
AIGC02 Stable Diffusion 基础功能介绍
本篇章介绍关于 Stable DIffusion 的一些基础概念和 WebUI 的基本功能元素,同时介绍一些启动项和模型加载的东西。
启动项设置(局域网)
最常用的启动项是 --listen,通过该启动项允许局域网内的其他设备通过 ip 和端口访问部署好的 Stable Diffusion 服务。而设置启动项的方式有以下几种:
- 命令行执行启动脚本的时候携带
1 | |
- 修改主入口脚本中的启动选项
vim launch.py
1 | |
模型相关
提供相关模型下载的网址主要有以下几个:
- C站 | AI绘画模型博物馆 (subrecovery.top) | Hugging Face – The AI community building the future.
- Stable Diffusion Models 模型百科
- Stable Diffusion Textual Inversion Embeddings Embeding,不建议访问,我个人好像访问了就很卡
- Stable Diffusion Models (cyberes.github.io) | NOVALAI 该文章中有写,是被黑客泄露的模型
这些网站都会提供各种模型的下载,包括 LoRA、Ckpt、HyperNetwork 等。
模型部署和加载
下载完模型后,我们进到如下的目录中,会发现有针对于各种不同模型的子目录(Lora, stable-diffusion, VAE)等
1 | |
将对应的模型的放到对应的目录中即可,然后重启 stable-diffusion 服务,其会读取路径下的所有模型,在 webui 的对应选项中实现加载。
其中:Ckpt 存放于其中的 stable-diffusion 目录中,是整个生成过程的基础模型,可以在下图所示的地方读取:
