
文章的部分内容被密码保护:
@aiken 2021 Framework
Abstract#
Try To make structure universal,编写一个自己的通用的架构,框架化,满足通过不同的model文件和特殊配置文件就能实现不同的模型的一个架构。
只是一个初步的框架集成,还有很多没有完善的地方,目前测试了ResNet18 跑Cifar10,没有什么问题,如果有什么可以改进的地方,或者你实现了一些Feature,*欢迎进行交流*!(私下联系我最好啦!)
感谢帮助
还有一些可以参数化或者可视化的地方,由于时间关系目前还没有修改,有兴趣的可以自己先添加一下
暂时只集成了分类的模块,后续可能会随缘扩展
本框架主要希望实现的是:易读性,可拓展性,以及简洁;
希望将重要的,可变的参数都尽量的分离出来,通过配置文件和命令行参数去定义和运行我们的网络,在这种情况下实现一个较好的工作流程。
Final Project Design#
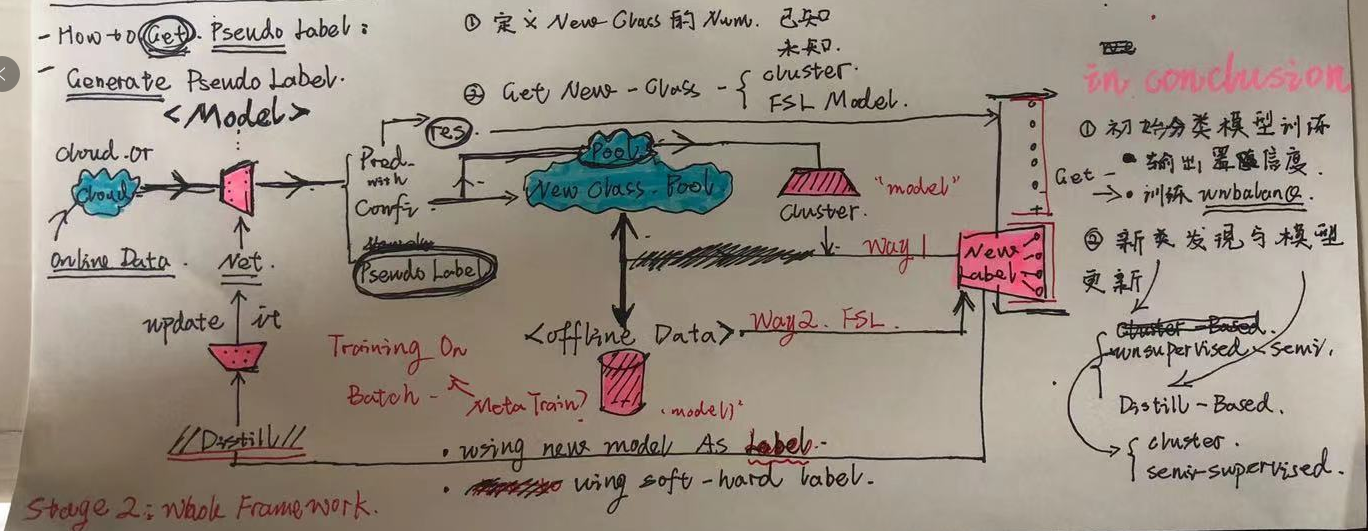
PURPOSE:新类发现和模型自主更新;同时希望能够解决长尾分布的数据情景;
**ANALYSIS:**为了实现这种模型的自主更新过程,将整体的流程分成两个部分
启动(start):
self supervissed 等方法无监督的学习特征提取网络(这种方式是否会对Unbalance产生增益)
初始化预测模型: 基于Unbalance的数据训练一个基础的分类模型,在输出分类结果的同时需要输出对应的预测置信度,这两个其实都是一些简单的Trick,而最重要的是Backbone的分类效果需要得到保证,同时Backbone需要支撑后续的模型蒸馏更新。

- 模型的自主更新和迭代: Online:在线运行推断模型,通过置信度输出筛选出新类样本,将样本在样本池中收集 Offline:基于样本池的规模和评估触发离线更新:伪标签生成模型;模型蒸馏和更新
创新点:自主新类发现和学习
Unbalance:
| Strategy | Status | Desc |
|---|---|---|
| Two Stage | Todo | 可以作为一个Baseline策略 |
| Causla Analysis | Doing | 基于TwoStage做出的偏差校正 |
| Rebalance | TBD | 作为数据增强的辅助策略 |
置信度生成方法:
置信度生成的方法可以从Active Learning等领域的文章中作为参考
| Strategy | Status | pros and cons |
|---|---|---|
| Evidential Learning | Doing | pros:有坚实的数学基础; cons:增加模型复杂度和训练的难度 |
| Least Confident | Done | pros:实现简单,不影响原有复杂度 cons:原理上简单,不是特别靠谱 |
| Entropy and… | TBD | 同上,可以随时取代测试 |
置信度准确率评估:
使用下面的指标去做置信度输出的准确率评估
伪标签生成模型:
在进行新的模型训练,之前,要将数据集混合现有的已知数据,生成的方式主要可以分成两种,网络或者聚类
- 聚类:通过现有类别的聚类结果,还能判断聚类的质量
- 网络:切分Mini-Batch进行Meta-Like的Training,训练FSL或者Unsupervised的模型,输出伪标签预测(一致性原则)
基本思想:
- 当特征以通用表征的无监督预训练进行,这种情况下不存在对应的数据瓶颈,因为我们不需要标记,我们可以将Backbone得到一个泛化性极强的高级特征,那么在这种情况下LT和FC带来的泛化性问题将集中在Classifier中,对Classifer进行校准和调整就是我们的主要方向,这样就能将问题归化到蒸馏和FC的训练一个Linear的问题
- 所以处理Unbalance的分类器和特征迁移方式是我们后续work的方向,可以从复杂度高的网络训练一个高级表征的分类器,或者通过Graph和Cluster的构建,来实现一个更为依赖Backbone的一种方式。
创新点:
- (Augmentation)在做伪标签生成之前,我们基于原本特征特征提取器,组合数据特征,数据混合和增强方法作为后续的数据基础
