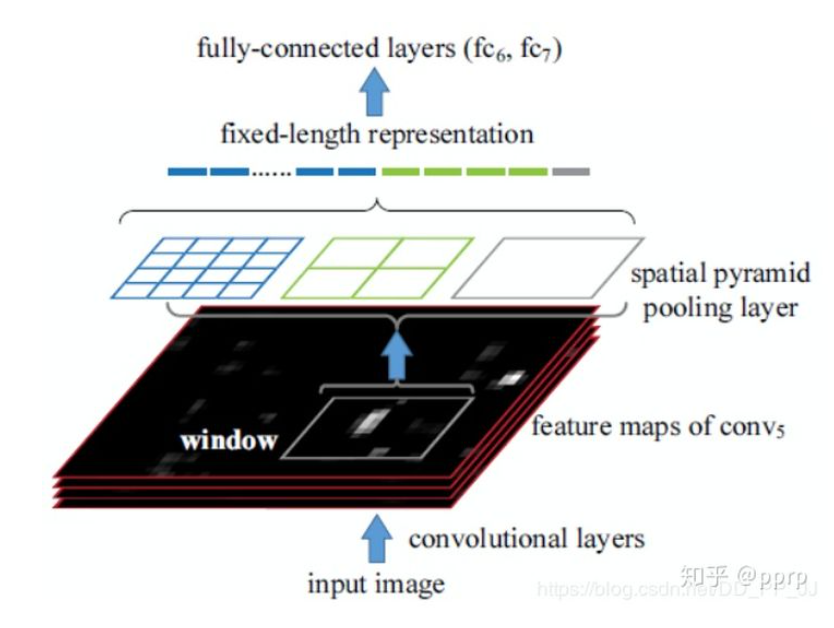
image-20210219160238878
YOLO v3 变体
在YOLO v3中,有一个网络结构中的yolo-v3-spp比原本的准确率更高,具体的cfg如下:
1 | |
这里的SPP是原本的SPPNet的变体,通过多个Kernel Size的maxpool 将最终得到的feature map进行concate,得到新的特征组合:
SPP有效的原因分析
- 从感受野角度来讲,之前计算感受野的时候可以明显发现,maxpool的操作对感受野的影响非常大,其中主要取决于kernel size大小。在SPP中,使用了kernel size非常大的maxpool会极大提高模型的感受野,笔者没有详细计算过darknet53这个backbone的感受野,在COCO上有效很可能是因为backbone的感受野还不够大。
第二个角度是从Attention的角度考虑,这一点启发自CSDN@小楞(链接在参考文献中),他在文章中这样讲:
出现检测效果提升的原因:通过spp模块实现局部特征和全局特征(所以空间金字塔池化结构的最大的池化核要尽可能的接近等于需要池化的featherMap的大小)的featherMap级别的融合,丰富最终特征图的表达能力,从而提高MAP。
Attention机制很多都是为了解决远距离依赖问题,通过使用kernel size接近特征图的size可以以比较小的计算代价解决这个问题。另外就是如果使用了SPP模块,就没有必要在SPP后继续使用其他空间注意力模块比如SK block,因为他们作用相似,可能会有一定冗余。
Region of Interest Pooling (ROI Pooling)
参考链接:原理以及代码实现;Some Detail 以及Align的改进;Best One
对于ROI pooling 的讲解首先要从目标检测的框架出发,帮助理解,
目标检测分为两步:
- region proposal:输入image,找到所有可能的object的位置(bounding box),也就是ROI,在这过程中可能用到滑窗和selective search。
- final classification:确定上阶段的每个region proposal是否是目标类别,或者背景
这样的框架存在问题:
- 大量的ROI要进行计算,就很难实时监测,也无法做到E2E
使用ROI Pooling进行简化,输入和作用如下:
- 从多个具有卷积核池化的深度网络中获得固定大小的Feature-Map;
对不同尺寸的ROI进行处理,能得到统一的尺寸。 - 一个表示所有ROI的N*5的尺寸,N是数目,5维度分别是Index,左上角坐标,右下角坐标
具体实现的操作:
- 根据输入image,将ROI映射到feature map对应位置;
- 将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
- 对每个sections进行max pooling操作;
这样我们就可以从不同大小的方框得到固定大小的相应 的feature maps。值得一提的是,输出的feature maps的大小不取决于ROI和卷积feature maps大小。ROI pooling 最大的好处就在于极大地提高了处理速度。
下图大黑框是对应的ROI,输出最后的要求是2*2,基于下面的划分再进行maxpooling即可。
ROI Align的改进
ROI pooling在映射的时候出现小数,这是第一次量化,在每个roi中选取多少个采样点进行max pooling也会出现小数。这样的处理可能会丢失数据,降低了模型的精度
ROI Align并不需要对两步量化中产生的浮点数坐标的像素值都进行计算,而是设计了一套优雅的流程。如图2,其中虚线代表的是一个feature map,实线代表的是一个roi(在这个例子中,一个roi是分成了2*2个bins),实心点代表的是采样点,每个bin中有4个采样点。我们通过双线性插值的方法根据采样点周围的四个点计算每一个采样点的值,然后对着四个采样点执行最大池化操作得到当前bin的像素值。
RoI Align做法:假定采样点数为4,即表示,对于每个2.97 x 2.97的bin,平分四份小矩形,每一份取其中心点位置,而中心点位置的像素,采用双线性插值法进行计算,这样就会得到四个小数坐标点的像素值。
实际上就是用双线性插值来取代了ROI Pooling的量化过程。
新颖特殊的池化方法
这一部分的池化方法存在着一些特殊的特性,在实际需要的时候再进行仔细的研究,但是可以将大体的特征简单的描述一下,方便后续寻找。
中值池化
与中值滤波特别类似,但是用的特别少,中值池化也具有学习边缘和纹理结构的特性,抗噪声能力比较强。
组合池化
就是将max 和 average concate或者add起来。
Multi-scale order-less Pooling MOP池化
基于多尺度的池化方式,提升了卷积网络的不变性同时没有破坏卷积网络的可鉴别性,分布从全局与局部池化中提取特征,图示与说明如下:
NetVLAD Pooling
NetVLAD是论文《NetVLAD: CNN Architecture for Weakly Supervised Place Recognition》提出的一个局部特征聚合的方法。
双线性池化
Bilinear Pooling是在《Bilinear CNN Models for Fine-grained Visual Recognition》被提出的,主要用在细粒度分类网络中。双线性池化主要用于特征融合,对于同一个样本提取得到的特征x和特征y, 通过双线性池化来融合两个特征(外积),进而提高模型分类的能力。
UnPooling上采样操作
1.在Pooling(一般是Max Pooling)时,保存最大值的位置。
2.中间经历若干网络层的运算。
3.上采样阶段,利用第1步保存的Max Location,重建下一层的feature map。
UnPooling不完全是Pooling的逆运算,Pooling之后的feature map,要经过若干运算,才会进行UnPooling操作;对于非Max Location的地方以零填充。然而这样并不能完全还原信息。
光谱池化
图像池化不光发生在空间域,还可以通过DFT变换,在频域空间实现池化,一个使用光谱池化最大池化的例子如下:
基于排名的均值池化
Rank-based Average Pooling
这种池化方式的好处事可以克服最大池化与均值池化方式的不足
基于权重的池化
Edge-aware Pyramid Pooling
Pooling






