
(转)What the Fuck Python! 一些python特性
![]()
What the f*ck Python! 🐍
一些有趣且鲜为人知的 Python 特性.
Python, 是一个设计优美的解释型高级语言, 它提供了很多能让程序员感到舒适的功能特性. 但有的时候, Python 的一些输出结果对于初学者来说似乎并不是那么一目了然.
这个有趣的项目意在收集 Python 中那些难以理解和反人类直觉的例子以及鲜为人知的功能特性, 并尝试讨论这些现象背后真正的原理!
虽然下面的有些例子并不一定会让你觉得 WTFs, 但它们依然有可能会告诉你一些你所不知道的 Python 有趣特性. 我觉得这是一种学习编程语言内部原理的好办法, 而且我相信你也会从中获得乐趣!
如果您是一位经验比较丰富的 Python 程序员, 你可以尝试挑战看是否能一次就找到例子的正确答案. 你可能对其中的一些例子已经比较熟悉了, 那这也许能唤起你当年踩这些坑时的甜蜜回忆 :sweat_smile:
PS: 如果你不是第一次读了, 你可以在这里获取变动内容.
那么, 让我们开始吧…
Table of Contents/目录
- Table of Contents/目录
- Structure of the Examples/示例结构
- Usage/用法
- 👀 Examples/示例
- Section: Strain your brain!/大脑运动!
- > Strings can be tricky sometimes/微妙的字符串 *
- > Time for some hash brownies!/是时候来点蛋糕了!
- > Return return everywhere!/到处返回!
- > Deep down, we’re all the same./本质上,我们都一样. *
- > For what?/为什么?
- > Evaluation time discrepancy/执行时机差异
- >
isis not what it is!/出人意料的is! - > A tic-tac-toe where X wins in the first attempt!/一蹴即至!
- > The sticky output function/麻烦的输出
- >
is not ...is notis (not ...)/is not ...不是is (not ...) - > The surprising comma/意外的逗号
- > Backslashes at the end of string/字符串末尾的反斜杠
- > not knot!/别纠结!
- > Half triple-quoted strings/三个引号
- > Midnight time doesn’t exist?/不存在的午夜?
- > What’s wrong with booleans?/布尔你咋了?
- > Class attributes and instance attributes/类属性和实例属性
- > yielding None/生成 None
- > Mutating the immutable!/强人所难
- > The disappearing variable from outer scope/消失的外部变量
- > When True is actually False/真亦假
- > From filled to None in one instruction…/从有到无…
- > Subclass relationships/子类关系 *
- > The mysterious key type conversion/神秘的键型转换 *
- > Let’s see if you can guess this?/看看你能否猜到这一点?
- Section: Appearances are deceptive!/外表是靠不住的!
- Section: Watch out for the landmines!/小心地雷!
- > Modifying a dictionary while iterating over it/迭代字典时的修改
- > Stubborn
deloperator/坚强的del* - > Deleting a list item while iterating/迭代列表时删除元素
- > Loop variables leaking out!/循环变量泄漏!
- > Beware of default mutable arguments!/当心默认的可变参数!
- > Catching the Exceptions/捕获异常
- > Same operands, different story!/同人不同命!
- > The out of scope variable/外部作用域变量
- > Be careful with chained operations/小心链式操作
- > Name resolution ignoring class scope/忽略类作用域的名称解析
- > Needle in a Haystack/大海捞针
- Section: The Hidden treasures!/隐藏的宝藏!
- > Okay Python, Can you make me fly?/Python, 可否带我飞? *
- >
goto, but why?/goto, 但为什么? * - > Brace yourself!/做好思想准备 *
- > Let’s meet Friendly Language Uncle For Life/让生活更友好 *
- > Even Python understands that love is complicated/连Python也知道爱是难言的 *
- > Yes, it exists!/是的, 它存在!
- > Inpinity/无限 *
- > Mangling time!修饰时间! *
- Section: Miscellaneous/杂项
- Section: Strain your brain!/大脑运动!
- Contributing/贡献
- Acknowledgements/致谢
- 🎓 License/许可
Structure of the Examples/示例结构
所有示例的结构都如下所示:
> 一个精选的标题 *
标题末尾的星号表示该示例在第一版中不存在,是最近添加的.
2# 准备代码.
# 释放魔法...Output (Python version):
2>>> 触发语句
出乎意料的输出结果
(可选): 对意外输出结果的简短描述.💡 说明:
- 简要说明发生了什么以及为什么会发生.
Output:
如有必要, 举例说明
2>>> 触发语句 # 一些让魔法变得容易理解的例子
# 一些正常的输入
注意: 所有的示例都在 Python 3.5.2 版本的交互解释器上测试过, 如果不特别说明应该适用于所有 Python 版本.
Usage/用法
我个人建议, 最好依次阅读下面的示例, 并对每个示例:
- 仔细阅读设置例子最开始的代码. 如果您是一位经验丰富的 Python 程序员, 那么大多数时候您都能成功预期到后面的结果.
- 阅读输出结果,
- 确认结果是否如你所料.
- 确认你是否知道这背后的原理.
- 如果不知道, 深呼吸然后阅读说明 (如果你还是看不明白, 别沉默! 可以在这提个 issue).
- 如果知道, 给自己点奖励, 然后去看下一个例子.
PS: 你也可以在命令行阅读 WTFpython. 我们有 pypi 包 和 npm 包(支持代码高亮).(译: 这两个都是英文版的)
安装 npm 包 wtfpython1
$ npm install -g wtfpython
或者, 安装 pypi 包 wtfpython1
$ pip install wtfpython -U
现在, 在命令行中运行 wtfpython, 你就可以开始浏览了.
👀 Examples/示例
Section: Strain your brain!/大脑运动!
> Strings can be tricky sometimes/微妙的字符串 *
1.1
2
3
4
5>>> a = "some_string"
>>> id(a)
140420665652016
>>> id("some" + "_" + "string") # 注意两个的id值是相同的.
140420665652016
2.
1 | |
3.1
2
3
4>>> 'a' * 20 is 'aaaaaaaaaaaaaaaaaaaa'
True
>>> 'a' * 21 is 'aaaaaaaaaaaaaaaaaaaaa'
False # 3.7 版本返回结果为 True
很好理解, 对吧?
💡 说明:
- 这些行为是由于 Cpython 在编译优化时, 某些情况下会尝试使用已经存在的不可变对象而不是每次都创建一个新对象. (这种行为被称作字符串的驻留[string interning])
- 发生驻留之后, 许多变量可能指向内存中的相同字符串对象. (从而节省内存)
在上面的代码中, 字符串是隐式驻留的. 何时发生隐式驻留则取决于具体的实现. 这里有一些方法可以用来猜测字符串是否会被驻留:
- 所有长度为 0 和长度为 1 的字符串都被驻留.
- 字符串在编译时被实现 (
'wtf'将被驻留, 但是''.join(['w', 't', 'f'])将不会被驻留) 字符串中只包含字母,数字或下划线时将会驻留. 所以
'wtf!'由于包含!而未被驻留. 可以在这里找到 CPython 对此规则的实现.
当在同一行将
a和b的值设置为"wtf!"的时候, Python 解释器会创建一个新对象, 然后同时引用第二个变量(译: 仅适用于3.7以下, 详细情况请看这里). 如果你在不同的行上进行赋值操作, 它就不会“知道”已经有一个wtf!对象 (因为"wtf!"不是按照上面提到的方式被隐式驻留的). 它是一种编译器优化, 特别适用于交互式环境.- 常量折叠(constant folding) 是 Python 中的一种 窥孔优化(peephole optimization) 技术. 这意味着在编译时表达式
'a'*20会被替换为'aaaaaaaaaaaaaaaaaaaa'以减少运行时的时钟周期. 只有长度小于 20 的字符串才会发生常量折叠. (为啥? 想象一下由于表达式'a'*10**10而生成的.pyc文件的大小). 相关的源码实现在这里. - 如果你是使用 3.7 版本中运行上述示例代码, 会发现部分代码的运行结果与注释说明相同. 这是因为在 3.7 版本中, 常量折叠已经从窥孔优化器迁移至新的 AST 优化器, 后者可以以更高的一致性来执行优化. (由 Eugene Toder 和 INADA Naoki 在 bpo-29469 和 bpo-11549 中贡献.)