- (Loss-Design)通过混合的数据集中的伪标签生成,和标签的双指标,定义损失,去更新原有的特征提取架构同时赋予新类伪标签。这是由于我们知道部分数据集的真实标签,我们就可以通过这一部分的信息去做一个对应的标准。
- 这样就可以通过生成的伪标签对原特征提取器进行一定的更新,这种更新应该是交替进行的,因为我们不知道哪个Coder是更为可靠的一个label generator。(除非我们使用的是有终点的聚类)
模型更新:
参考蒸馏学习的思想,使用原有网络和pseudo generator作为Teacher 进行模型的更新,Duplicate Feature Extractor,Modify FC(num_class),考虑使用双重循环去freeze,利用不同的lr training网络的两部分。
在这里参考其他蒸馏学习的方法,去设计这种Teacher给予Label或者Parms的机制
考虑基于prototype的方法,是否会和聚类的方法更加的匹配,但是prototype
的方法和我们之前设想的实验过程应该是一个区分度比较大的情况
创新点:
- (Framework)double teacher to generate a new siamese model which train in two diff phase for feature extractor and classifier 使用孪生的机制,在两个不同的阶段来训练特征提取器和分类器,在这里我们将训练的重心转化到Projector以及Cluster,Model上
设计思路
在模型的整体架构上还是会和awb师弟的有很多类似的地方,后续可以详细进行探讨和借鉴。
DevLog#
开发中的一些疑问和细节会放在这个地方,包括开发的RoadMap,实现中遇到的问题,FrameWork设计中的主要矛盾和问题。
下面是一些基本的实验内容:首先将流程跑通,在设计对应的消融实验。
Full-Data 的模型基准实验#
| BackBone测试 | 数据集 | 进度 | 结果 |
|---|---|---|---|
| resnet-18 | cifar10 | 完成(配置文件已保存) | 93% |
| cifar100 | 完成(配置文件已保存) | 77% | |
| ImageNet | |||
| conclusion | 过拟合in cifar100 | ||
| Efficient Net b0 | cifar10 | 完成(非最佳)(配置文件已保存) | 90% |
| cifar100 | 完成(非最佳)(配置文件已保存) | 73% | |
| ImageNet | |||
| conclusion | 过拟合in cifar | ||
| Swin Transformer | |||
实际上在训练集和测试集中,resnet18 和 efficient net呈现的都是一种训练集远高于数据集的过拟合like的情况,我认为这种情况与问题规模简单,等诸多原因导致,为了改善这种情况,我们可以考虑
- 使用更多数据增强来使得问题更为复杂
- 使用特征学习无监督与训练的方法,同样通过数据增强来加大问题规模
- 增加数据,使用大规模数据集对模型进行与训练,但是也要考虑到数据的规模和模型的capability
Cifar10-100的模型调优过程#
后续可以考虑加入MAE的方式,实际上这种方式就是代替了EnAET中的多种复杂数据增强,还是从数据增强的角度入手对模型进行处理实现的一种自监督的机制,这种自监督的策略来学习一种图像上的通用表征,保持在识别问题上,整体的有效性。
ResNet#
在对cifar10-100的图像进行分类的时候需要修改初始的入口层,因为cifar数据集中的图像太小,如果一开始使用7*7的卷积层,在精度上会损失很多特征信息。
- 可以将7*7 2的卷积改成3*3 1,然后去掉maxpooling层
- 亦可以将图像resize到224*224
前者在cifar10中最终测试可得接近93%的准确率,在cifar100中最终测试可以取得稳定77%的准确率
此外,对图像进行randomcrop的过程中,由于原图本来就只有32*32所以我们希望crop到32的时候,我们最好是先进行padding,不然该增强是一个无效的增强。
Efficient Net#
