
Loss-Smooth(Sharpen)
@AikenHong 2021
@topic
- smooth label (inception v2)
- when does label smoothing help (nips 2019)
- sharpen in semi-supervised in the future
- offical code github
不是一个通用的方法,在很多的任务上反而会导致掉点的现象,可以简单分析一下,汲取一下思想和Sharpen做对比,在这篇文章中,我们可以结合之前的人脸对比损失来进行分析。
What’s the smooth label
首先介绍在图像分类任务中对logits和Hard label做ce得到我们的损失,可以表现为如下的形式:
由于我们的标签是一个hard label,实际上可以转化成一个one-hot,即
而soft label实际上做的是将 1的位置变为$1-\alpha$,其他位置设置为$\alpha/(K-1)$,然后再去求CE,
Hinton论文中给出该损失对特征分布的作用测试图: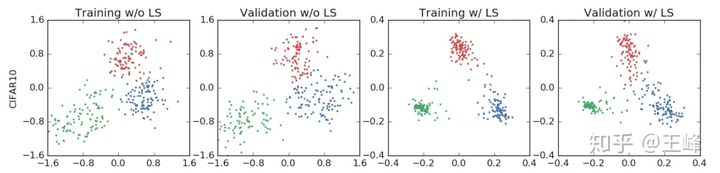
Pros and Cons
校准性:模型预测的分数能不能同时表征其置信度
- LS可以提高模型的泛化性,同时还能提高模型的校准性(model calibration)
- 在模型蒸馏中,如果我们的teacher model是由LS训练的,Teacher的效果更好,但是Student的性能会变差,这是因为LS的作用是将相同类别的example聚类到更加紧促的cluster中,但是这也导致了,不同样本之间的相似性信息的损失,从而影响了蒸馏的效果
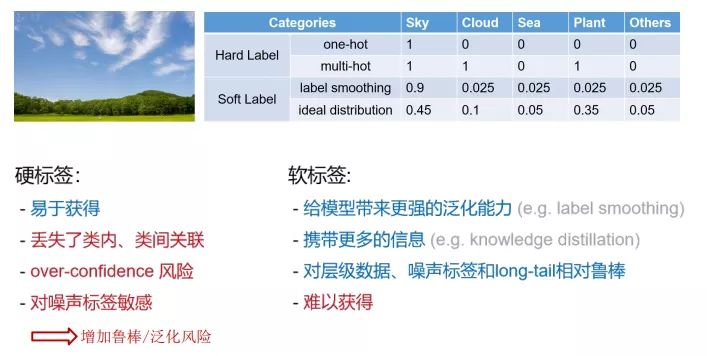
此外模型的校准性能,通常可以使用T系数来进行优化,Temprature scaling(TS)可以有效的降低ECE(expected calibration error)
(TS就是在计算cross entropy之前把模型的输出除以超参T,然后再参与cross entropy的计算,比较典型的应用就是在蒸馏中对teacher模型 soft label 处理)
How it work

从特征输出的信息来看,启用了LS(loss smooth)的特征的Feature Norm比没有启用小得多,特征空间减小的话,实际上就是降低softmax中的s值(长度,还有另一个指标是角度)
==较低的s值==会有这样的几个作用:
- softmax prob的最大值降低,这样我们就可以永远在线性优化区,几乎不存在平滑区域,这样样本向中心的聚拢程度会更高
- s过小的话,对于人脸匹配(往往设置较大的s),为了有更宽广的判别面,使得精度更高,对应于Hard Sample(Task)也是一样的到理道理,就会起到反作用。
Label Smoothing起到的作用实际上是抑制了feature norm,此时softmax prob永远无法达到设定的$1-\alpha/k-1$ ,loss曲面上不再存在平缓区域,处处都有较大的梯度指向各个类中心,所以特征会更加聚拢。而之所以人脸上不work,是因为我们通常会使用固定的s,此时Label Smoothing无法控制feature norm,只能控制角度,就会起到反向优化的作用
Feature Norm

BTW:对比损失可以分为alignment和uniformity部分
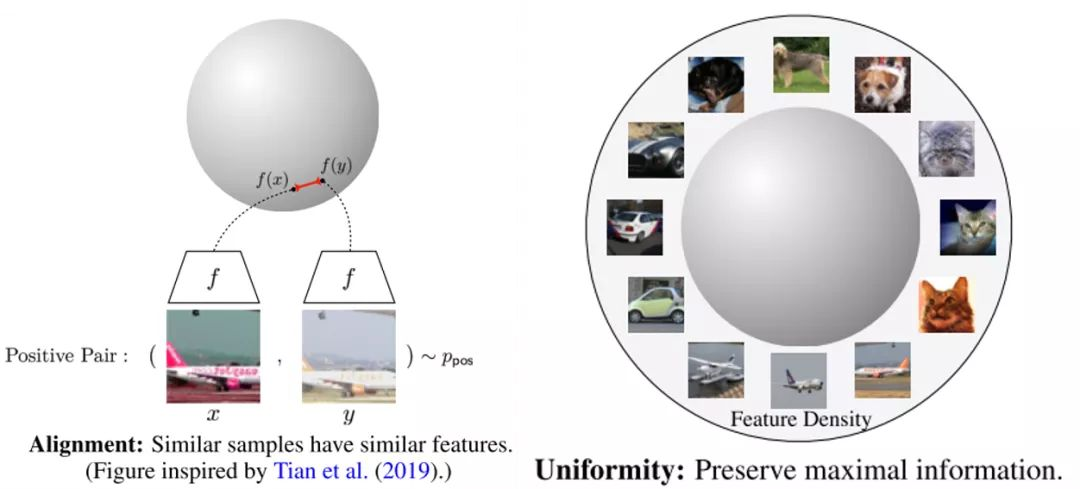
第一部分和正样例有关,第二部分仅和负样例有关,作用是远近。
With the Sharpen Label
Sharpen实际上是和Smooth相反的过程, Sharpen使用的场景可能相对较少, 比如我们希望能最小化熵损失(Like Semi-Supervised), 让输出模型的置信度更高, 或者让分界面更加分明的情况.
当T->0的时候,标签将趋向于ont-hot(Dirac)
而当我们去做FIL任务的时候, 我们拥有的标签实际上应该是One-Hot的, 所以我们需要分析是否需要对其去做smooth, 还是说我们结合SCL的特性, 用One-Hot这种Sharpen的标签去学一个更好的分界面.
reference
⁉️理解的是错的,从NCE角度
参考个人对NCE的理解[[Papers/Loss-NCE]]
Loss-Smooth(Sharpen)