- (译: 但是在最新的 3.8 版本中, 结果又变回去了. 虽然 3.8 版本和 3.7 版本一样, 都是使用 AST 优化器. 目前不确定官方对 3.8 版本的 AST 做了什么调整.)
> Time for some hash brownies!/是时候来点蛋糕了!
- hash brownie指一种含有大麻成分的蛋糕, 所以这里是句双关
1.1
2
3
4some_dict = {}
some_dict[5.5] = "Ruby"
some_dict[5.0] = "JavaScript"
some_dict[5] = "Python"
Output:1
2
3
4
5
6>>> some_dict[5.5]
"Ruby"
>>> some_dict[5.0]
"Python"
>>> some_dict[5]
"Python"
“Python” 消除了 “JavaScript” 的存在?
💡 说明:
- Python 字典通过检查键值是否相等和比较哈希值来确定两个键是否相同.
- 具有相同值的不可变对象在Python中始终具有相同的哈希值.注意: 具有不同值的对象也可能具有相同的哈希值(哈希冲突).
1
2
3
4>>> 5 == 5.0
True
>>> hash(5) == hash(5.0)
True - 当执行
some_dict[5] = "Python"语句时, 因为Python将5和5.0识别为some_dict的同一个键, 所以已有值 “JavaScript” 就被 “Python” 覆盖了. - 这个 StackOverflow的 回答 漂亮地解释了这背后的基本原理.
> Return return everywhere!/到处返回!
1 | |
Output:1
2>>> some_func()
'from_finally'
💡 说明:
- 当在 “try…finally” 语句的
try中执行return,break或continue后,finally子句依然会执行. - 函数的返回值由最后执行的
return语句决定. 由于finally子句一定会执行, 所以finally子句中的return将始终是最后执行的语句.
> Deep down, we’re all the same./本质上,我们都一样. *
1 | |
Output:1
2
3
4
5
6
7
8>>> WTF() == WTF() # 两个不同的对象应该不相等
False
>>> WTF() is WTF() # 也不相同
False
>>> hash(WTF()) == hash(WTF()) # 哈希值也应该不同
True
>>> id(WTF()) == id(WTF())
True
💡 说明:
- 当调用
id函数时, Python 创建了一个WTF类的对象并传给id函数. 然后id函数获取其id值 (也就是内存地址), 然后丢弃该对象. 该对象就被销毁了. - 当我们连续两次进行这个操作时, Python会将相同的内存地址分配给第二个对象. 因为 (在CPython中)
id函数使用对象的内存地址作为对象的id值, 所以两个对象的id值是相同的. - 综上, 对象的id值仅仅在对象的生命周期内唯一. 在对象被销毁之后, 或被创建之前, 其他对象可以具有相同的id值.
那为什么
is操作的结果为False呢? 让我们看看这段代码.1
2
3class WTF(object):
def __init__(self): print("I")
def __del__(self): print("D")Output:
1
2
3
4
5
6
7
8
9
10
11
12>>> WTF() is WTF()
I
I
D
D
False
>>> id(WTF()) == id(WTF())
I
D
I
D
True正如你所看到的, 对象销毁的顺序是造成所有不同之处的原因.
> For what?/为什么?
1 | |
Output:1
2>>> some_dict # 创建了索引字典.
{0: 'w', 1: 't', 2: 'f'}
💡 说明:
Python 语法 中对
for的定义是:1
for_stmt: 'for' exprlist 'in' testlist ':' suite ['else' ':' suite]其中
exprlist指分配目标. 这意味着对可迭代对象中的每一项都会执行类似{exprlist} = {next_value}的操作.一个有趣的例子说明了这一点:
1
2
3for i in range(4):
print(i)
i = 10Output:
1
2
3
40
1
2
3你可曾觉得这个循环只会运行一次?
💡 说明:
- 由于循环在Python中工作方式, 赋值语句
i = 10并不会影响迭代循环, 在每次迭代开始之前, 迭代器(这里指range(4)) 生成的下一个元素就被解包并赋值给目标列表的变量(这里指i)了.
- 由于循环在Python中工作方式, 赋值语句
在每一次的迭代中,
enumerate(some_string)函数就生成一个新值i(计数器增加) 并从some_string中获取一个字符. 然后将字典some_dict键i(刚刚分配的) 的值设为该字符. 本例中循环的展开可以简化为:1
2
3
4>>> i, some_dict[i] = (0, 'w')
>>> i, some_dict[i] = (1, 't')
>>> i, some_dict[i] = (2, 'f')
>>> some_dict
> Evaluation time discrepancy/执行时机差异
1.1
2
3array = [1, 8, 15]
g = (x for x in array if array.count(x) > 0)
array = [2, 8, 22]
Output:1
2>>> print(list(g))
[8]
2.
1 | |
Output:1
2
3
4
5>>> print(list(g1))
[1,2,3,4]
>>> print(list(g2))
[1,2,3,4,5]
💡 说明
- 在生成器表达式中,
in子句在声明时执行, 而条件子句则是在运行时执行. - 所以在运行前,
array已经被重新赋值为[2, 8, 22], 因此对于之前的1,8和15, 只有count(8)的结果是大于0的, 所以生成器只会生成8. - 第二部分中
g1和g2的输出差异则是由于变量array_1和array_2被重新赋值的方式导致的. - 在第一种情况下,
array_1被绑定到新对象[1,2,3,4,5], 因为in子句是在声明时被执行的, 所以它仍然引用旧对象[1,2,3,4](并没有被销毁). - 在第二种情况下, 对
array_2的切片赋值将相同的旧对象[1,2,3,4]原地更新为[1,2,3,4,5]. 因此g2和array_2仍然引用同一个对象(这个对象现在已经更新为[1,2,3,4,5]).
> is is not what it is!/出人意料的is!
下面是一个在互联网上非常有名的例子.
1 | |
💡 说明:
is 和 == 的区别
is运算符检查两个运算对象是否引用自同一对象 (即, 它检查两个运算对象是否相同).==运算符比较两个运算对象的值是否相等.- 因此
is代表引用相同,==代表值相等. 下面的例子可以很好的说明这点,1
2
3
4>>> [] == []
True
>>> [] is [] # 这两个空列表位于不同的内存地址.
False
256 是一个已经存在的对象, 而 257 不是
当你启动Python 的时候, 数值为 -5 到 256 的对象就已经被分配好了. 这些数字因为经常被使用, 所以会被提前准备好.
Python 通过这种创建小整数池的方式来避免小整数频繁的申请和销毁内存空间.
引用自 https://docs.python.org/3/c-api/long.html
当前的实现为-5到256之间的所有整数保留一个整数对象数组, 当你创建了一个该范围内的整数时, 你只需要返回现有对象的引用. 所以改变1的值是有可能的. 我怀疑这种行为在Python中是未定义行为. :-)
1 | |
这里解释器并没有智能到能在执行 y = 257 时意识到我们已经创建了一个整数 257, 所以它在内存中又新建了另一个对象.
当 a 和 b 在同一行中使用相同的值初始化时,会指向同一个对象.
1 | |
- 当 a 和 b 在同一行中被设置为
257时, Python 解释器会创建一个新对象, 然后同时引用第二个变量. 如果你在不同的行上进行, 它就不会 “知道” 已经存在一个257对象了. - 这是一种特别为交互式环境做的编译器优化. 当你在实时解释器中输入两行的时候, 他们会单独编译, 因此也会单独进行优化. 如果你在
.py文件中尝试这个例子, 则不会看到相同的行为, 因为文件是一次性编译的.
> A tic-tac-toe where X wins in the first attempt!/一蹴即至!
1 | |
Output:1
2
3
4
5
6
7
8
9>>> board
[['', '', ''], ['', '', ''], ['', '', '']]
>>> board[0]
['', '', '']
>>> board[0][0]
''
>>> board[0][0] = "X"
>>> board
[['X', '', ''], ['X', '', ''], ['X', '', '']]
我们有没有赋值过3个 “X” 呢?
