
Grep、Sed、Awk 02 Sed
Linux 三剑客之 Sed,相比于擅长数据查找定位的 Grep,Sed(Stream Editor)擅长做的是数据修改,做的主要是做一些增删改的功能。 sed 和 awk 的区别是什么?
Intro
首先介绍 Sed 命令,Stream Editor 流编辑器,针对字符流来进行文件编辑,同样,其核心也在于正则匹配式,其用法如下:
1 | |
其中{script}可以理解为三者的组合:sed 动作指令+Reg 用正则&行号确定修改位置+修改的内容:Script 是 Sed 的核心,分别对应着:操作的行为,操作的位置和操作的内容。
Sed 的用法也可以按照这个来记:
1 | |
h 显示 helo ;-n 表示静默输出,-V 显示版本;参考第一种用法,-e 可以指定多个 script 对输入的文件进行处理,-f 则可以将多个 script 写在文件中,通过读取文件中的 scripts 来对文本文件进行处理。
作为文本流编辑器,Sed 是一行一行的处理文件内容,将正在处理的每一行内容放在缓冲区中按照约定进行修改,处理后按照约定修改文件或输出,接着在处理下一行,直到整个文件处理内容。
其主要用来编辑和处理一个或者多个文件,简化对于文件的重复操作。
参考资料:sed 和 awk 的区别-知乎 | Man | sed 简明教程 | CoolShell | Linux sed 命令 | 菜鸟教程 | Linux文本三剑客超详细教程—-grep、sed、awk
Options 常用选项
- -e 多点编辑,对每行处理时使用多个 Script
- -f 将 scrips 写到文件里,如果是多个 script 之间换行
- -r/E 支持拓展的正则表达式
- -i 直接将修改写入文件(如果不加入 i 的话不会修改文件,只会讲修改过后的内容进行输出,后续也可以使用重定向输入到文件中)
- -i.bak 直接将修改写入文件,但是会将原本的文件备份到*.bak
- -n 静默输出。
Scripts 编辑命令编写
上述提到,Sed 的核心在于 Script,其编写主要由三个部分组成,Command(行为) + Located(定界,确定修改的位置)+ Content(修改内容,增或者改的时候需要,删无需)这里主要介绍以下常用的动作指令和定界方式。
Command 动作指令
具体的所有动作指令还是要参考 Man 文档,这里只介绍一些常用的 command,
| Command | Type | Desc |
|---|---|---|
| a | 增 | Append 后接字符,在指定行的下一行添加指定的新的字符,支持 \n |
| i | 增 | Insert 后接字符,在指定行的上一行添加指定的新的字符,支持 \n |
| d | 删 | 删除通常不接任何字符,删除当前行 |
| c | 改 | change 可接字符串,可以取代 n1,n 2 之间的行,支持 \n |
| s /// | 改 | 查找与替换,通常搭配正则表达式使用,将指定的词替换成新词 |
| p | 输出 | Print,将某个指定的数据输出,通常会配合-n 一起用 |
| = | 输出 | 为模式匹配空间的行打印行号 |
| w | 输出 | 保存模式匹配空间的行到指定文件 |
| ! | 功能 | 模式空间中匹配行取反处理 |
其中 s 替换命令,在诸多动作指令中算是一个非常常见的命令,其用法略为复杂一些,这里做基础介绍:
1 | |
这里的 before 和 after 都好理解,type 为 g 表示对匹配到的行内进行全局替换,为任意 num 的时候则是匹配每一行中第几个匹配到的值,num+g 的话就代表从 num 个起。