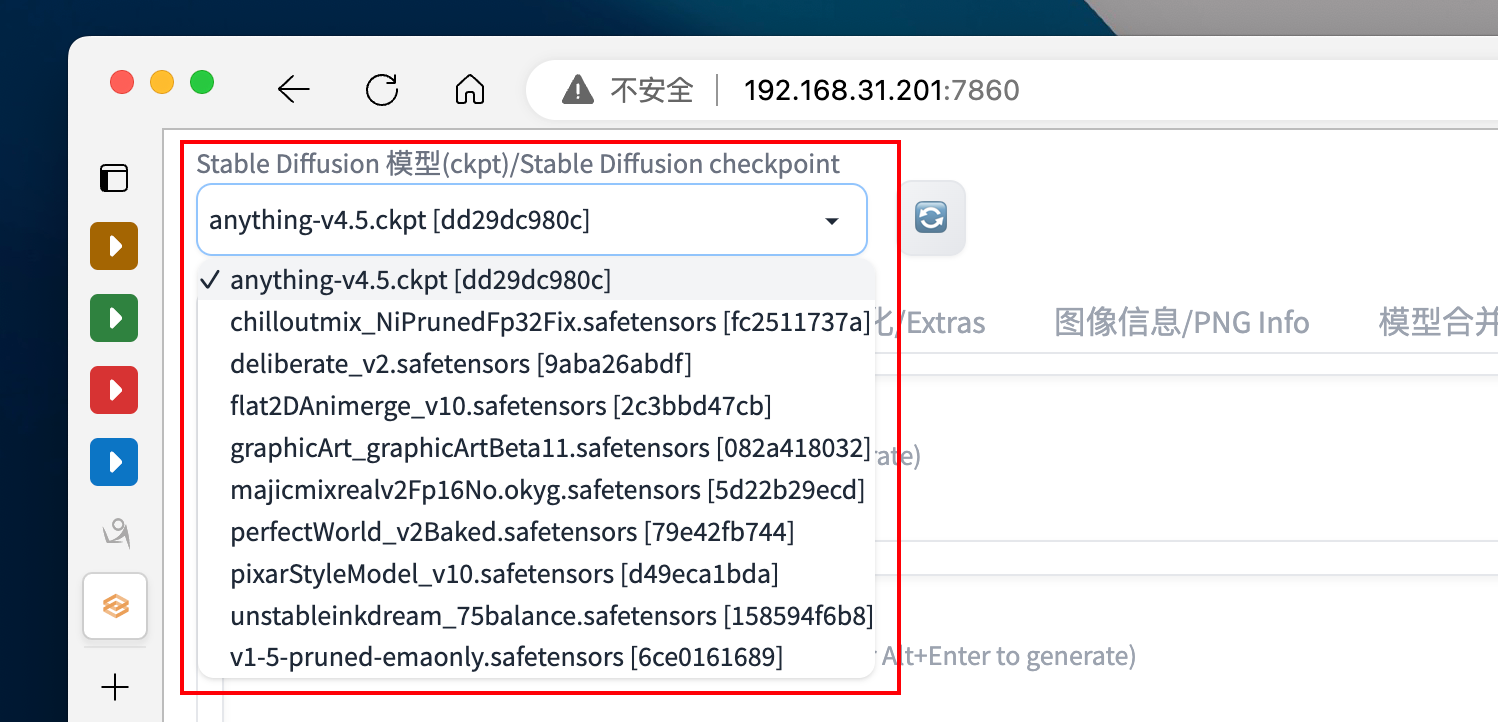
可以看到此处已经加载了诸多我们下载好的 ckpt 模型,并可随意选择和切换。
下面介绍一下各种模型之间的区别:Stable Diffusion中的各种模型
CKPT(Checkpoint)模型
基于某个数据集训练出来的 Stable Diffusion 完整的大模型本身,因此相比于其他的微调模型来说体积一般较大。
Lora 模型
Low-Rank Adaptation of Large Language Models,直译为大语言模型的低阶适应,为了解决大语言模型微调而开发的一项技术,LoRA 的冻结预训练好的大模型模型参数,然后在每个 Transformer 块里注入可训练的层,大大减少了需要训练的计算量。
- Stable Diffusion爱好者常说的LoRa是什么?
- Using LoRA for Efficient Stable Diffusion Fine-Tuning (huggingface.co)
- cloneofsimo/lora: Using Low-rank adaptation to quickly fine-tune diffusion models. (github.com)
- LORA: LOW-RANK ADAPTATION OF LARGE LAN GUAGE MODELS:官方论文
VAE 模型
Variational autoencoder,变分自编码器,负责做隐含空间和 RGB 空间的变换,可以实现添加滤镜和风格的效果,通常来说大模型中会包含该部分变换,不是所有的模型都适合一起使用。
Hypernetwork 网络
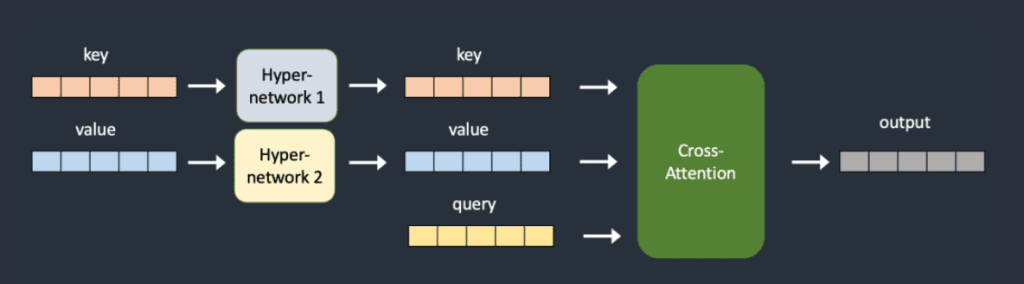