💡 说明:
当我们初始化 row 变量时, 下面这张图展示了内存中的情况。
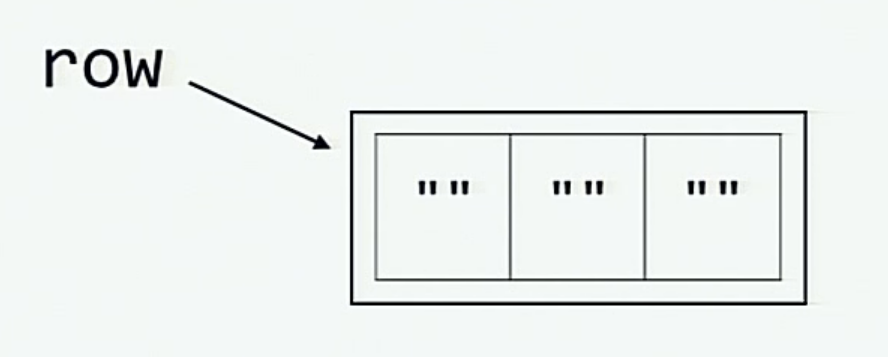
而当通过对 row 做乘法来初始化 board 时, 内存中的情况则如下图所示 (每个元素 board[0], board[1] 和 board[2] 都和 row 一样引用了同一列表.)
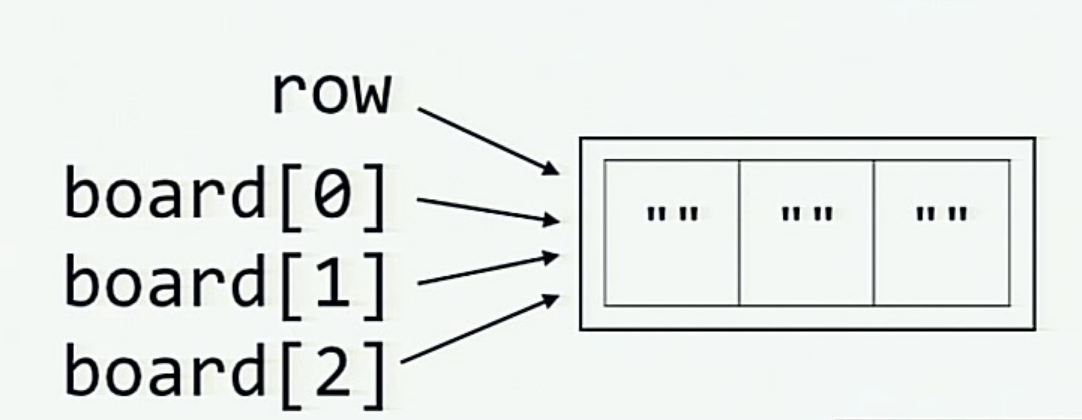
我们可以通过不使用变量 row 生成 board 来避免这种情况. (这个issue提出了这个需求.)
1 | |
> The sticky output function/麻烦的输出
1 | |
Output:1
2
3
4>>> results
[0, 1, 2, 3, 4, 5, 6]
>>> funcs_results
[6, 6, 6, 6, 6, 6, 6]
即使每次在迭代中将 some_func 加入 funcs 前的 x 值都不相同, 所有的函数还是都返回6.
// 再换个例子
1 | |
💡 说明:
当在循环内部定义一个函数时, 如果该函数在其主体中使用了循环变量, 则闭包函数将与循环变量绑定, 而不是它的值. 因此, 所有的函数都是使用最后分配给变量的值来进行计算的.
可以通过将循环变量作为命名变量传递给函数来获得预期的结果. 为什么这样可行? 因为这会在函数内再次定义一个局部变量.
1
2
3
4
5funcs = []
for x in range(7):
def some_func(x=x):
return x
funcs.append(some_func)Output:
1
2
3>>> funcs_results = [func() for func in funcs]
>>> funcs_results
[0, 1, 2, 3, 4, 5, 6]
> is not ... is not is (not ...)/is not ... 不是 is (not ...)
1 | |
💡 说明:
is not是个单独的二元运算符, 与分别使用is和not不同.- 如果操作符两侧的变量指向同一个对象, 则
is not的结果为False, 否则结果为True.
> The surprising comma/意外的逗号
Output:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16>>> def f(x, y,):
... print(x, y)
...
>>> def g(x=4, y=5,):
... print(x, y)
...
>>> def h(x, **kwargs,):
File "<stdin>", line 1
def h(x, **kwargs,):
^
SyntaxError: invalid syntax
>>> def h(*args,):
File "<stdin>", line 1
def h(*args,):
^
SyntaxError: invalid syntax
💡 说明:
- 在Python函数的形式参数列表中, 尾随逗号并不一定是合法的.
- 在Python中, 参数列表部分用前置逗号定义, 部分用尾随逗号定义. 这种冲突导致逗号被夹在中间, 没有规则定义它.(译:这一句看得我也很懵逼,只能强翻了.详细解释看下面的讨论帖会一目了然.)
- 注意: 尾随逗号的问题已经在Python 3.6中被修复了. 而这篇帖子中则简要讨论了Python中尾随逗号的不同用法.
> Backslashes at the end of string/字符串末尾的反斜杠
Output:1
2
3
4
5
6
7
8
9
10>>> print("\\ C:\\")
\ C:\
>>> print(r"\ C:")
\ C:
>>> print(r"\ C:\")
File "<stdin>", line 1
print(r"\ C:\")
^
SyntaxError: EOL while scanning string literal
💡 说明:
- 在以
r开头的原始字符串中, 反斜杠并没有特殊含义.1
2>>> print(repr(r"wt\"f"))
'wt\\"f' - 解释器所做的只是简单的改变了反斜杠的行为, 因此会直接放行反斜杠及后一个的字符. 这就是反斜杠在原始字符串末尾不起作用的原因.
> not knot!/别纠结!
1 | |
Output:1
2
3
4
5
6
7>>> not x == y
True
>>> x == not y
File "<input>", line 1
x == not y
^
SyntaxError: invalid syntax
💡 说明:
- 运算符的优先级会影响表达式的求值顺序, 而在 Python 中
==运算符的优先级要高于not运算符. - 所以
not x == y相当于not (x == y), 同时等价于not (True == False), 最后的运算结果就是True. - 之所以
x == not y会抛一个SyntaxError异常, 是因为它会被认为等价于(x == not) y, 而不是你一开始期望的x == (not y). - 解释器期望
not标记是not in操作符的一部分 (因为==和not in操作符具有相同的优先级), 但是它在not标记后面找不到in标记, 所以会抛出SyntaxError异常.
> Half triple-quoted strings/三个引号
Output:1
2
3
4
5
6
7>>> print('wtfpython''')
wtfpython
>>> print("wtfpython""")
wtfpython
>>> # 下面的语句会抛出 `SyntaxError` 异常
>>> # print('''wtfpython')
>>> # print("""wtfpython")
💡 说明:
- Python 提供隐式的字符串连接, 例如,
1
2
3
4>>> print("wtf" "python")
wtfpython
>>> print("wtf" "") # or "wtf"""
wtf '''和"""在 Python中也是字符串定界符, Python 解释器在先遇到三个引号的的时候会尝试再寻找三个终止引号作为定界符, 如果不存在则会导致SyntaxError异常.
> Midnight time doesn’t exist?/不存在的午夜?
1 | |
Output:1
('Time at noon is', datetime.time(12, 0))
midnight_time 并没有被输出.
💡 说明:
在Python 3.5之前, 如果 datetime.time 对象存储的UTC的午夜时间(译: 就是 00:00), 那么它的布尔值会被认为是 False. 当使用 if obj: 语句来检查 obj 是否为 null 或者某些“空”值的时候, 很容易出错.
> What’s wrong with booleans?/布尔你咋了?