这里介绍一个替换的例子,假如我们希望删除 html 中的 tags
1 | |
若使用以下的指令,会将<b 和 span>中的内容全部删除,并非理想的效果。
1 | |
我们需要借助正则的方式来避免这种情况,如下除了>的字符重复 0 次或多次即可;
1 | |
Located 地址定界
sed 会使用到的”定界”方式实际上主要有两种:
- 匹配:使用正则表达式进行匹配
- 地址范围:指定行
但是其中匹配的方式,可以按照模式能够匹配到的每一行进行理解,这样的话就可以整理成以下的几种方式;
不给地址:对全文进行处理
指定地址:
n即指定的第 n 行/pattern/即被此处模式能匹配到的每一行
地址范围有以下的表示方式
n1,n2表示处理 n1 到 n2 的范围,n1,+n表示处理 n 1 到 $n 1+n$ 的范围/pat1/,/pat2/表示从 pattern1 到 pattern2 的范围,但是注意会匹配每一个这样的组,如果某个 patern1 没有被 pattern2 闭起来的话就会输出到末尾。n,/pat1表示从 n 行到 pattern1 的范围/pat1/,+n则表示从 pattern 1 即之后的 n 行- 类似这种方式可以对这几种行匹配方式进行自由组合
步进表达式,通常用以表示单双行
sed -n '1~2p'表示只打印奇数行,从第一行开始,搁两行输出sed -n '2~2p'表示只打印偶数行
需要注意,sed 定义的行号是从第 1行开始的,没有第 0 行;此外,进行测试的时候输入-n 能够防止输出未匹配到的行从而混淆视听,这里可以使用如下的命令,结合-n 和 p command 来做测试。
1 | |
Usage 用法展示
这里会零零散散的展示一些没那么常规或者值得一提的用法,具体的类型会通过 title 指出;还有一些什么单双行匹配的使用特定的定界符号 1~2 在地址的前面就行,
Type 1 在行末或行前添加
如果需要在每行末尾或行首添加指定内容(非换行的情况),则不能使用 a 或者 i 命令,需要使用 s 结合正则的方式实现:
例如给 ip 地址添加端口 :22,原文件如下
1 | |
则使用 ^ 代表行首,$ 代表行尾,使用如下的命令进行修改
1 | |
拓展:当源文件如下,我们只需要添加缺失的时候,同样可以使用正则表达式进行处理。
1 | |
使用正则定界并取反,排除存在:port 的行,对剩下的行进行替换
1 | |
参考资料:sed - Add text at the end of each line - Stack Overflow
Type 2 多 Script 匹配
还是上面的例子,如果我们希望同时在头部和尾部添加东西(或者类似的多个匹配操作),可以用以下方式来同时执行多个匹配模式。
1 | |
就可以同时执行头部和尾部的内容添加,同样也可以按照以下的方式写:
1 | |
还可以使用 -f 参数将多个 script 写在文件中
Type 3 多 Script 组合
当处理的是不同地方的多个脚本,可以使用多 script 匹配的方式进行,但是当我们针对一个匹配字符进行多个处理的时候,可以使用 {} 来组合 command ,每个命令之间用 ; 分割。
比如我们希望将 192 修改成 172 后输出:
1 | |
上面这个命令首先找到 192 匹配的行,然后针对改行执行替换后,执行输出指令;
Type 4 将匹配值作变量
可以用 & 代表被匹配到的变量,然后就可以基于该变量进行修改,比如我们识别到 192 开头的就在其前面加上 LAN_ADDR:
1 | |
当然这里也可以直接用 192 表示,但是如果我们的 192 只是一个用通配符匹配到的模式的时候就能发挥其作用。