Hypernetwork 是一种微调技术,最初由 Novel AI 开发,他们是 Stable Diffusion 的早期采用者。它是一个小型神经网络,附加在 Stable Diffusion 模型上以修改其风格。插入到噪声预测器 UNet 的交叉注意力模块中,通常情况下,hypernetwork 是一个简单的神经网络:具有 dropout 和激活函数的全连接线性网络。它通过插入两个转换 key 和 query 向量的网络来劫持交叉注意力模块。
Embedding 嵌入
文本嵌入,应该和 HyperNetwork 类似,通过影响 Prompt 的嵌入构建过程来实现特定风格的方法,作为原本网络的拓展组件或者控制器来使用。
使用这些模型的地方我们将在下面的页面基本功能元素一起介绍:这些参数或者模型主要是作为 Additional Network 来使用的,这个我们后续介绍使用的方式,其对 Ckpt 进行进一步的调整,因此不同的搭配使用本身可能会有不同的效果。
需要注意的是,各个模型,各个参数可能都会有各自生成的类型偏向性,一些模型可能是专门过拟合某一些风格,因此用的时候对额外网络的比重调整也是个学问。
基本功能介绍
加载完基础模型后,就可以试用各个基础功能了,该章节基于文生图的功能每一部分的操作和配置进行介绍,其他的功能会放在后续小节。
基础结构介绍 Basic
首先从文生图的功能开始介绍,该功能的名字很直观就是通过提供的提示词(Prompt)生成对应的图像,其中控制图片生成的主要有这么几个地方:

- Prompt:描述生成的图像:图像的内容,质量,风格等;
- Negative Prompt:反向提示词,限定一些边界,生成的图像不会包含这其中的内容;
- Sampling:采样器,实际上不是寻常理解上的采样,而是指的扩散方法,即选用生成图像的扩散模型。