1.1
2
3
4
5
6
7
8
9
10# 一个简单的例子, 统计下面可迭代对象中的布尔型值的个数和整型值的个数
mixed_list = [False, 1.0, "some_string", 3, True, [], False]
integers_found_so_far = 0
booleans_found_so_far = 0
for item in mixed_list:
if isinstance(item, int):
integers_found_so_far += 1
elif isinstance(item, bool):
booleans_found_so_far += 1
Output:1
2
3
4>>> integers_found_so_far
4
>>> booleans_found_so_far
0
2.1
2
3
4another_dict = {}
another_dict[True] = "JavaScript"
another_dict[1] = "Ruby"
another_dict[1.0] = "Python"
Output:1
2>>> another_dict[True]
"Python"
3.1
2
3
4
5
6>>> some_bool = True
>>> "wtf"*some_bool
'wtf'
>>> some_bool = False
>>> "wtf"*some_bool
''
💡 说明:
布尔值是
int的子类1
2
3
4>>> isinstance(True, int)
True
>>> isinstance(False, int)
True所以
True的整数值是1, 而False的整数值是0.1
2>>> True == 1 == 1.0 and False == 0 == 0.0
True关于其背后的原理, 请看这个 StackOverflow 的回答.
> Class attributes and instance attributes/类属性和实例属性
1.1
2
3
4
5
6
7
8class A:
x = 1
class B(A):
pass
class C(A):
pass
Output:1
2
3
4
5
6
7
8
9
10
11
12
13
14>>> A.x, B.x, C.x
(1, 1, 1)
>>> B.x = 2
>>> A.x, B.x, C.x
(1, 2, 1)
>>> A.x = 3
>>> A.x, B.x, C.x
(3, 2, 3)
>>> a = A()
>>> a.x, A.x
(3, 3)
>>> a.x += 1
>>> a.x, A.x
(4, 3)
2.1
2
3
4
5
6
7
8class SomeClass:
some_var = 15
some_list = [5]
another_list = [5]
def __init__(self, x):
self.some_var = x + 1
self.some_list = self.some_list + [x]
self.another_list += [x]
Output:
1 | |
💡 说明:
- 类变量和实例变量在内部是通过类对象的字典来处理(译: 就是
__dict__属性). 如果在当前类的字典中找不到的话就去它的父类中寻找. +=运算符会在原地修改可变对象, 而不是创建新对象. 因此, 在这种情况下, 修改一个实例的属性会影响其他实例和类属性.
> yielding None/生成 None
1 | |
Output:1
2
3
4
5
6
7
8
9
10>>> [x for x in some_iterable]
['a', 'b']
>>> [(yield x) for x in some_iterable]
<generator object <listcomp> at 0x7f70b0a4ad58>
>>> list([(yield x) for x in some_iterable])
['a', 'b']
>>> list((yield x) for x in some_iterable)
['a', None, 'b', None]
>>> list(some_func((yield x)) for x in some_iterable)
['a', 'something', 'b', 'something']
💡 说明:
- 来源和解释可以在这里找到: https://stackoverflow.com/questions/32139885/yield-in-list-comprehensions-and-generator-expressions
- 相关错误报告: http://bugs.python.org/issue10544
- 这个bug在3.7以后的版本中不被推荐使用, 并在3.8中被修复. 因此在3.8中尝试在推导式中使用 yield, 只会得到一个 SyntaxError. 详细内容可以看3.7更新内容, 3.8更新内容.
> Mutating the immutable!/强人所难
1 | |
Output:1
2
3
4
5
6
7
8
9>>> some_tuple[2] = "change this"
TypeError: 'tuple' object does not support item assignment
>>> another_tuple[2].append(1000) # 这里不出现错误
>>> another_tuple
([1, 2], [3, 4], [5, 6, 1000])
>>> another_tuple[2] += [99, 999]
TypeError: 'tuple' object does not support item assignment
>>> another_tuple
([1, 2], [3, 4], [5, 6, 1000, 99, 999])
我还以为元组是不可变的呢…
💡 说明:
引用 https://docs.python.org/2/reference/datamodel.html
不可变序列
不可变序列的对象一旦创建就不能再改变. (如果对象包含对其他对象的引用,则这些其他对象可能是可变的并且可能会被修改; 但是,由不可变对象直接引用的对象集合不能更改.)+=操作符在原地修改了列表. 元素赋值操作并不工作, 但是当异常抛出时, 元素已经在原地被修改了.
(译: 对于不可变对象, 这里指tuple, += 并不是原子操作, 而是 extend 和 = 两个动作, 这里 = 操作虽然会抛出异常, 但 extend 操作已经修改成功了. 详细解释可以看这里)
> The disappearing variable from outer scope/消失的外部变量
1 | |
Output (Python 2.x):1
2>>> print(e)
# prints nothing
Output (Python 3.x):1
2>>> print(e)
NameError: name 'e' is not defined
💡 说明:
出处: https://docs.python.org/3/reference/compound_stmts.html#except
当使用
as为目标分配异常的时候, 将在except子句的末尾清除该异常.这就好像
1
2except E as N:
foo会被翻译成
1
2
3
4
5except E as N:
try:
foo
finally:
del N这意味着异常必须在被赋值给其他变量才能在
except子句之后引用它. 而异常之所以会被清除, 则是由于上面附加的回溯信息(trackback)会和栈帧(stack frame)形成循环引用, 使得该栈帧中的所有本地变量在下一次垃圾回收发生之前都处于活动状态.(译: 也就是说不会被回收)子句在 Python 中并没有独立的作用域. 示例中的所有内容都处于同一作用域内, 所以变量
e会由于执行了except子句而被删除. 而对于有独立的内部作用域的函数来说情况就不一样了. 下面的例子说明了这一点:1
2
3
4
5
6def f(x):
del(x)
print(x)
x = 5
y = [5, 4, 3]Output:
1
2
3
4
5
6
7
8>>>f(x)
UnboundLocalError: local variable 'x' referenced before assignment
>>>f(y)
UnboundLocalError: local variable 'x' referenced before assignment
>>> x
5
>>> y
[5, 4, 3]在 Python 2.x 中,
Exception()实例被赋值给了变量e, 所以当你尝试打印结果的时候, 它的输出为空.(译: 正常的Exception实例打印出来就是空)Output (Python 2.x):
1
2
3
4>>> e
Exception()
>>> print e
# 没有打印任何内容!
> When True is actually False/真亦假
1 | |
Output:1
I've lost faith in truth!
💡 说明:
- 最初, Python 并没有
bool型 (人们用0表示假值, 用非零值比如1作为真值). 后来他们添加了True,False, 和bool型, 但是, 为了向后兼容, 他们没法把True和False设置为常量, 只是设置成了内置变量. - Python 3 由于不再需要向后兼容, 终于可以修复这个问题了, 所以这个例子无法在 Python 3.x 中执行!
> From filled to None in one instruction…/从有到无…
1 | |
Output:1
2
3
4>>> print(some_list)
None
>>> print(some_dict)
None
💡 说明:
大多数修改序列/映射对象的方法, 比如 list.append, dict.update, list.sort 等等. 都是原地修改对象并返回 None. 这样做的理由是, 如果操作可以原地完成, 就可以避免创建对象的副本来提高性能. (参考这里)
> Subclass relationships/子类关系 *
Output:1
2
3
4
5
6
7>>> from collections import Hashable
>>> issubclass(list, object)
True
>>> issubclass(object, Hashable)
True
>>> issubclass(list, Hashable)
False
子类关系应该是可传递的, 对吧? (即, 如果 A 是 B 的子类, B 是 C 的子类, 那么 A 应该 是 C 的子类.)
💡 说明:
- Python 中的子类关系并不一定是传递的. 任何人都可以在元类中随意定义
__subclasscheck__. - 当
issubclass(cls, Hashable)被调用时, 它只是在cls中寻找__hash__方法或者从继承的父类中寻找__hash__方法. - 由于
objectis 可散列的(hashable), 但是list是不可散列的, 所以它打破了这种传递关系. - 在这里可以找到更详细的解释.
