
Training Strategy
@Aiken 2020,
主要针对神经网络的训练过程中的一些基础策略的调整,比如当训练的曲线出现一定的问题的时候,我们应该怎么去调整我们训练过程中的策略。
参数调整过程中最重要的就是优化器(优化或者说是下降算法)和学习率(优化算法的核心参数),此外像是数据增强策略还是Normalization策略,都能极大的影响一个模型的好坏。
优化器
Some Material
实际上虽然有很多的优化算法,但是到最后最常用的还是 SGD+Mon 和 Adam两种:
Adam主要的有事在于自适应学习率,他对我们设计的学习率实际上没有那么敏感,但是在具体实验中往往不会有调的好的SGD那么好,只是在SGD的参数调整中会比较费劲。
但是有了根据patient调整lr的scheduler后,我们基本上可以使用SGD做一个较为简单的调整,只要设计好初始的lr的实验以及用来调整学习率的参数值。
学习率
$\omega^{n} \leftarrow \omega^{n}-\eta \frac{\partial L}{\partial \omega^{n}}$ 其中的权重就是学习率lr,
==Basic==
| 学习率大 | 学习率小 | |
|---|---|---|
| 学习速度 | 快 | 慢 |
| 使用情景 | 刚开始训练时 | 一定的次数过后 |
| 副作用 | 1. Loss爆炸 2.振荡 | 1.过拟合 2.收敛速度慢 |
学习率的基本设置
在训练过程中,一般根据训练轮数设置动态变化的学习率。
- 刚开始训练时:学习率以 0.01 ~ 0.001 为宜。
- 一定轮数过后:逐渐减缓。
- 接近训练结束:学习速率的衰减应该在100倍以上。
Note:
如果是 迁移学习 ,由于模型已在原始数据上收敛,此时应设置较小学习率 (≤10−4) 在新数据上进行 微调 。
学习率变化方法
==warm up==
warm up衰减策略与上述的策略有些不同,它是先从一个极低的学习率开始增加,增加到某一个值后再逐渐减少, 这点上倒是和Cosine Anneal LR有一定的相似之处,将这两种结合起来是一种常见的训练策略:
这样训练模型更加稳定,因为在刚开始时模型的参数都是随机初始化的,此时如果学习率应该取小一点,这样就不会使模型一下子跑偏。
而这样的跑偏对于大模型而言,可能是导致很严重的影响,后面收敛了也可能不会达到最佳的效果,一开始的跑偏,可能会造成准确率在后面的严重结果。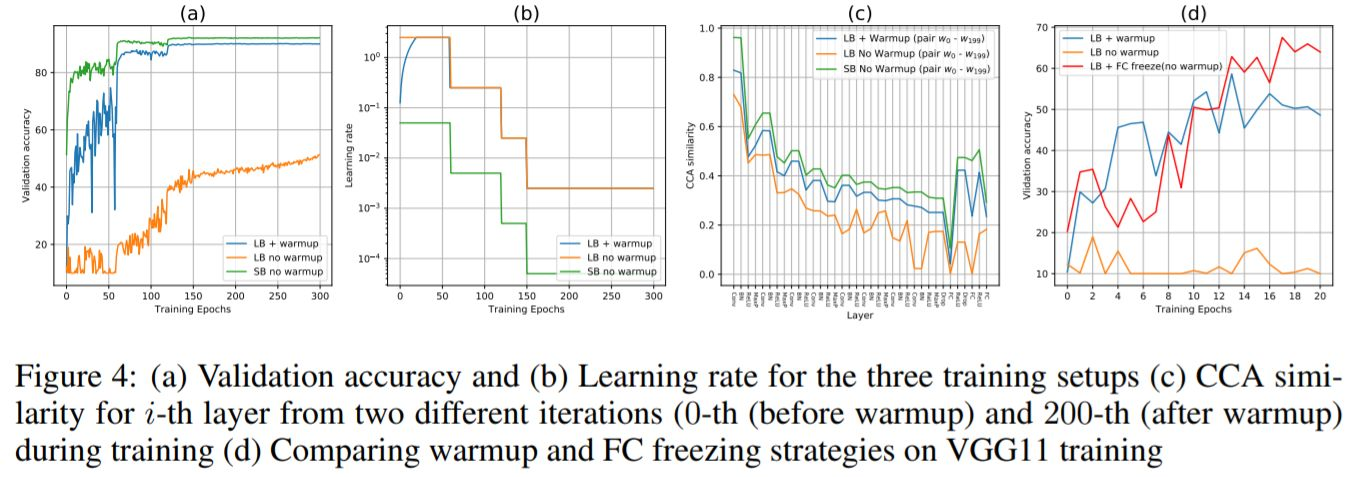
1 | |
==Scheduler Setting:==
分组的学习率也能通过scheduler进行学习率的更新,可以放心使用。
| 轮数减缓 | 指数减缓 | 分数减缓 |
|---|---|---|
| step decay | exponential decay | 1/t1/t decay |
