
Knowledge Evolution
Knowledge Evolution in Neural Networks
@Aiken 2021.4.7
Article:只能当成OverView,技术细节写的很差;Mendeley;
Intro引子
Problem:如何在较小的数据集上训练神经网络,这到底是个小样本的方法还是个类别增量的方法?
Motivation: 考虑生物“基因”进化的方式,有一部分是“祖传”,另一部分是“适应”,通过对“祖传”的假设的不断学习进化,得到一个新的模型。
基因编码了从祖先到后代的遗传信息(知识),而基因传递将遗传信息从父母传递至其后代。虽然祖先并不一定具有更好的知识,但是遗传信息(知识)在几代人之间的发展将会促进后代更好的学习曲线。
Hypothesis:
- 拟合假设$H^{origin}$:
- 重置假设:$H^{later}$
TOBEUPDATE:将神经网络拆分成两个假设(子网络):通过重新训练多代网络来进化$H^{origin}$ 中的知识,每一代都会扰乱$H^{later}$的内部权重来鼓励$H^{origin}$ 学习独立的表达形式。
将深度神经网络的知识封装在一个名为拟合假设的子网络H中,将拟合假设的知识从父母网络传递至其后代,即下一代神经网络。并反复重复此过程,在后代网络中证明了其性能的显著提升:
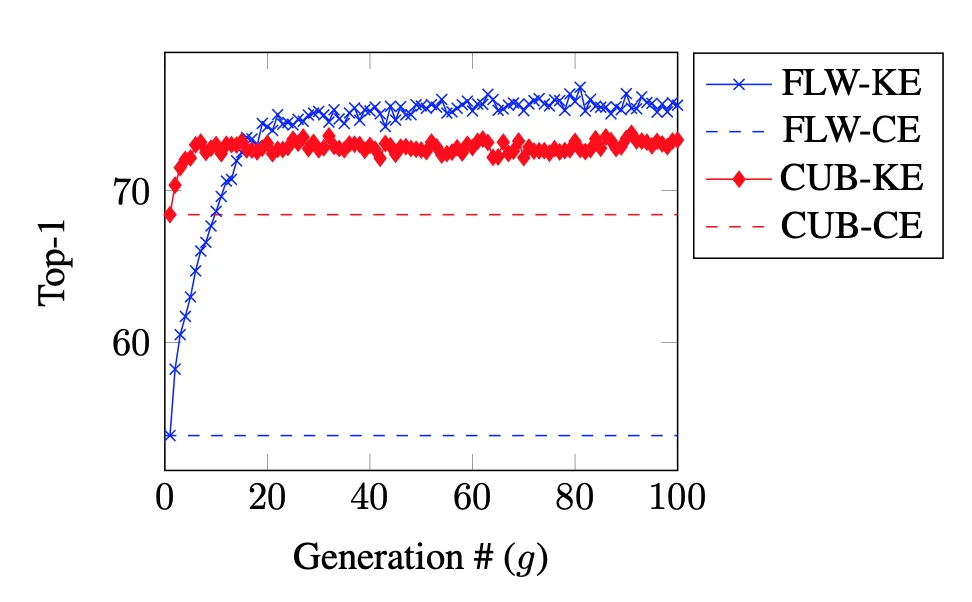
Contribution:
提出了KELS(内核级卷积感知拆分),为CNN量身定做。虽然增加了训练时间,但是大大降低了推理成本,也减轻了较小数据集中的过拟合问题。
- 提出了KE,提升网络在较小数据集上的性能
- KELS,训练时自动学习slim网络,支持CNN,降低推理成本
Related Work
与两种不同的训练方法作比较
DSD:在网络结构上与这种dense-sparse-dense
理论与实现细节
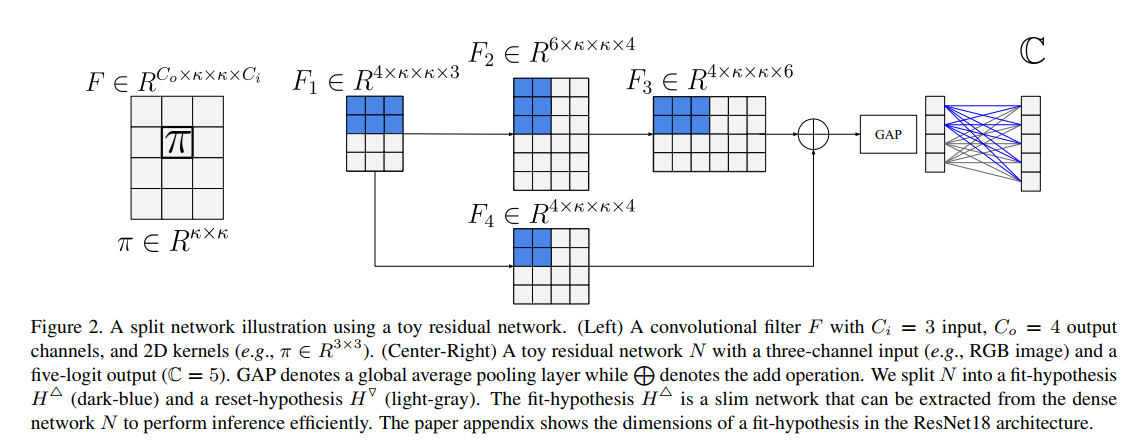
上图展示的是
普通Fliter:3in 4out
修正后在ResNet中的Fliter:拆分成两部分假设,深蓝色的是拟合假设,浅灰色的是重置假设。