> The mysterious key type conversion/神秘的键型转换 *
1 | |
Output:1
2
3
4
5
6
7
8>>> type(list(some_dict.keys())[0])
str
>>> s = SomeClass('s')
>>> some_dict[s] = 40
>>> some_dict # 预期: 两个不同的键值对
{'s': 40}
>>> type(list(some_dict.keys())[0])
str
💡 说明:
- 由于
SomeClass会从str自动继承__hash__方法, 所以s对象和"s"字符串的哈希值是相同的. - 而
SomeClass("s") == "s"为True是因为SomeClass也继承了str类__eq__方法. - 由于两者的哈希值相同且相等, 所以它们在字典中表示相同的键.
如果想要实现期望的功能, 我们可以重定义
SomeClass的__eq__方法.1
2
3
4
5
6
7
8
9
10
11
12
13class SomeClass(str):
def __eq__(self, other):
return (
type(self) is SomeClass
and type(other) is SomeClass
and super().__eq__(other)
)
# 当我们自定义 __eq__ 方法时, Python 不会再自动继承 __hash__ 方法
# 所以我们也需要定义它
__hash__ = str.__hash__
some_dict = {'s':42}Output:
1
2
3
4
5
6
7>>> s = SomeClass('s')
>>> some_dict[s] = 40
>>> some_dict
{'s': 40, 's': 42}
>>> keys = list(some_dict.keys())
>>> type(keys[0]), type(keys[1])
(__main__.SomeClass, str)
> Let’s see if you can guess this?/看看你能否猜到这一点?
1 | |
Output:1
2>>> a
{5: ({...}, 5)}
💡 说明:
根据 Python 语言参考, 赋值语句的形式如下
1
(target_list "=")+ (expression_list | yield_expression)赋值语句计算表达式列表(expression list)(牢记 这可以是单个表达式或以逗号分隔的列表, 后者返回元组)并将单个结果对象从左到右分配给目标列表中的每一项.
(target_list "=")+中的+意味着可以有一个或多个目标列表. 在这个例子中, 目标列表是a, b和a[b](注意表达式列表只能有一个, 在我们的例子中是{}, 5).表达式列表计算结束后, 将其值自动解包后从左到右分配给目标列表(target list). 因此, 在我们的例子中, 首先将
{}, 5元组并赋值给a, b, 然后我们就可以得到a = {}且b = 5.a被赋值的{}是可变对象.第二个目标列表是
a[b](你可能觉得这里会报错, 因为在之前的语句中a和b都还没有被定义. 但是别忘了, 我们刚刚将a赋值{}且将b赋值为5).现在, 我们将通过将字典中键
5的值设置为元组({}, 5)来创建循环引用 (输出中的{...}指与a引用了相同的对象). 下面是一个更简单的循环引用的例子1
2
3
4
5
6
7
8
9>>> some_list = some_list[0] = [0]
>>> some_list
[[...]]
>>> some_list[0]
[[...]]
>>> some_list is some_list[0]
True
>>> some_list[0][0][0][0][0][0] == some_list
True我们的例子就是这种情况 (
a[b][0]与a是相同的对象)总结一下, 你也可以把例子拆成
1
2a, b = {}, 5
a[b] = a, b并且可以通过
a[b][0]与a是相同的对象来证明是循环引用1
2>>> a[b][0] is a
True
Section: Appearances are deceptive!/外表是靠不住的!
> Skipping lines?/跳过一行?
Output:1
2
3
4>>> value = 11
>>> valuе = 32
>>> value
11
什么鬼?
注意: 如果你想要重现的话最简单的方法是直接复制上面的代码片段到你的文件或命令行里.
💡 说明:
一些非西方字符虽然看起来和英语字母相同, 但会被解释器识别为不同的字母.
1 | |
内置的 ord() 函数可以返回一个字符的 Unicode 代码点, 这里西里尔语 ‘e’ 和拉丁语 ‘e’ 的代码点不同证实了上述例子.
> Teleportation/空间移动 *
1 | |
Output:1
2
3>>> energy_send(123.456)
>>> energy_receive()
123.456
谁来给我发个诺贝尔奖?
💡 说明:
- 注意在
energy_send函数中创建的 numpy 数组并没有返回, 因此内存空间被释放并可以被重新分配. numpy.empty()直接返回下一段空闲内存,而不重新初始化. 而这个内存点恰好就是刚刚释放的那个(通常情况下, 并不绝对).
> Well, something is fishy…/嗯,有些可疑…
1 | |
Output (Python 2.x):
1 | |
难道不应该是100吗?
注意: 如果你无法重现, 可以尝试运行这个文件mixed_tabs_and_spaces.py.
💡 说明:
- 不要混用制表符(tab)和空格(space)! 在上面的例子中, return 的前面是”1个制表符”, 而其他部分的代码前面是 “4个空格”.
Python是这么处理制表符的:
首先, 制表符会从左到右依次被替换成8个空格, 直到被替换后的字符总数是八的倍数 <…>
- 因此,
square函数最后一行的制表符会被替换成8个空格, 导致return语句进入循环语句里面. Python 3 很友好, 在这种情况下会自动抛出错误.
Output (Python 3.x):
1
TabError: inconsistent use of tabs and spaces in indentation
Section: Watch out for the landmines!/小心地雷!
> Modifying a dictionary while iterating over it/迭代字典时的修改
1 | |
Output (Python 2.7- Python 3.5):
1 | |
是的, 它运行了八次然后才停下来.
💡 说明:
- Python不支持对字典进行迭代的同时修改它.
- 它之所以运行8次, 是因为字典会自动扩容以容纳更多键值(我们有8次删除记录, 因此需要扩容). 这实际上是一个实现细节. (译: 应该是因为字典的初始最小值是8, 扩容会导致散列表地址发生变化而中断循环.)
- 在不同的Python实现中删除键的处理方式以及调整大小的时间可能会有所不同.(译: 就是说什么时候扩容在不同版本中可能是不同的, 在3.6及3.7的版本中到5就会自动扩容了. 以后也有可能再次发生变化. 这是为了避免散列冲突. 顺带一提, 后面两次扩容会扩展为32和256. 即
8->32->256.) - 更多的信息, 你可以参考这个StackOverflow的回答, 它详细的解释一个类似的例子.
> Stubborn del operator/坚强的 del *
1 | |
Output:
1.1
2
3
4
5>>> x = SomeClass()
>>> y = x
>>> del x # 这里应该会输出 "Deleted!"
>>> del y
Deleted!
唷, 终于删除了. 你可能已经猜到了在我们第一次尝试删除 x 时是什么让 __del__ 免于被调用的. 那让我们给这个例子增加点难度.
2.1
2
3
4
5
6
7
8
9>>> x = SomeClass()
>>> y = x
>>> del x
>>> y # 检查一下y是否存在
<__main__.SomeClass instance at 0x7f98a1a67fc8>
>>> del y # 像之前一样, 这里应该会输出 "Deleted!"
>>> globals() # 好吧, 并没有. 让我们看一下所有的全局变量
Deleted!
{'__builtins__': <module '__builtin__' (built-in)>, 'SomeClass': <class __main__.SomeClass at 0x7f98a1a5f668>, '__package__': None, '__name__': '__main__', '__doc__': None}
好了,现在它被删除了 :confused:
💡 说明:
del x并不会立刻调用x.__del__().- 每当遇到
del x, Python 会将x的引用数减1, 当x的引用数减到0时就会调用x.__del__(). - 在第二个例子中,
y.__del__()之所以未被调用, 是因为前一条语句 (>>> y) 对同一对象创建了另一个引用, 从而防止在执行del y后对象的引用数变为0. - 调用
globals导致引用被销毁, 因此我们可以看到 “Deleted!” 终于被输出了. - (译: 这其实是 Python 交互解释器的特性, 它会自动让
_保存上一个表达式输出的值, 详细可以看这里.)
> Deleting a list item while iterating/迭代列表时删除元素
1 | |
Output:1
2
3
4
5
6
7
8>>> list_1
[1, 2, 3, 4]
>>> list_2
[2, 4]
>>> list_3
[]
>>> list_4
[2, 4]
你能猜到为什么输出是 [2, 4] 吗?