| 每N轮学习率减半 | 学习率按训练轮数增长指数插值递减 | lrt=lr0/(1+kt),k 控制减缓幅度,t 为训练轮数 |
Pytorch的Scheduler
pytorch中提供了很多scheduler的方法,其中用的最多的可能还是multistep,考虑到后续可能会用到基于指标调整的学习率,这里特别提一个cosine的学习率调整策略,它的学习率呈现的是一种周期变化的样子。
==Custom Scheduler==
Pytorch为可能的自定义提供了一个方便的Scheduler接口,ReduceLROnPlateau,通过step 调用指标的变化,进行学习率的调整,极其方便。
1 | |
基本的参数包括:
- mode 很好理解,max(acc),min(loss)值
- factor 学习率下降的参数
- patience 多少次没有变化就调整
- cooldown 调整后多久的冷却期
- threshold,threshold_model 调整我们的动态上下限
threshold (float) – Threshold for measuring the new optimum, to only focus on significant changes. Default: 1e-4.
threshold_mode (str) – One of rel, abs. In rel mode, dynamic_threshold = best * ( 1 + threshold ) in ‘max’ mode or best * ( 1 - threshold ) in min mode. In abs mode, dynamic_threshold = best + threshold in max mode or best - threshold in min mode. Default: ‘rel’.
分析学习率的大小
在训练过程中可视化Loss下降曲线是相当重要的,那么针对Loss出现异常的情况我们应该怎么样去调整使得Loss逐步趋于正常呢?
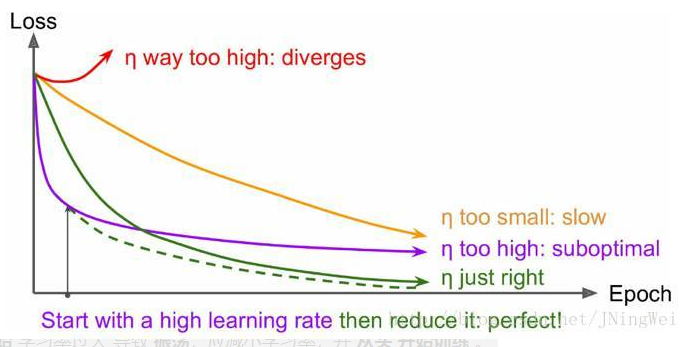
曲线 初始时 上扬 [红线]:(直接起飞梯度爆炸)
初始 学习率过大 导致 振荡,应减小学习率,并从头开始训练 。
曲线 初始时 强势下降 没多久 归于水平 [紫线]:
Solution:后期学习率过大导致无法拟合,应减小学习率,并重新训练后几轮 。
曲线 全程缓慢 [黄线]:
Solution:初始 学习率过小 导致收敛慢,应增大学习率,并从头开始训练 。
过拟合欠拟合现象
过拟合->各种泛化能力差的现象在这里我个人对这个现象的定义为以下的几种:
- 训练阶段的准确率和验证/测试阶段的准确率相差大
- 训练过程和验证过程中的损失下降不一致,验证集中的准确率没有随着训练提升
- 典型的过拟合导致这样的现象
下面整理一下李沐对该部分的讲解

bug部分可能是由于增强做的过高或者问题太难, 但是在正常的表现下也不应该出现这种问题, 误差应该是差不多的.
