
Loss-NCE
@AikenHong 2021
Noise Contrastive Estimation Loss = NCE Loss 噪声对比估计损失,这里的Noise实际上就是Negative Samples.
该损失被广泛的用于对比学习的任务,而对比学习广泛的作为自监督学习的无监督子任务用来训练一个良好的特征提取器,于是对于对比学习的目标和效用的理解十分关键。
What’s NCE Loss
在介绍NCE之前我们可以将其和CE进行一个简单的对比,虽然名称上不是同一个CE,但是在数学表达上却有很相近的地方(softmax-kind of loss)
首先softmax,他保证所有的值加起来为一,结合onehot的ce,实际上j==gt的情况下外层+log也就是ceLoss,也就是 $logSoftmax$
然后看infoNCE,基础的对比学习损失可以写成:
其中 $f_x^T f_y^T$ 为 $sim(x,y)$ 时即转化为带$T$的NCE,即InforNCE.
分子是正例对的相似度,分母是正例对+所有负例对的相似度,最小化infoNCE loss,就是去最大化分子的同时最小化分母,也就是最大化正例对的相似度,最小化负例对的相似度。
从该形式上看,和soft的CE形式上是统一的,当我们把分母看作概率和自身以及和其他的相似性,这样和NCE在形式上和简化后的CE实现了统一。
但是我不认为这和label smooth 后的CE有相关性,而是和原始的CE经由One-hot简化后结构上有相似性。
How it Works
NCE的思想是拉近相似的样本,推开不相近的样本,从而学习到一个好的语义表示空间,这一点上实际上和度量学习的思想是一样的,只是对比学习通常作用在无监督或者自监督的语境中,度量学习这是有监督的。
考虑之前人脸匹配的研究,使用 “Alignment and Uniformity on the Hypersphere”中的Alignment and Uniformity,就是一个更好理解他的角度
公式经过上面的推导就可以看成下的两个部分,其中alignment只与positive pair有关,相反Uniformity只与negative pair相关,希望所有的点都能尽可能的分布在uni hypersphere上。
这样均匀的分布有利于聚类并且线性可分,且经过实验证实无监督对比学习确实能得到强判别力的特征。
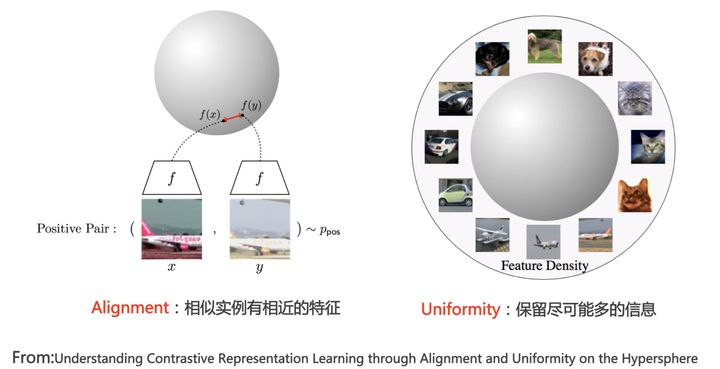
Alignment:指的是相似的例子,也就是正例,映射到单位超球面后,应该有接近的特征,也就是在超球面上距离比较近;
Uniformity:指的是系统应该倾向于在特征里保留尽可能多的信息,这等价于使得映射到单位超球面的特征,尽可能均匀的分布在球面上,分布的越均匀,意味着保留的信息越充分。分布均匀意味着两两有差异,也意味着各自保有独有信息,这代表信息保留充分。
参考Label Smooth中Soft Label的定义,当我们将特征拉到超球面上均匀分布的时候,特征之间相对的距离关系,远近是否应该保留真实分布中的相似性和度量分布?NCE Loss是否能保留这种关系呢?