- Sampling Steps:采样步骤,同上实际上指的应该是扩散步骤,可以根据显存来调整该步骤,可以适当调大。
- Width、Height:生成图像的分辨率(Shape & Size)
- CFG Scale:提示词关联程度,和提示词的相关程度
- Seed:随机种子,虽然只是一个随机种子,实际上也会很明显的影响图像生成的样式。
设定好了上述对应参数后,就可以点击 Generate 进行图片生成了,右下角的按钮可以将生成的图片转到后续的后处理步骤中,或者保存。
额外模型使用 Additional Networks
如果要加载额外的模型参数,比如说要针对模型额外加载 Lora,具体的操作过程如下图所示:
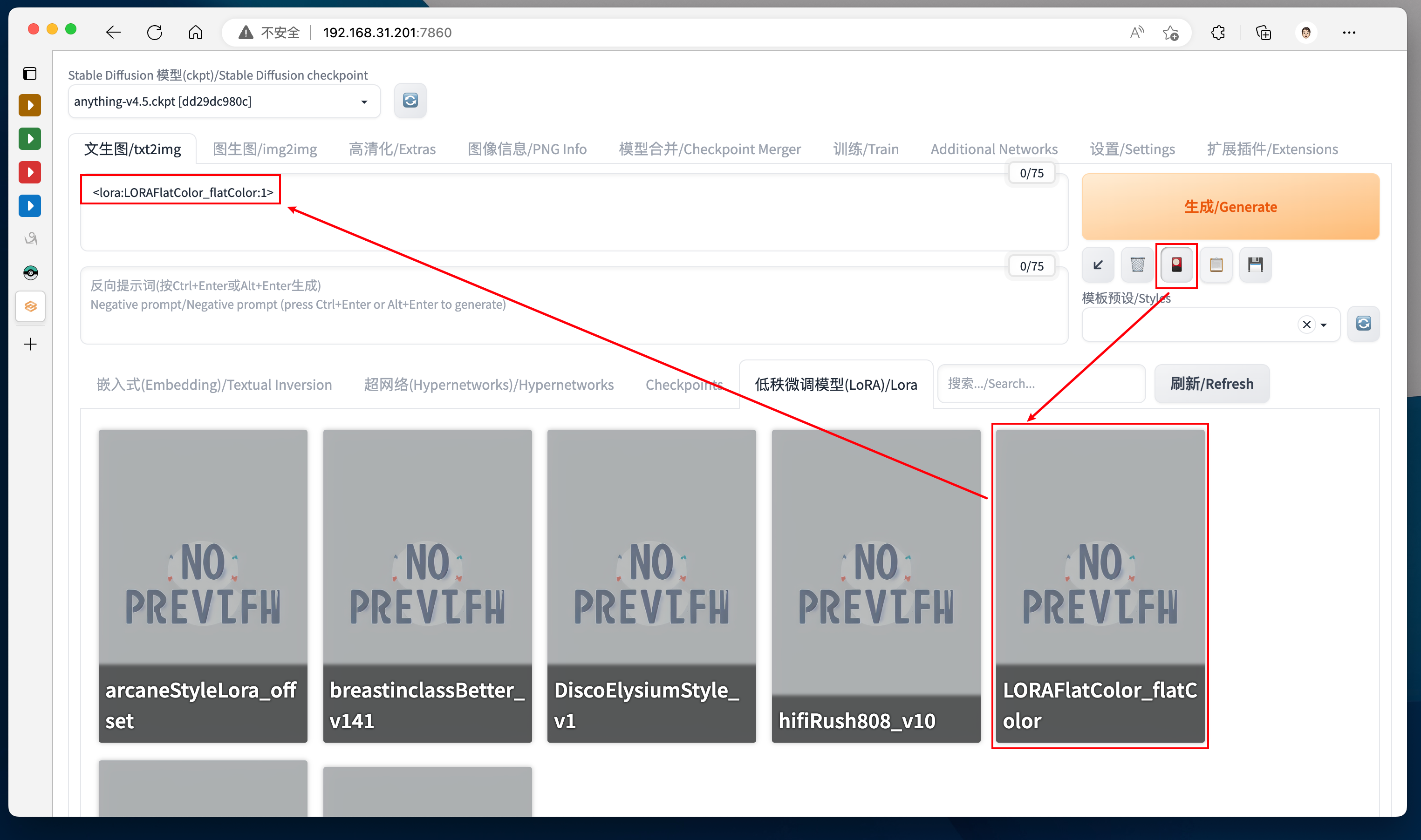
加载: 点击 Additional Network 按钮后 -> 会弹出下面一排界面 -> 选择对应需要的模型种类(比如这里选择了 Lora 选项卡)-> 然后选择一个(或者多个)特定的模型 -> 则该 Lora 模型会以 <model:weight> 的形式出现在 Prompt 的地方,这样就完成了额外模型参数的加载了。
调整思路:
- 这里的权重我们通常不会选择 1,从 0.1 开始向上调整是一个比较好的思路。
- 此外在加载 Lora 的时候,可以参考 C 站中别人和什么 Ckpt 组合使用。
可以看到这里除了 Lora,还有 HyperNetwork 等选项卡,这些可选项都可以使用类似的方式来进行调用。支持同时使用多个,但是权重的调整要自己选择。
此外如果要使用插件来调整 lora 的比例的话,则需要把 lora 模型放到 /extensions/sd-webui-additional-networks/models/lora 中,这里可以使用超链接的方式,然后在 addition network 选项卡下点击刷新按钮:即可。