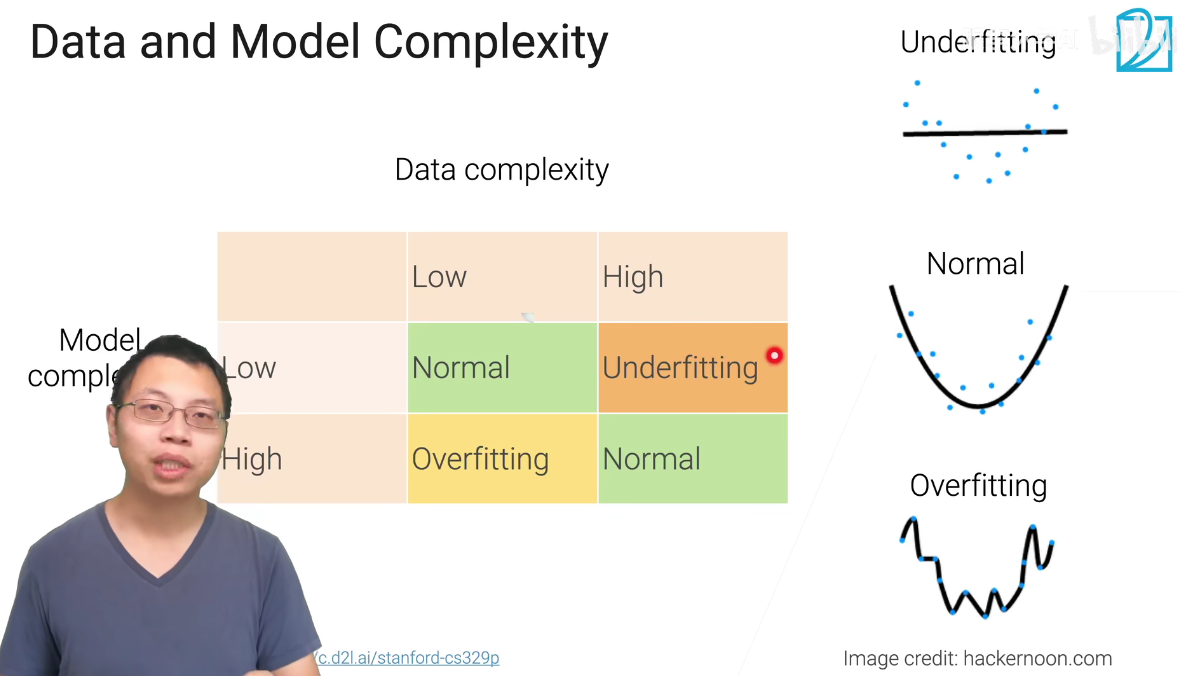
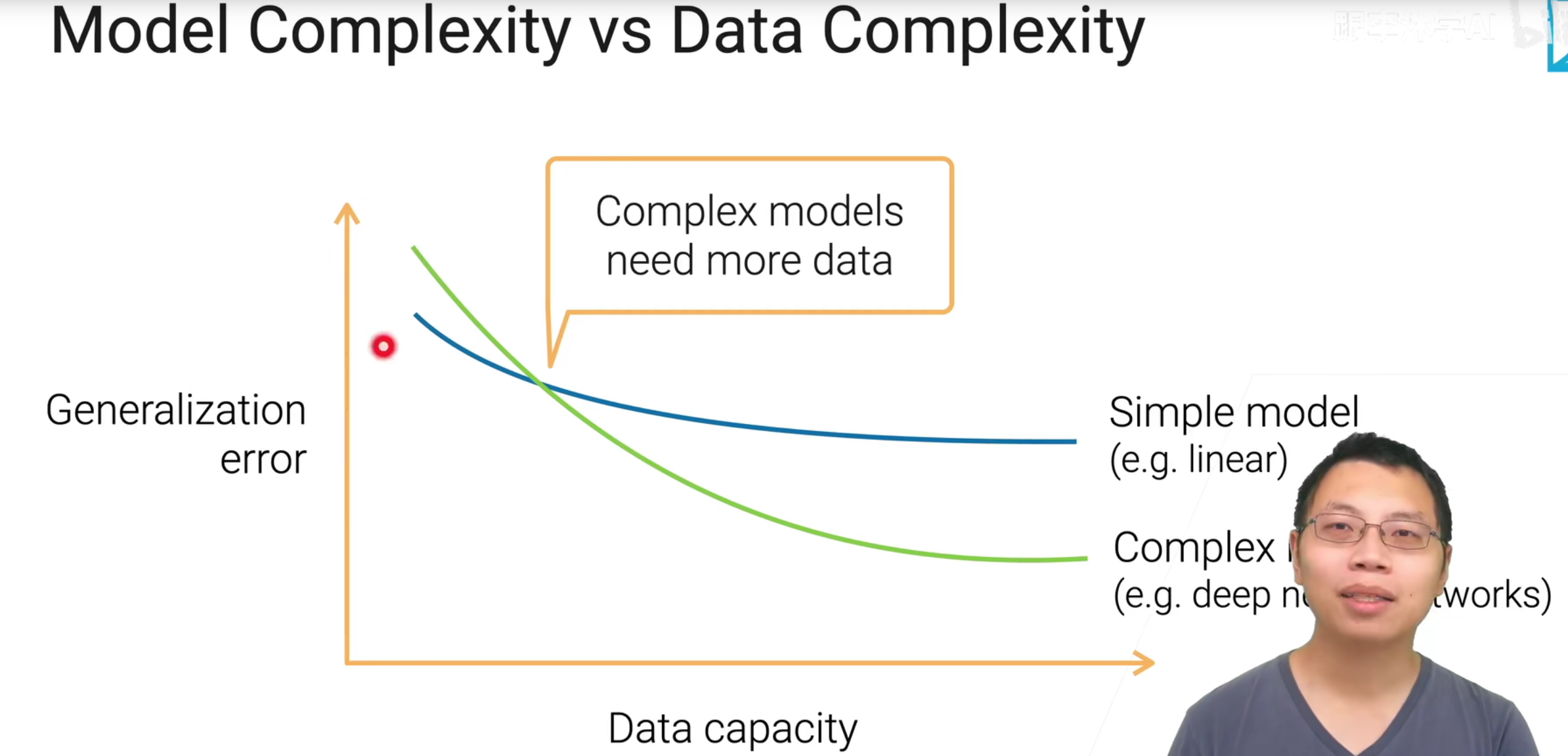
上面的这张图片也说明了, 我们模型和问题的难度是需要相互匹配的, 如果不匹配就会出现各种各样的问题, 模型的复杂度, 通常可以从可学习参数的数来进行简单的判断的.
过拟合问题定义和分析
定义:模型对于训练集的假设过度严格,导致对训练集的数据拟合的“很好”,但是在测试验证集中效果不理想。可能会出现的典型现象如下:
- 验证损失先下降后上升
- 训练集和测试集稳定后的准确率相差很大
下面这张图, 显示的是模型的复杂度和相应的泛化和训练误差之间的关系, 在训练的时候复杂度还是需要自我调整.
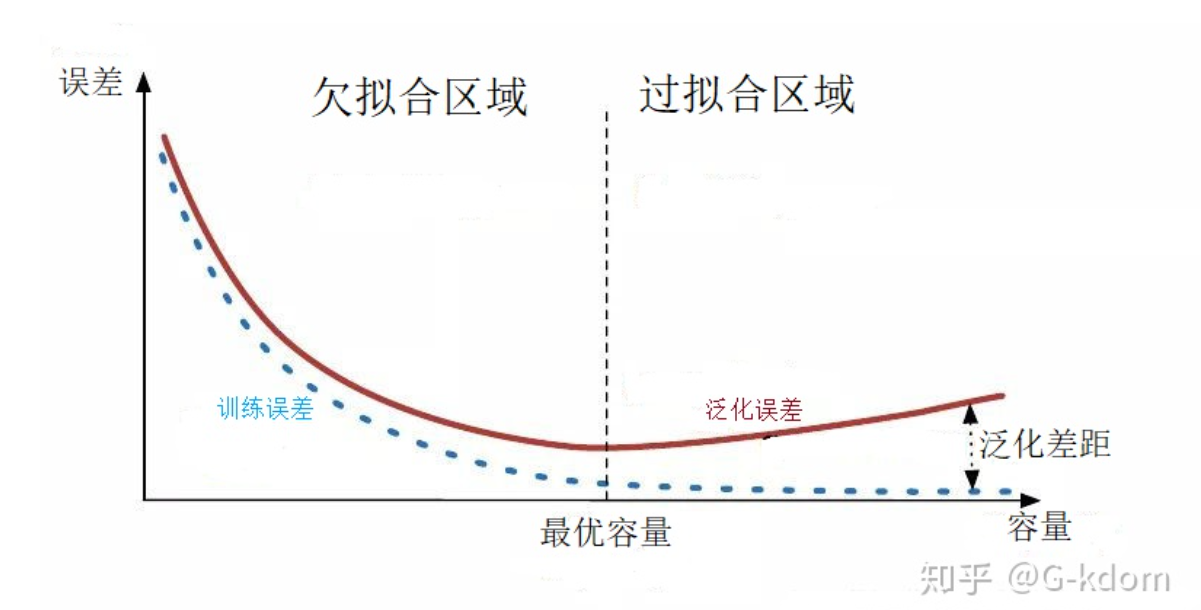
收敛过快泛化能力差
过拟合的一种衍生问题,当模型在训练集中快速收敛,在这种情况下可能会陷入极小值,由于损失太小,模型参数难以跳出极小值点,这种情况下,如果不加以约束会影响泛化能力,可以考虑使用,
flood方法来设计我们的loss(效果未知,作为一种策略把,保证模型能够有一定量的损失,同时希望验证集上的损失能够下降到一个平缓的地方,来保证泛化能力)
产生的原因分析
- 训练数据样本单一,数据量不足
- 噪声干扰过大:失去了真实的输入输出之间的关系
- 模型的复杂度太高,足够死记硬背所有训练集的数据,导致不知道变通
数据的复杂度分析:
大部分情况下进行数据的对比还是一个比较直观的情况, 其实可以从这几个方面进行比较
- 数据集的样本数, 类别
- 数据集的分辨率