💡 说明:
在迭代时修改对象是一个很愚蠢的主意. 正确的做法是迭代对象的副本,
list_3[:]就是这么做的.1
2
3
4
5>>> some_list = [1, 2, 3, 4]
>>> id(some_list)
139798789457608
>>> id(some_list[:]) # 注意python为切片列表创建了新对象.
139798779601192
del, remove 和 pop 的不同:
del var_name只是从本地或全局命名空间中删除了var_name(这就是为什么list_1没有受到影响).remove会删除第一个匹配到的指定值, 而不是特定的索引, 如果找不到值则抛出ValueError异常.pop则会删除指定索引处的元素并返回它, 如果指定了无效的索引则抛出IndexError异常.
为什么输出是 [2, 4]?
- 列表迭代是按索引进行的, 所以当我们从
list_2或list_4中删除1时, 列表的内容就变成了[2, 3, 4]. 剩余元素会依次位移, 也就是说,2的索引会变为 0,3会变为 1. 由于下一次迭代将获取索引为 1 的元素 (即3), 因此2将被彻底的跳过. 类似的情况会交替发生在列表中的每个元素上.
> Loop variables leaking out!/循环变量泄漏!
1.1
2
3
4for x in range(7):
if x == 6:
print(x, ': for x inside loop')
print(x, ': x in global')
Output:1
26 : for x inside loop
6 : x in global
但是 x 从未在循环外被定义…
2.1
2
3
4
5
6# 这次我们先初始化x
x = -1
for x in range(7):
if x == 6:
print(x, ': for x inside loop')
print(x, ': x in global')
Output:1
26 : for x inside loop
6 : x in global
3.1
2
3x = 1
print([x for x in range(5)])
print(x, ': x in global')
Output (on Python 2.x):1
2[0, 1, 2, 3, 4]
(4, ': x in global')
Output (on Python 3.x):1
2[0, 1, 2, 3, 4]
1 : x in global
💡 说明:
在 Python 中, for 循环使用所在作用域并在结束后保留定义的循环变量. 如果我们曾在全局命名空间中定义过循环变量. 在这种情况下, 它会重新绑定现有变量.
Python 2.x 和 Python 3.x 解释器在列表推导式示例中的输出差异, 在文档 What’s New In Python 3.0 中可以找到相关的解释:
“列表推导不再支持句法形式
[... for var in item1, item2, ...]. 取而代之的是[... for var in (item1, item2, ...)]. 另外, 注意列表推导具有不同的语义: 它们更接近于list()构造函数中生成器表达式的语法糖(译: 这一句我也不是很明白), 特别是循环控制变量不再泄漏到周围的作用域中.”
> Beware of default mutable arguments!/当心默认的可变参数!
1 | |
Output:1
2
3
4
5
6
7
8>>> some_func()
['some_string']
>>> some_func()
['some_string', 'some_string']
>>> some_func([])
['some_string']
>>> some_func()
['some_string', 'some_string', 'some_string']
💡 说明:
Python中函数的默认可变参数并不是每次调用该函数时都会被初始化. 相反, 它们会使用最近分配的值作为默认值. 当我们明确的将
[]作为参数传递给some_func的时候, 就不会使用default_arg的默认值, 所以函数会返回我们所期望的结果.1
2
3def some_func(default_arg=[]):
default_arg.append("some_string")
return default_argOutput:
1
2
3
4
5
6
7
8
9
10
11>>> some_func.__defaults__ # 这里会显示函数的默认参数的值
([],)
>>> some_func()
>>> some_func.__defaults__
(['some_string'],)
>>> some_func()
>>> some_func.__defaults__
(['some_string', 'some_string'],)
>>> some_func([])
>>> some_func.__defaults__
(['some_string', 'some_string'],)避免可变参数导致的错误的常见做法是将
None指定为参数的默认值, 然后检查是否有值传给对应的参数. 例:1
2
3
4
5def some_func(default_arg=None):
if not default_arg:
default_arg = []
default_arg.append("some_string")
return default_arg
> Catching the Exceptions/捕获异常
1 | |
Output (Python 2.x):1
2
3Caught!
ValueError: list.remove(x): x not in list
Output (Python 3.x):1
2
3
4 File "<input>", line 3
except IndexError, ValueError:
^
SyntaxError: invalid syntax
💡 说明:
如果你想要同时捕获多个不同类型的异常时, 你需要将它们用括号包成一个元组作为第一个参数传递. 第二个参数是可选名称, 如果你提供, 它将与被捕获的异常实例绑定. 例,
1
2
3
4
5
6
7some_list = [1, 2, 3]
try:
# 这里会抛出异常 ``ValueError``
some_list.remove(4)
except (IndexError, ValueError), e:
print("Caught again!")
print(e)Output (Python 2.x):
1
2Caught again!
list.remove(x): x not in listOutput (Python 3.x):
1
2
3
4File "<input>", line 4
except (IndexError, ValueError), e:
^
IndentationError: unindent does not match any outer indentation level在 Python 3 中, 用逗号区分异常与可选名称是无效的; 正确的做法是使用
as关键字. 例,1
2
3
4
5
6
7some_list = [1, 2, 3]
try:
some_list.remove(4)
except (IndexError, ValueError) as e:
print("Caught again!")
print(e)Output:
1
2Caught again!
list.remove(x): x not in list
> Same operands, different story!/同人不同命!
1.1
2
3a = [1, 2, 3, 4]
b = a
a = a + [5, 6, 7, 8]
Output:1
2
3
4>>> a
[1, 2, 3, 4, 5, 6, 7, 8]
>>> b
[1, 2, 3, 4]
2.1
2
3a = [1, 2, 3, 4]
b = a
a += [5, 6, 7, 8]
Output:1
2
3
4>>> a
[1, 2, 3, 4, 5, 6, 7, 8]
>>> b
[1, 2, 3, 4, 5, 6, 7, 8]
💡 说明:
a += b并不总是与a = a + b表现相同. 类实现op=运算符的方式 也许 是不同的, 列表就是这样做的.表达式
a = a + [5,6,7,8]会生成一个新列表, 并让a引用这个新列表, 同时保持b不变.表达式
a += [5,6,7,8]实际上是使用的是 “extend” 函数, 所以a和b仍然指向已被修改的同一列表.
> The out of scope variable/外部作用域变量
1 | |
Output:1
2
3
4>>> some_func()
1
>>> another_func()
UnboundLocalError: local variable 'a' referenced before assignment
💡 说明:
- 当你在作用域中对变量进行赋值时, 变量会变成该作用域内的局部变量. 因此
a会变成another_func函数作用域中的局部变量, 但它在函数作用域中并没有被初始化, 所以会引发错误. - 可以阅读这个简短却很棒的指南, 了解更多关于 Python 中命名空间和作用域的工作原理.
想要在
another_func中修改外部作用域变量a的话, 可以使用global关键字.1
2
3
4def another_func()
global a
a += 1
return aOutput:
1
2>>> another_func()
2
> Be careful with chained operations/小心链式操作
1 | |
💡 说明:
根据 https://docs.python.org/2/reference/expressions.html#not-in
形式上, 如果 a, b, c, …, y, z 是表达式, 而 op1, op2, …, opN 是比较运算符, 那么除了每个表达式最多只出现一次以外 a op1 b op2 c … y opN z 就等于 a op1 b and b op2 c and … y opN z.
虽然上面的例子似乎很愚蠢, 但是像 a == b == c 或 0 <= x <= 100 就很棒了.
False is False is False相当于(False is False) and (False is False)True is False == False相当于True is False and False == False, 由于语句的第一部分 (True is False) 等于False, 因此整个表达式的结果为False.1 > 0 < 1相当于1 > 0 and 0 < 1, 所以最终结果为True.- 表达式
(1 > 0) < 1相当于True < 1且所以,1
2
3
4>>> int(True)
1
>>> True + 1 # 与这个例子无关,只是好玩
21 < 1等于False
> Name resolution ignoring class scope/忽略类作用域的名称解析
1.1
2
3
4x = 5
class SomeClass:
x = 17
y = (x for i in range(10))
Output:1
2>>> list(SomeClass.y)[0]
5
2.1
2
3
4x = 5
class SomeClass:
x = 17
y = [x for i in range(10)]
Output (Python 2.x):1
2>>> SomeClass.y[0]
17
Output (Python 3.x):1
2>>> SomeClass.y[0]
5
💡 说明:
- 类定义中嵌套的作用域会忽略类内的名称绑定.