参数搜索功能 Scripts
stable-diffusion-webui prompt语法详解
由于可供设置的参数数量较多,因此在出一张让人满意的图之前,总免不了各种试,这种时候就需要参数搜索功能来简化整个 workflow,我们设置好需要搜索的参数空间,让 Stable Diffusion 自己逐一的遍历每个参数。
webui 中就提供了这样的功能,可以通过 script 实现各种实验的脚本;也就是下图所示的,Script 选项,其中内置的也提供了几种参数搜索的方式:
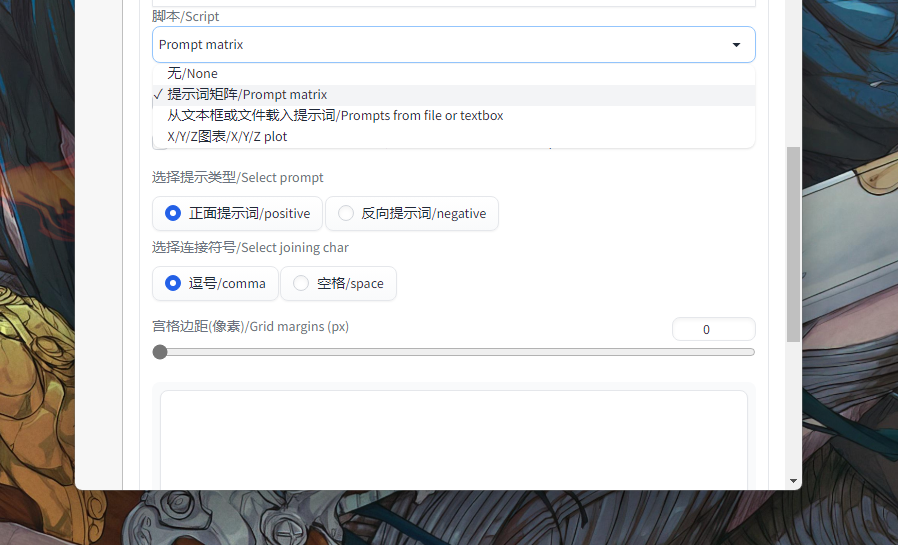
- 非参数搜索)从文件中读取提示词,便于导入导出
- 提示词搜索(即提示词矩阵)
- XYZ Plot,可自定义各种参数的搜索
提示词矩阵功能讲解:用 | 分割 prompt 词,可达到如下的效果,以 a|b 为例,SD 将会生成如下的四种结果:
^a & ^b , a & ^b , b & ^a , a & b
这里顺便提一嘴,用(prompt)可以强化对提示词的关注程度,(prompt:1.5) 即将该 prompt 的关注程度提升为 150%,[prompt] 则是和(prompt) 相反,则是弱化对提示词的关注程度。
XYZ Plot功能讲解:通过设定 2~3 个变量(甚至可以包括模型),可以同时对这三个变量进行排列组合的参数搜索,建议不要把变量范围设置过大,不然搜索空间太大了。
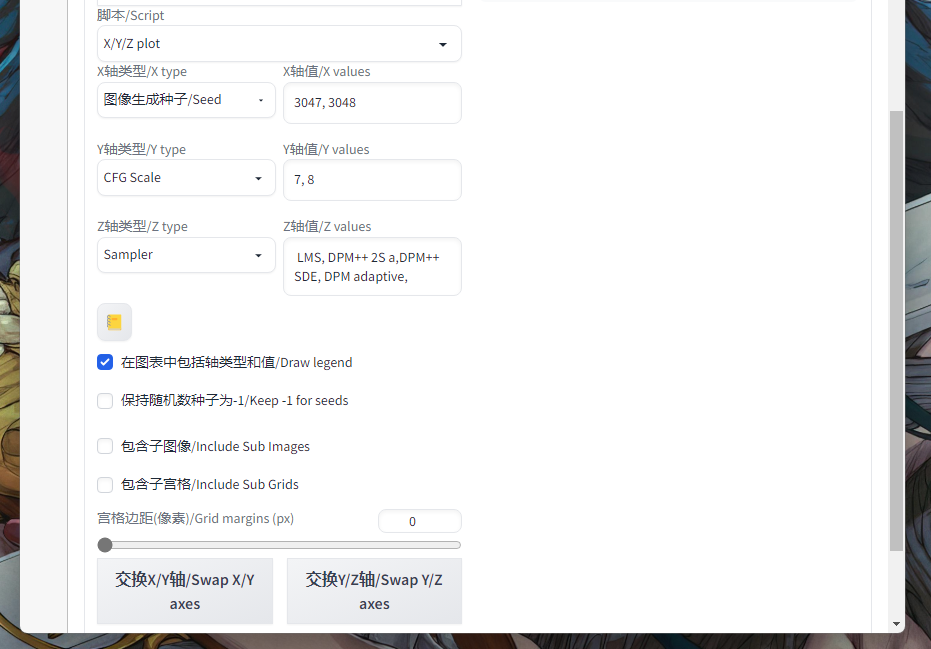
在 XYZ 中选择好对应的变量后,在对应的值选框中,用 , 分割可选的各个变量即可开始进行搜索,最后的结果大概如下,便于让我们找出合适的参数。

其他功能介绍