- 数据的时空结构和多样性
常见的解决方式
:zap:添加正则化L1,L2(weight decay),
weight decay等权重下降的方法,需要熟练掌握在pytorch上的设置
:zap:降低模型的复杂度,对应模型的设计和问题的规模需要更好的分析。
:zap:数据增强,使得数据的多样化指标进一步上升
:zap:Dropout,Early Stop
BatchNormalization
集成学习方法,通过对多个模型进行集成来降低单一模型的过拟合风险
图像增强
这里我们为图像增强另外开一个文档,图像增强的内容实际上可以考虑《数字图像处理》的这样一门课。
文中提到对准确率提升最多的一些增强方式是如下的三种:
- Crop,Resize ,Flip
- Colour Distortion
- Gaussian Blur
1 | |

早停法
因为准确率都不再提高了,损失值反而上升了,再继续训练也是无益的,只会浪费训练的时间。那么该做法的一个重点便是怎样才认为验证集不再提高了呢?并不是说准确率一降下来便认为不再提高了,因为可能在这个Epoch上,准确率降低了,但是随后的Epoch准确率又升高了,所以不能根据一两次的连续降低就判断不再提高。
对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
更好的一个方式应该是使用一个类来进行计数
1 | |
在得到早停的迭代次数和权重矩阵参数后,后续有几种方法可以选择。
彻底停止
就是啥也不做了,最多再重复几次早停的试验,看看是不是稳定,然后就使用做为训练结果。
再次训练