这种额外的Info可能能够对于后续的蒸馏学习有一个比较大的影响
With Self-Supervised Learning
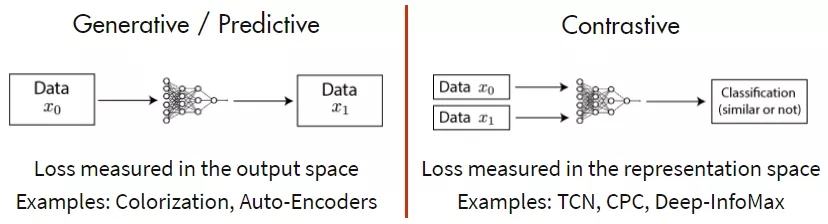
自监督学习最重要的就是下游任务的设计,一般分成两种:
- 生成式模型:Encode-Decode架构,让输入输出尽可能的相似,或者是后续进化的MIM架构,挖空并还原空中的内容,并在Transformer架构中取代判别式模型方法称为主流。
- 判别式模型:通过Encoder编码,通过对比学习分析相似性来建立对比损失,自从MoCo出来后判别式模型在一定时间内成为主流。
避免退化解形成
InfoNCE的两部分在理论上是缺一不可的,如果没有Alignment,就无法聚类,如果没有Uniformly,容易使得所有的输入输出又相同的表示,也就是形成退化解。
参考 Article 对几种自监督的方法解决退化解的方式进行了简要的分析。
实验中的设置问题
zhihu
对比学习中一般选择一个batch中的其他样本作为负例,如果负例中又很相似的样本怎么办?
在无监督无标注的情况下,这样的伪负例,其实是不可避免的,首先可以想到的方式是去扩大语料库,去加大batch size,以降低batch训练中采样到伪负例的概率,减少它的影响。
另外,神经网络是有一定容错能力的,像伪标签方法就是一个很好的印证,但前提是错误标签数据或伪负例占较小的比例。
也可以考虑使用监督的对比学习方法
对比学习的infoNCE loss 中的温度系数t的作用是什么?[1]
温度系数的作用是调节对困难样本的关注程度:越小的温度系数越关注于将本样本和最相似的困难样本分开,去得到更均匀的表示。然而困难样本往往是与本样本相似程度较高的,很多困难负样本其实是潜在的正样本,过分强迫与困难样本分开会破坏学到的潜在语义结构,因此,温度系数不能过小
考虑两个极端情况,温度系数趋向于0时,对比损失退化为只关注最困难的负样本的损失函数;当温度系数趋向于无穷大时,对比损失对所有负样本都一视同仁,失去了困难样本关注的特性。
也可以用另一个角度理解:
可以把不同的负样本想像成同极点电荷在不同距离处的受力情况,距离越近的点电荷受到的库伦斥力更大,而距离越远的点电荷受到的斥力越小。
对比损失中,越近的负例受到的斥力越大,具体的表现就是对应的负梯度值越大[4]。这种性质更有利于形成在超球面均匀分布的特征。
对照公式去理解:
当温度系数很小时,越相似也即越困难的负例,对应的坟墓就会越大,在分母叠加项中所占的比重就会越大,对整体loss的影响就会越大,具体的表现就是对应的负梯度值越大
当然,这仅仅是提供了一种定性的认识,定量的认识和推导可以参见博客zhihu
with supervised learning
借鉴了contrastive的设计在监督信息的基础上对其进行改造,设计一个用于监督学习的对比损失。这一点也可以解决我们问题设置中的第一个问题,但是为此也只能在监督的情况下使用。
其实也就是当标签相同的时候都当作正例,其他时候都是负例,也就是修改了原本状态下positive的情况。
在训练的过程中,该方法和two-stage会使用同样的策略,也就是在第一阶段使用SCL训练Backbone,在第二阶段固定representation的参数,并只对clf的参数进行训练。
Code Part
understand the code;Offical Code;
- 如果我们需要理解这串代码如何使用,我们需要阅读官方源码中的数据使用模式,我们需要使用图像的两组不同增强,计算对应的特征,然后整合到n_views维度,再将其传入该损失。
- 后续我们可以基于NXTent Loss函数来简化和改写该损失,目前我们只需要对其加入Normalization就可以暂时进行使用了,第一步我们使用大的batchsize来代替2Augs,如果效果不好的话可以测试2Augs是否会有更好的增益
1 | |
with ArcFace
对比学习损失我们知道其目的是为了,拉近相似样本之间的距离,并尽量的将不同的类别之间的样本区分,而这和进行人脸识别中的$ArcFace Loss$系列的Softmax Loss有着相同的目的。
那么这两种方法之间是否能够相互借鉴,或者说是否NCE本身在自监督学习任务上就更优于ArcFace?(是否会过度关注细节,无法关注到相应的整体架构)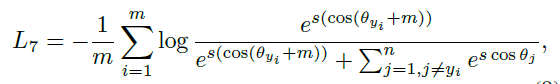
或者说在后续的分类器训练过程中,这样是否能够帮助我们使用聚类的方式进行分类?(结合epoch-control的那种方法)进行fine-tuning等等
reference
- “Understanding the Behaviour of Contrastive Loss” CVPR2021
- Analysis The InfoNCE-Loss
Loss-NCE