可以用来做大小写转换
同样,根据该命令我们也可以进行特定字符的大小写转换,首先给出部分特殊参照符号如下,结合以下的参数就可以实现大小写转换。
| symbol | function |
|---|---|
\u |
将下一个字符转变成大写 |
\l |
将下一个字符转变为小写 |
\U |
将 replacement 的字符转变为大写,直到 \U 或 \E 出现 |
\L |
将 replacement 的字符转变为大写,直到 \L 或 \E 出现 |
\E |
停止大小写转换 |
1 | |
这样就可以将全文的英文字符做大小写转换了,可以以类似方式对指定的字符进行转换。
圆括号匹配也是一种将匹配值作为变量的方式
圆括号匹配: 使用圆括号括起来的正则表达式所匹配的字符串可以当成变量来使用,sed 中使用 \1 ; \2 …来引用对应的匹配值。
1 | |
其中 \1 代表 \([^.]*\) 匹配到的内容也就是 192,\2 则是代表 \([^1]*\) 匹配到的内容是 68.0,该行命令会将 192.168.0.1 转换成 1 92:68 .0
注意使用圆括号匹配的时候需要使用 \ 转义符,不然会当成普通的括号或者报错。
Type 5 管道处理
1 | |
Advanced 高级用法
该部分摘自参考资料:Linux文本三剑客超详细教程—-grep、sed、awk
Manual 格式手册
进阶命令格式(用的时候再来查表吧),通过 Hold Space 相当于可以引入一个中间变量来做一些单变量无法实现的处理,比如说将文章倒序输出;
- h:把模式空间中的内容覆盖至保持空间中
- H:把模式空间中的内容追加至保持空间中
- g:从保持空间取出数据覆盖至模式空间
- G:从保持空间取出内容追加至模式空间
- x:把模式空间中的内容与保持空间中的内容进行互换
- n:读取匹配到的行的下一行覆盖 至模式空间
- N:读取匹配到的行的下一行追加 至模式空间
- d:删除模式空间中的行
- D:删除 当前模式空间开端至\n 的内容(不再传 至标准输出),放弃之后的命令,但是对剩余模式空间重新执行sed
Reverse 倒序显示文件
1 | |
该命令能将文本倒序输出,具体的原理如下:
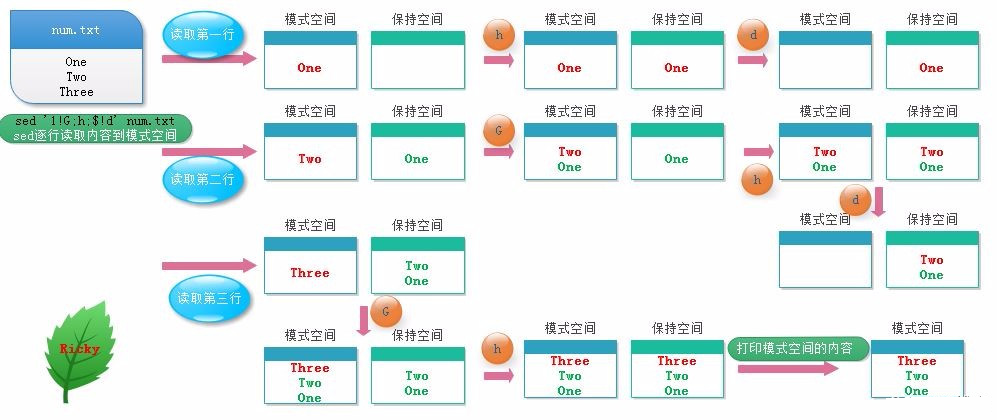
该 Hold Space 还能用于什么情况我们后续补充,文中的其他例子好像不需借助 Hold Space 就可以实现了。
Extra Info 其他设置
Delimiter 分隔符选择
实际上在 sed 中,除了使用 / 还可以使用 @ , | , ! , ` 四种分隔符,其中比较推荐的还是 |,其他的几个分隔符和原本的 / 在可读性上没有优势。/ 主要是涉及到转义符号的时候有些头皮发麻。
参考资料: sed 模式分隔符 - sed 基础教程
Special Symbol 特殊符号
添加制表符直接使用 \t 是无效的无法正确识别 Tab,原本说 sed 不支持 \n 和 \t 但是实际测试以下的方式是可以添加两种字符的。
1 | |
Mac 上的特殊处理
需要注意的是 Sed 命令在 Linux 和 Macos 上存在较大的不同,在 Linux 中的功能更全面一些,这是由于 MacOs 是基于 BSD 的存在一些不足,可以通过 homebrew 下载额外的 sed
- sed -i 在 mac 中需要指定用于备份的后缀,也可以用
""取消备份,否则会报错invalid command code - sed -i 在 mac 中输入需要添加的行的时候,需要需要换行
1 | |
Grep、Sed、Awk 02 Sed