基于上述对于字生图的功能介绍,基础的功能就大概了解了,接下来拓展介绍一下其他的功能。
图生图功能
图生图的定位是,基于提示词对原图进行重绘改造,核心参数是重绘强度。也可以在文生图之后送到图生图模块中进行逐步的迭代优化。
参考资料:5分钟学会Stable Diffusion图生图功能
这里有个新的核心可配置项为:
- Denoising Strength(重绘强度): 也就是偏离原图的程度,越大和原图越不相似,较常取值于 0.6-0.7 之间
- 同时要注意调整 Size 和原图保持一致,不然原图会被拉伸。
新功能:同时这里也存在两个模型可以帮助我们根据原图去反向推演提示词,上传完图片之后点击这两个其中一个即可反向推演出 Prompt 供我们参考(但是对于生成一个好图还远远不够):
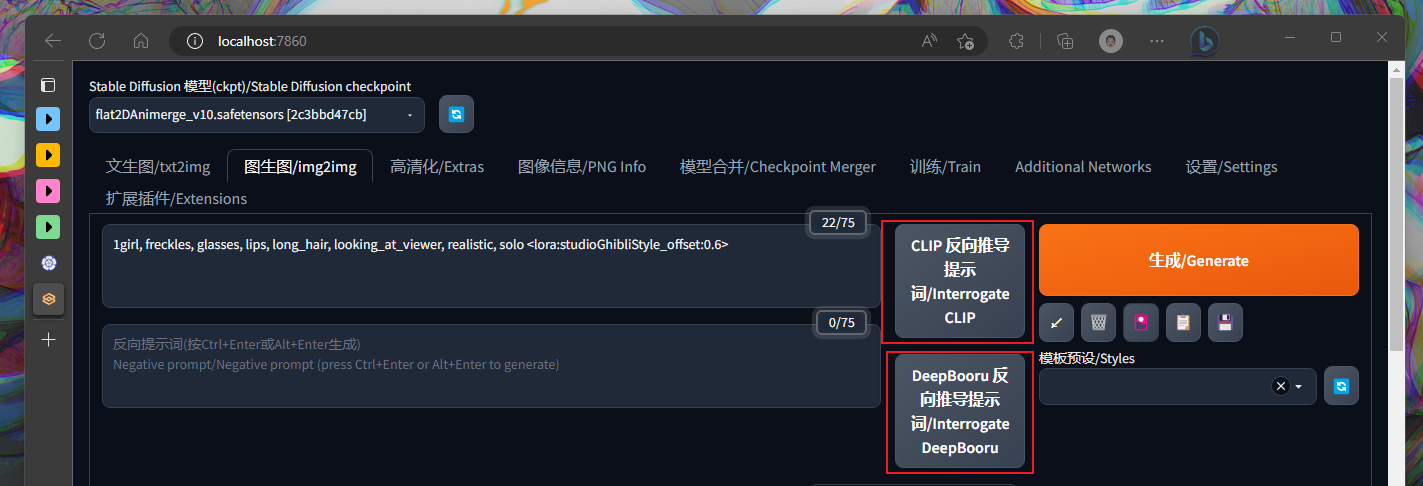
剩下的和文生图一致,就可以基于我们的图片和提示词去生成一张新的图片。
这里还有一些其他的功能做一下简单介绍:
- Sketch:涂鸦绘制,给一张涂鸦和 Prompt 去生成一个新的图片(可以用于作画),会保留草图的颜色信息
- Inpaint:局部绘制,涂抹原图中的部分,并只对该部分进行重新生成,可以换风格,换图案,换脸,换衣服之类的,可以选择重绘蒙版部分或者非蒙版部分的内容,也可以调整蒙版的模糊程度
- Inpaint sketch:两者的结合体,会保留颜色信息进行重绘
- …
高清化功能
简单理解就是超分辨率和面部重建等重建图片质量的一系列模型,无需过多介绍。
图像信息
应该是提取生成图的信息。
FI
本篇章就到这里结束,下一章节会讲一下 Control Net,有时间的话会去淘一下有没有什么插件值得讲解的。本篇章中有希望进一步详细或者让我去了解的也可以留言。
AIGC02 Stable Diffusion 基础功能介绍



