
Fluent Python 01 数据模型与结构
Chapter 1 数据模型
Se1 magic method
数据模型在这里的定义是对python框架的描述,他规范了python构建模块的接口;这些接口对应解释器中对一些特殊句法(常用句法)的激活和使用.本章节的核心就在于对这些特殊句法的理解和使用.
特殊方法带来的一些主要交互场景:
- 迭代
- 属性访问
- 集合类
- 函数和方法的调用
- 对象的创建和销毁
- 字符串的表示形式和格式化
- 上下文管理模块(with模块)
这些特殊方法的存在实际上,是为了让python的解释器调用,除非我们有大量的元编程,否则我们一般不调用他,通过内置的len等函数进行调用的话,他们的速度更快
下面我们通过最典型的__getitem__和__len__对其有简单的介绍, 并介绍各个魔术方法的使用场景
Se2 using it and show more
最常用也最典型的magic method 不外乎__getitem__和__len__;
- len即对当前对象提供对于通用的
len()方法的接口,通常用于查看对象的length or size - getitem除了提供
obj[index]的索引方式的同时,- 他也会对python内置的那些迭代方法提供支持
for i in range(b) - 对于依托于这些迭代的方法也能够得以支持
from random import choice - 切片操作
- 他也会对python内置的那些迭代方法提供支持
Se2.1 overwrite operator
这一部分我们主要介绍如下的一些特殊方法,他们将实现+,*,abs,print,bool
对应的特殊方法可以从下面的代码中领会
1 | |
在这里需要注意的是,中缀运算符像add,mul的原则都是不改变操作对象,而是生成一个新的对象.
se2.2 show more
这一部分我们会展示更多的一些特殊方法,对这些特殊方法的了解也方便我们对python中方法运行的一些掌握

这些特殊方法的使用场景很容易从命名中可以得到一个基本的认知,像迭代,调用,集合等等的这些属性可能是相对常用的,要熟练进行掌握

例如__str__ | __repr__的方法,就可以方便我们进行print和相应的调试输出.
_iadd_ 对应的是+=的这种原地操作, 这个也是我们需要注意的
Chapter 2 数据结构
python的一个重要特点就在于多种数据结构上的操作通用性, 无论是字符串,列表,字节序列,XML元素,他们都公用一套丰富的操作.
此外在python的函数中, 当我们对一个对象进行就地改动, 那他就应该返回None, 这样可以让调用者知道传入的参数发生了改变, 并未产生新的对象, 这种约定俗成的定义方法, 实际上是一种好的习惯.
迭代, 切片, 排序, 拼接
在这里我们还是要熟悉一下各种类型支持的一些操作, 在python中我们可以通过help(list)查看, 当然最好还是做一个简单的总结熟悉对应的数据结构的一些默认方法.
se 1 序列构成的数组
se 1.1 类型概念
python标准库用C实现了丰富的序列类型, 列举如下.
| 序列类型 | 具体类型 | 类型特点 |
|---|---|---|
| 容器序列 | list, tuple, collections.deque | 存放不同数据的类型 |
| 扁平序列 | str, bytes, bytearray, memoryview, array.array | 只能容纳一种类型 |
| 说明 | 上面是第一种分类情况, 下面会介绍另一种分类. 具体的特点会在下面介绍 |
|
| 可变序列 | list, bytearray, array.array, collections.deque, memoryview | 支持增删改 |
| 不可变序列 | tuple, str, bytes | 不支持增删改 |
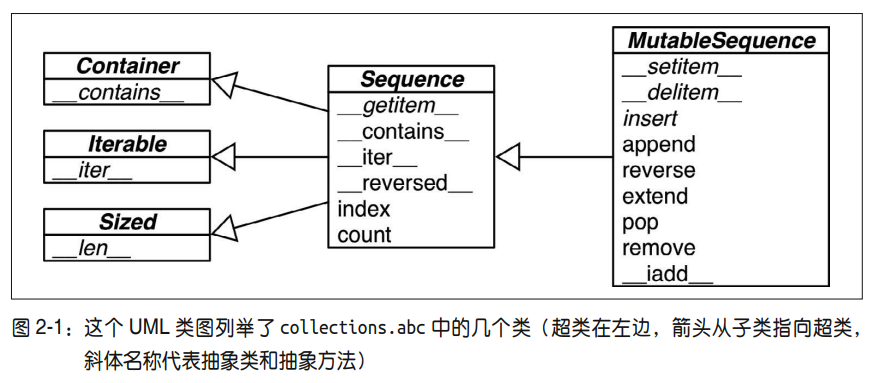
通过这些类别中共有和非公有的特性,我们对这些序列的不同概念进行理解。
se 1.2 列表推导&生成器表达式
生成器表达式和列表推导式的区别,
list是python中重要的一个可变序列类型,列表推导式是我们构建列表的快捷方式,生成器表达式则是创建其他任何类型的序列。
列表推导式:
1 | |
生成器表达式:
首先理解生成器和推导式的区别,推导式是直接完成整体的构建,而生成器是逐步的餐厨我们需要的元素,需要几个就产生几个,使用yield方法进行创建,而生成器表达式可以在没有该表达式的情况下及时创建简化生成器。
而在编写的时候和列表推导式的区别是,用()代替[]即可
1 | |
生成器会逐个产出元素而不会一次性生成,所以实际上这种方法更有内存效率
se 1. 3 循环的本质
和迭代器有重要的关系,有iter方法都能进行迭代,我们可以用hasattr检查
1 | |
循环的后台会发生如下的流程:
iter()将对象转换为迭代器对象next()逐渐获取序列的下一个元素stopiteration没有要调用的元素引发异常
se 1.4 tuple不止不可变
tuple的不可变属性更应该作为一个record这种信息载体来使用,他的这种不可变的特性,让他的position和对应的存储都显得有意义,我们可以通过_占位*解包等操作,来对我们的数据进行读取和管理。
这里拆包的灵活使用是一个重点,用*ignore来跳过我们不需要的那些元素,也可以通过fmt来灵活的拆出嵌套元素
1 | |