由于第一次早停是通过验证集计算loss值来实现的,所以这次不再分训练集和验证集,记住了早停时的迭代次数,可以重新初始化权重矩阵参数,使用所有数据再次训练,然后到达第一次的时停止。
但是由于样本多了,更新批次也会变多,所以可以比较两种策略:
1) 总迭代次数epoch保持不变 2) 总更新梯度的次数保持不变
优点:使用更多的样本可以达到更好的泛化能力。
缺点:需要重新花时间训练。
继续训练
得到后,用全部训练数据(不再分训练集和验证集),在此基础上继续训练若干轮,并且继续用以前的验证集来监控损失函数值,如果能得到比以前更低的损失值,将会是比较理想的情况。
优点:可以避免重新训练的成本。
缺点:有可能不能达到目的,损失值降不到理想位置,从而不能终止训练。
效率优化
and there are some tips in this article, we should read and learn about it
这一部分希望通过trick或者对应的一些代码技巧,优化训练过程中带来的资源占用和损耗,进一步提升训练时效性和资源上的有效利用
1 | |
relu(inplace = True)
rapidAI
Thanks to Nvidia, we could using np, spicy, pandas, sklearn on CUDA, which is much more faster. Achieve this by those repo: cuml for sklearn, cupy for numpy and spicy, cudf for dataframe and so on.