- 生成器表达式有它自己的作用域.
- 从 Python 3.X 开始, 列表推导式也有自己的作用域.
> Needle in a Haystack/大海捞针
1.1
x, y = (0, 1) if True else None, None
Output:1
2>>> x, y # 期望的结果是 (0, 1)
((0, 1), None)
几乎每个 Python 程序员都遇到过类似的情况.
2.1
2
3
4
5
6
7
8
9
10t = ('one', 'two')
for i in t:
print(i)
t = ('one')
for i in t:
print(i)
t = ()
print(t)
Output:1
2
3
4
5
6one
two
o
n
e
tuple()
💡 说明:
- 对于 1, 正确的语句是
x, y = (0, 1) if True else (None, None). - 对于 2, 正确的语句是
t = ('one',)或者t = 'one',(缺少逗号) 否则解释器会认为t是一个字符串, 并逐个字符对其进行迭代. ()是一个特殊的标记,表示空元组.
Section: The Hidden treasures!/隐藏的宝藏!
This section contains few of the lesser-known interesting things about Python that most beginners like me are unaware of (well, not anymore).
> Okay Python, Can you make me fly?/Python, 可否带我飞? *
好, 去吧.
1 | |
Output:
嘘.. 这是个超级秘密.
💡 说明:
antigravity模块是 Python 开发人员发布的少数复活节彩蛋之一.import antigravity会打开一个 Python 的经典 XKCD 漫画页面.- 不止如此. 这个复活节彩蛋里还有一个复活节彩蛋. 如果你看一下代码, 就会发现还有一个函数实现了 XKCD’s geohashing 算法.
> goto, but why?/goto, 但为什么? *
1 | |
Output (Python 2.3):1
2
3I'm trapped, please rescue!
I'm trapped, please rescue!
Freedom!
💡 说明:
- 2004年4月1日, Python 宣布 加入一个可用的
goto作为愚人节礼物. - 当前版本的 Python 并没有这个模块.
- 就算可以用, 也请不要使用它. 这里是为什么Python中没有
goto的原因.
> Brace yourself!/做好思想准备 *
如果你不喜欢在Python中使用空格来表示作用域, 你可以导入 C 风格的 {},
1 | |
Output:1
2
3 File "some_file.py", line 1
from __future__ import braces
SyntaxError: not a chance
想用大括号? 没门! 觉得不爽, 请去用java.
💡 说明:
- 通常
__future__会提供 Python 未来版本的功能. 然而,这里的 “未来” 是一个讽刺. - 这是一个表达社区对此类问题态度的复活节彩蛋.
> Let’s meet Friendly Language Uncle For Life/让生活更友好 *
Output (Python 3.x)1
2
3
4
5
6
7
8
9>>> from __future__ import barry_as_FLUFL
>>> "Ruby" != "Python" # 这里没什么疑问
File "some_file.py", line 1
"Ruby" != "Python"
^
SyntaxError: invalid syntax
>>> "Ruby" <> "Python"
True
这就对了.
💡 说明:
- 相关的 PEP-401 发布于 2009年4月1日 (所以你现在知道这意味着什么了吧).
引用 PEP-401
意识到 Python 3.0 里的 != 运算符是一个会引起手指疼痛的恐怖错误, FLUFL 将 <> 运算符恢复为唯一写法.
- Uncle Barry 在 PEP 中还分享了其他东西; 你可以在这里获得他们.
- (译: 虽然文档中没写,但应该是只能在交互解释器中使用.)
> Even Python understands that love is complicated/连Python也知道爱是难言的 *
1 | |
等等, this 是什么? this 是爱 :heart:
Output:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40The Zen of Python, by Tim Peters
Beautiful is better than ugly.
优美胜于丑陋(Python 以编写优美的代码为目标)
Explicit is better than implicit.
明了胜于晦涩(优美的代码应当是明了的,命名规范,风格相似)
Simple is better than complex.
简洁胜于复杂(优美的代码应当是简洁的,不要有复杂的内部实现)
Complex is better than complicated.
复杂胜于凌乱(如果复杂不可避免,那代码间也不能有难懂的关系,要保持接口简洁)
Flat is better than nested.
扁平胜于嵌套(优美的代码应当是扁平的,不能有太多的嵌套)
Sparse is better than dense.
间隔胜于紧凑(优美的代码有适当的间隔,不要奢望一行代码解决问题)
Readability counts.
可读性很重要(优美的代码一定是可读的)
Special cases aren't special enough to break the rules.
没有特例特殊到需要违背这些规则(这些规则至高无上)
Although practicality beats purity.
尽管我们更倾向于实用性
Errors should never pass silently.
不要安静的包容所有错误
Unless explicitly silenced.
除非你确定需要这样做(精准地捕获异常,不写 except:pass 风格的代码)
In the face of ambiguity, refuse the temptation to guess.
拒绝诱惑你去猜测的暧昧事物
There should be one-- and preferably only one --obvious way to do it.
而是尽量找一种,最好是唯一一种明显的解决方案(如果不确定,就用穷举法)
Although that way may not be obvious at first unless you're Dutch.
虽然这并不容易,因为你不是 Python 之父(这里的 Dutch 是指 Guido )
Now is better than never.
现在行动好过永远不行动
Although never is often better than *right* now.
尽管不行动要好过鲁莽行动
If the implementation is hard to explain, it's a bad idea.
如果你无法向人描述你的方案,那肯定不是一个好方案;
If the implementation is easy to explain, it may be a good idea.
如果你能轻松向人描述你的方案,那也许会是一个好方案(方案测评标准)
Namespaces are one honking great idea -- let's do more of those!
命名空间是一种绝妙的理念,我们应当多加利用(倡导与号召)
这是 Python 之禅!
1 | |
💡 说明:
this模块是关于 Python 之禅的复活节彩蛋 (PEP 20).- 如果你认为这已经够有趣的了, 可以看看 this.py 的实现. 有趣的是, Python 之禅的实现代码违反了他自己 (这可能是唯一会发生这种情况的地方).
*
至于love is not True or False; love is love, 意外却又不言而喻.
> Yes, it exists!/是的, 它存在!
循环的 else. 一个典型的例子:
1 | |
Output:1
2
3
4
5>>> some_list = [1, 2, 3, 4, 5]
>>> does_exists_num(some_list, 4)
Exists!
>>> does_exists_num(some_list, -1)
Does not exist
异常的 else . 例,
1 | |
Output:1
Try block executed successfully...
💡 说明:
- 循环后的
else子句只会在循环没有触发break语句, 正常结束的情况下才会执行. - try 之后的
else子句也被称为 “完成子句”, 因为在try语句中到达else子句意味着try块实际上已成功完成.
> Inpinity/无限 *
英文拼写是有意的, 请不要为此提交补丁.
(译: 这里是为了突出 Python 中无限的定义与Pi有关, 所以将两个单词拼接了.)
Output (Python 3.x):1
2
3
4
5>>> infinity = float('infinity')
>>> hash(infinity)
314159
>>> hash(float('-inf'))
-314159
💡 说明:
- infinity 的哈希值是 10⁵ x π.
- 有意思的是,
float('-inf')的哈希值在 Python 3 中是 “-10⁵ x π” , 而在 Python 2 中是 “-10⁵ x e”.
> Mangling time!/修饰时间! *
1 | |
Output:1
2
3
4
5
6>>> Yo().bitch
True
>>> Yo().__honey
AttributeError: 'Yo' object has no attribute '__honey'
>>> Yo()._Yo__honey
True
为什么 Yo()._Yo__honey 能运行? 只有印度人理解.(译: 这个梗可能是指印度音乐人Yo Yo Honey Singh)
💡 说明:
- 名字修饰 用于避免不同命名空间之间名称冲突.