元组本身已经设计得不错, 但是作为记录来用的话, 我们通常需要给字段一个名称, nametuple就为我们解决这个问题:
collections.namedtuple用来构建一个带字段名的元组和一个有名字的类,这个有名字的类帮助我们调试.
1 | |
该collections.namedtuple除了元组的属性以外还行增了一些特性, 常用的有如下两个
_fields返回包含所有字段的元组_asdict()将具名元组转换为collections.OrderedDict_make()接受可迭代对象来生成类的一个实例, 也就是可以用*解包的方式来生成一个实例, 而这种方法在元组中是不可用的1
2name_data = (v1,v2,v3)
name = contact._make(*name_data)
se 1 5 切片
这一块切片的设计逻辑讲的很好, 为何从零开始且不包括最后一个, 会为我们带来很多操作上和可读性上的便利, 具体看书.
slice(start, stop, step)实现切片对象, 或者slice(stop)
1 | |
可以使用切片对象的方式能够将我们的切片规则参数化, 方便我们去设置和约定.
省略号在python中的表示是..., 这种用来作为多维切片的时候可能会用到
1 | |
se 1.6 对序列使用+ *
序列使用*n的时候, 通常是建立一个新的对象, 但是如果序列中是对其他可变对象的引用的到时候, 实际上会得到n个引用结果.
1 | |
python的传值类型大多数情况下都是reference assign, 有时候我们对这种对象进行赋值的时候, 我们需要使用深拷贝来进行值的拷贝.
+=是否有_iadd_的实现, 有很大的区别, a+b对应的是实现一个新的对象的产生, 我们可以通过id来进行检查. 如果不断没有必要的产生新的对象的话, 会存在比较大的浪费.
se 1.7 list.sort 和sorted
list.sort就地修改, 返回Nonesort(list)新建一个列表作为返回值, 可接受任何形式的可迭代对象, 最终返回的都是列表.
函数有两个关键词reverse, key: 指定排序的标准.
用bisect来管理已排序的序列: 主要有两个函数bisect和insort, 通过这两个函数使用二分查找法在有序序列中查找或插入元素.
se 1.8 其他序列数据结构
列表虽然好用,但也不是万能的,再一些特定的情况下,有特定的数据结构能更好的支持对应的操作。
如果我们要存放大量的数据,这种时候array的效率要高得多(存放的是机器翻译),而吐过我们频繁的进行先进先出的策略deque的速度应该更快;
同样,如果我们需要频繁的检查一个元素是否出现在一个集合中,要考虑使用set(无序)
数组ARRAY:
如果我们只需要一个包含数字的列表,那么array.array会比list更加高效,同样他也支持所有可变序列相关的操作,pop,insert,extend,也提供共文件读取和存储的更快的操作:.frombytes, .tofild
array在使用的过程中需要指定存储的类型码(具体使用的时候查阅):floats = array('d', (random() for i in range(10**7)))
存取大数组到array的二进制文件比存储到文本文件中快60倍, 因为这种操作中避免了float函数的执行, 写入同样的也快7倍, 同时占用的空间更少.
同样pickle处理浮点数组的方式几乎和array一样快, 且pickle可以处理各种各样的数字类型, 甚至简单的自定义类型, 是一个快速序列化数字类型的方法.
memoryview:
内存视图使得用户在不复制内容的情况下操作同一个数组的不同切片. 实际上是Numpy一些功能的简单实现
numpy & scipy:
Numpy实现了多维同质数组和矩阵
Scipy是基于Numpy的科学计算库, 为线性代数,数值积分和统计学设计
collections.deque线程安全, 可以从两端添加或者删除元素. 常用来作为最近用到的几个元素queue同步类Queue, LifoQueue, PriorityQueuemultiprocessing设计为了进程之间的通信heapq当作堆和优先队列来用
Se2 字典和集合
泛映射类型
Chapter 3 把函数视作对象
se 3 函数装饰器和闭包
这一部分不同于之前的
Fluent Python 01 数据模型与结构