借助这几个仓库的文档, 我们可以学习如何调用这些库去加速和实现我们的代码.
在这里要注意的是, 使用这几个仓库的同时会引入更多的数据类型, 以及设备存储情况, 我们要在必要的时候对数据的存储位置进行分析和迁移.
过于频繁的数据移动可能反而会减慢运行速度, 但是如果是后续不需要的数据我们可以进行迁移.
Install
- 如果版本和torch的匹配(old version) 10.2 可以通过以下的命令安装cuml, 但是要注意panda版本 == 1.3.0, 首先对panda版本进行修改, 这种时候可能使用pip结合conda是一个更好的选择
1
- 如果版本不匹配, 我们可以首先配置rapidai的环境, 在安装pytorch即可, 或者使用nvidia发布的相同cuda版本的pytorch.
torch.Cuda.AMP
使用Torch自带的AMP取代APEX的AMP进行优化,在>=1.6的情况下,Torch已经自动支持了AMP混合, 而且事实证明在大多数情况下, Torch对amp的支持相比APEX来说要更加稳定和性能友好。
使用方法:
较为简单,只需要在训练的主流程中进行如下的嵌入1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23from torch.cuda.amp import autocast, GradScaler
# 在训练最开始的阶段实例化一个GradScaler对象
scaler = GradScaler()
for i in epochs:
for j in iterators:
...
# model and loss
with autocast():
out = model(input)
loss = loss_fn(output, target)
# and change the update and backward phas
# 放大loss
scaler.scale(loss).backward()
# 对inf和nan进行判断,没有问题的话就进行step
scaler.step(optimizer)
# 是否对scaler进行更新
scaler.update()
APEX_显存优化
this session is write for the nvidia module APEX which can save a lot of memory and accelerate the training speed. we should learn how to use it .
通过APEX好像能优化接近50%的显存,而且在修改原框架代码中的要求很小,所以在这里有必要通过APEX去优化我们的框架
理论参考:基于Apex的混合精度加速;
其中opt_level分别表示:O0纯FP32,O1混合精度训练,O2几乎FP16除了BN,O3纯FP16很不稳定,但是速度最快
安装:
验证cuda版本,验证torch的cuda版本
1
2
3
4
5nvcc -V
# nvcc 很可能会找不到命令,去如下路径搜索是否cuda正确安装
cd /usr/local/cuda*/bin
# 其中若有nvcc命令的话可以直接执行
nvcc -V1
2import torch
print(torch.version.cuda)安装apex
1
2
3
4git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./import验证安装成功
1
import apex
使用:
参考官方示例,我们可以知道APEX的使用场景主要集中在几个部分:
model,optimizer,loss upgrade and parallel
故而我们对原始代码修改或添加如下:
1 | |
此外,如果我们希望使用APEX在训练过程中执行resume的话,我们还需要对代码做如下的添加
Note that we recommend restoring the model using the same opt_level. Also note that we recommend calling the load_state_dict methods after amp.initialize.
1 | |
安装过程中遇到了很多的问题:
1 | |
cc1plus: warning: command line option ‘-Wstrict-prototypes’ is valid for C/ObjC but not for C++
1 | |
command ‘gcc’ failed with exit status 1
1 | |
限制网络的输出范围
实际上,这一部分的应用就属于激活函数的数学理念问题了,我们倘若需要将网络的输出限制在一定的范围内,除了自己编写相关的数据处理手段之外,激活函数实际上有一部分原因就是为了这点设置的。
- 神经网络基于对非线性运算的需要,引入了激活函数,强化了网络的学习能力;
- 同时神经网络对于输出有所要求(很多时候是以一种概率表达的方式输出的)所以就会需要softmax(0,1同时
sum==1)之类的函数,可以将分类器的原始输出映射为概率。 Sigmoid tanh之类的将输出限制在(0,1),但是并没有对加和有要求,这里可以做一个区分https://www.cnblogs.com/jins-note/p/12528412.html区分sigmoid(多分类)和Softmax(单分类) - Softmax和tanh可能会出现梯度消失的问题,ReLU将输出限制在(0,1)
一部分激活函数的特点
所以很显然,我们可以通过对于相应的激活函数的应用,来限制我们的网络输出范围。
Training Strategy