- 在 Python 中, 解释器会通过给类中以
__(双下划线)开头且结尾最多只有一个下划线的类成员名称加上_NameOfTheClass来修饰(mangles)名称. - 所以, 要访问
__honey对象,我们需要加上_Yo以防止与其他类中定义的相同名称的属性发生冲突.
Section: Miscellaneous/杂项
> += is faster/更快的 +=
1 | |
💡 说明:
- 连接两个以上的字符串时
+=比+更快, 因为在计算过程中第一个字符串 (例如,s1 += s2 + s3中的s1) 不会被销毁.(译: 就是+=执行的是追加操作,少了一个销毁新建的动作.)
> Let’s make a giant string!/来做个巨大的字符串吧!
1 | |
Output:1
2
3
4
5
6
7
8
9
10
11>>> timeit(add_string_with_plus(10000))
1000 loops, best of 3: 972 µs per loop
>>> timeit(add_bytes_with_plus(10000))
1000 loops, best of 3: 815 µs per loop
>>> timeit(add_string_with_format(10000))
1000 loops, best of 3: 508 µs per loop
>>> timeit(add_string_with_join(10000))
1000 loops, best of 3: 878 µs per loop
>>> l = ["xyz"]*10000
>>> timeit(convert_list_to_string(l, 10000))
10000 loops, best of 3: 80 µs per loop
让我们将迭代次数增加10倍.
1 | |
💡 说明:
- 你可以在这获得更多 timeit 的相关信息. 它通常用于衡量代码片段的执行时间.
- 不要用
+去生成过长的字符串, 在 Python 中,str是不可变的, 所以在每次连接中你都要把左右两个字符串复制到新的字符串中. 如果你连接四个长度为10的字符串, 你需要拷贝 (10+10) + ((10+10)+10) + (((10+10)+10)+10) = 90 个字符而不是 40 个字符. 随着字符串的数量和大小的增加, 情况会变得越发的糟糕 (就像add_bytes_with_plus函数的执行时间一样) - 因此, 更建议使用
.format.或%语法 (但是, 对于短字符串, 它们比+稍慢一点). - 又或者, 如果你所需的内容已经以可迭代对象的形式提供了, 使用
''.join(可迭代对象)要快多了. add_string_with_plus的执行时间没有像add_bytes_with_plus一样出现二次增加是因为解释器会如同上一个例子所讨论的一样优化+=. 用s = s + "x" + "y" + "z"替代s += "xyz"的话, 执行时间就会二次增加了.1
2
3
4
5
6
7
8
9
10def add_string_with_plus(iters):
s = ""
for i in range(iters):
s = s + "x" + "y" + "z"
assert len(s) == 3*iters
>>> timeit(add_string_with_plus(10000))
100 loops, best of 3: 9.87 ms per loop
>>> timeit(add_string_with_plus(100000)) # 执行时间二次增加
1 loops, best of 3: 1.09 s per loop
> Explicit typecast of strings/字符串的显式类型转换
1 | |
Output:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20>>> a
inf
>>> b
nan
>>> c
-inf
>>> float('some_other_string')
ValueError: could not convert string to float: some_other_string
>>> a == -c #inf==inf
True
>>> None == None # None==None
True
>>> b == d #但是 nan!=nan
False
>>> 50/a
0.0
>>> a/a
nan
>>> 23 + b
nan
💡 说明:
'inf' 和 'nan' 是特殊的字符串(不区分大小写), 当显示转换成 float 型时, 它们分别用于表示数学意义上的 “无穷大” 和 “非数字”.
> Minor Ones/小知识点
join()是一个字符串操作而不是列表操作. (第一次接触会觉得有点违反直觉)💡 说明:
如果join()是字符串方法 那么它就可以处理任何可迭代的对象(列表,元组,迭代器). 如果它是列表方法, 则必须在每种类型中单独实现. 另外, 在list对象的通用API中实现一个专用于字符串的方法没有太大的意义.看着奇怪但能正确运行的语句:
[] = ()语句在语义上是正确的 (解包一个空的tuple并赋值给list)'a'[0][0][0][0][0]在语义上也是正确的, 因为在 Python 中字符串同时也是序列(可迭代对象支持使用整数索引访问元素).3 --0-- 5 == 8和--5 == 5在语义上都是正确的, 且结果等于True.(译: 3减负0等于3,再减负5相当于加5等于8;负的负5等于5.)
鉴于
a是一个数字,++a和--a都是有效的 Python 语句, 但其效果与 C, C++ 或 Java 等不一样.1
2
3
4
5
6
7>>> a = 5
>>> a
5
>>> ++a
5
>>> --a
5💡 说明:
- python 里没有
++操作符. 这其实是两个+操作符. ++a被解析为+(+a)最后等于a.--a同理.- 这个 StackOverflow 回答 讨论了为什么 Python 中缺少增量和减量运算符.
- python 里没有
Python 使用 2个字节存储函数中的本地变量. 理论上, 这意味着函数中只能定义65536个变量. 但是,Python 内置了一个方便的解决方案,可用于存储超过2^16个变量名. 下面的代码演示了当定义了超过65536个局部变量时堆栈中发生的情况 (警告: 这段代码会打印大约2^18行文本, 请做好准备!):
1
2
3
4
5
6
7
8
9import dis
exec("""
def f():
""" + """
""".join(["X"+str(x)+"=" + str(x) for x in range(65539)]))
f()
print(dis.dis(f))你的 Python 代码 并不会多线程同时运行 (是的, 你没听错!). 虽然你觉得会产生多个线程并让它们同时执行你的代码, 但是, 由于 全局解释锁的存在, 你所做的只是让你的线程依次在同一个核心上执行. Python 多线程适用于IO密集型的任务, 但如果想要并行处理CPU密集型的任务, 你应该会想使用 multiprocessing 模块.
列表切片超出索引边界而不引发任何错误
1
2
3>>> some_list = [1, 2, 3, 4, 5]
>>> some_list[111:]
[]int('١٢٣٤٥٦٧٨٩')在 Python 3 中会返回123456789. 在 Python 中, 十进制字符包括数字字符, 以及可用于形成十进制数字的所有字符, 例如: U+0660, ARABIC-INDIC DIGIT ZERO. 这有一个关于此的 有趣故事.'abc'.count('') == 4. 这有一个count方法的相近实现, 能更好的说明问题1
2
3
4
5def count(s, sub):
result = 0
for i in range(len(s) + 1 - len(sub)):
result += (s[i:i + len(sub)] == sub)
return result这个行为是由于空子串(
'')与原始字符串中长度为0的切片相匹配导致的.
Contributing/贡献
欢迎各种补丁! 详情请看CONTRIBUTING.md.(译: 这是给原库提贡献的要求模版)
你可以通过新建 issue 或者在上 Gitter 与我们进行讨论.
(译: 如果你想对这个翻译项目提供帮助, 请看这里)
Acknowledgements/致谢
这个系列最初的想法和设计灵感来自于 Denys Dovhan 的项目 wtfjs. 社区的强大支持让它成长为现在的模样.
Some nice Links!/一些不错的资源
- https://www.youtube.com/watch?v=sH4XF6pKKmk
- https://www.reddit.com/r/Python/comments/3cu6ej/what_are_some_wtf_things_about_python
- https://sopython.com/wiki/Common_Gotchas_In_Python
- https://stackoverflow.com/questions/530530/python-2-x-gotchas-and-landmines
- https://stackoverflow.com/questions/1011431/common-pitfalls-in-python
- https://www.python.org/doc/humor/
- https://www.codementor.io/satwikkansal/python-practices-for-efficient-code-performance-memory-and-usability-aze6oiq65
🎓 License/许可
![]()
Help/帮助
如果您有任何想法或建议,欢迎分享.
Surprise your geeky pythonist friends?/想给你的极客朋友一个惊喜?
您可以使用这些快链向 Twitter 和 Linkedin 上的朋友推荐 wtfpython,
Need a pdf version?/需要来一份pdf版的?
我收到一些想要pdf版本的需求. 你可以快速在这获得.
Follow Commit/追踪Commit
这是中文版 fork 时所处的原库 Commit, 当原库更新时我会跟随更新.
![]()
996.icu
![]()
(转)What the Fuck Python! 一些python特性