The Knowledge Evolution Training Approach
L:layers_num;N:network;F:Fliter(Convolution Kernal)
Z:Batch Norm;W(FC):weight;B(FC):bias;M:0-1 mask(binary)
首先从概念上将网络划分成两个子网的部分,$H^f$、$H^r$,对网络进行随机初始化,然后再e个epoch之后得到generation 1的Network(N1),也就能提取出对应的H.
:star:Iteration(迭代到下一代)
基因的贡献直到对下一代网络进行初始化,后续的操作就是“适者生存的部分了”
#LOOP
- 使用$H^f$重新初始化N:使用$H^f$中的F和W去初始化N2,剩下的部分($H^r$)中的参数进行随机的初始化,初始化的形式可以表达成如下的公式,(随机的部分使用指定好的分布去随机)
- 重新e个epochs训练进化成N2。
#END LOOP
Split-Networks
这个框架在实现的时候涉及到Fliter的拆分,所以这部分实际上是文章的核心技术难点。
使用两种分裂技术来支持KE:
这种玩意你不看代码谁知道在写什么
- weight-level splitting:按照split-rate,使用0-1mask对每一层的参数进行随机的split。
- kernel-level convolutional-aware splitting:代替了对每个单独的权重进行mask,我们直接对kernels做mask,如下图所示
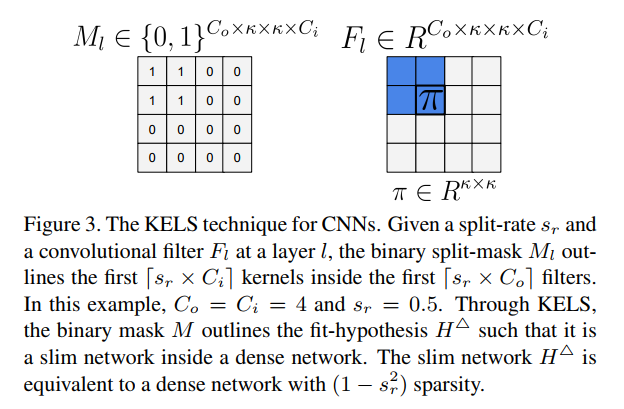
Knowledge Evolution Intuition
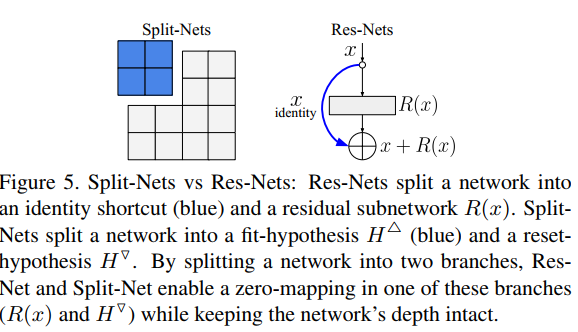
KE的结构和ResNet和Dropout进行对比,之间的异同,一些直观或者直觉上的理解。
Code细节&使用情景
这个方法实际上是针对的小样本?相对少样本?的使用情景,通过不断的部分继承和迭代,用DNA的方式传播到后续的网络结构中,感觉这个的使用场景还挺blur的,TOBECONTIUNE.
这种评估和消融实验的测试方式的选择!
Knowledge Evolution