和对ResNet进行调整的时候一样,训练集太过简单,所以过快的收敛,影响了模型的泛化能力,这里考虑可能是dropout没有设置好,或者是任务过于简单,我们可以对其设置一些图像的增强等等的操作来对对训练过程进行调整,可以将一部分需要较多io的任务存放在本地,然后在线进行一些random transformer。
在这里不需要对模型进行修改,只需要调整学习的参数即可。
Swin Transformer#
在new class - LT 的数据环境中的基准实验:#
首先测试LT和NC的数据策略是否能进行正常的数据训练,确保数据抽取策略
后续为了可复现和效果对比,我们在类别抽取的时候取消随机性(使用固定的随机种子),抽取固定的类别作为新类,对比未进行长尾采样以及采样之后的效果。
| model | 数据集以及预处理 | 进度 | LT结果 | NC结果 | Combine | TAG |
|---|---|---|---|---|---|---|
| … | cifar10, cifar100 分别测试LT和NC的策略 | Done | :heavy_check_mark: | :heavy_check_mark: | \ | varify |
| resnet | cifar100 NC:20 LT:0.5(step) | Done | \ | 75%-.5 | \ | try |
| pre-cifar100 NC20 LT0.5(STEP) | Done | 63% | 75%-.5 | 63%- 0.5 | basic | |
| 下面开始矫正 | 问题更大的实际上是LT部分 | |||||
| resnet-CA | ||||||
| resnet-ReBalance | ||||||
| resnet-MAR-iBOT | ||||||
| Efficient Net | ||||||
| Swin Transformer | ||||||
实验结果一:置信度问题#
使用Cifar100置信度划分的过程中,发现对新类的筛选效果并不好,我们考虑,这可能是由于超类和子类之间的关系造成的,为此,在初步的研究阶段,我们决定,拆分出特定的超类来作为新类,避免对于新类识别的干扰;
- 后续的研究中可以考虑像安文斌的方式去做纵向的新类发现,现阶段首先考虑横向的新类发现问题,在这里可以参考安文斌师弟的两个研究
实际上新类的拆分要求的是precision,相对的recall在当前的问题上并不是很重要,所以对该算法的改进不是很迫切,但是相应的,我们需要完善recall和Precision的输出用来作为我们后续进行判断的依据
拆分特定新类的情况下,置信度结果并没有明显的改进,说明问题更多的出自模型的特征提取和分类本身,用于分类的特征没有将类别之间的差异性体现出来,所以后续在这一方面的训练应该进行改进,改进思路如下:
修改Loss:使用Contrastive Learning的训练策略,在分类准确率之上结合NLL对比损失,在这一部分可以结合人脸比对的相应损失进行设计
实际上我们可以用MAE训练一个通用的预训练表征,Backbone,然后使用Contrastive训练Classifier,两种不同的策略的侧重点实际上是不一样的。那么如何结合这两种训练方式,或者将其中的一种训练和分类的训练相互结合起来,使得我们的训练步骤不会如此的冗余。
Contrastive Learn的预训练方式:得到一个类别之间更为分明的Backbone or MLP?
MAE的预训练方式,得到一个通用的表征?
实验结果二:LT问题#
准确率下降到63%(下降了10%左右),过拟合问题愈发严重,需要更多的去分析这种下降出现的原因。
Distill部分网络结构设计#
为了使得能够进行代码复用,不做重复的造轮子,在对蒸馏部分网络进行设计的时候遇到了一些问题,以下是问题和解决方式,假如这些方式不能很好的解决对应的问题,我们就duplicate代码并重新编写Train_ditill 的设计
这一部分其实设计的是整个框架中的数据流程,要注意在每个不同的阶段我们使用的数据是不同的。如何更有效的利用这个数据,是框架设计中的关键部分。
损失部分对输入的要求不同#
面临问题:
- 需要额外的模型输出作为Loss的计算依据
- 损失函数的输入维度不统一
暂定解决方案,
- (Both)使用额外的args参数对损失计算的部分进行分支处理
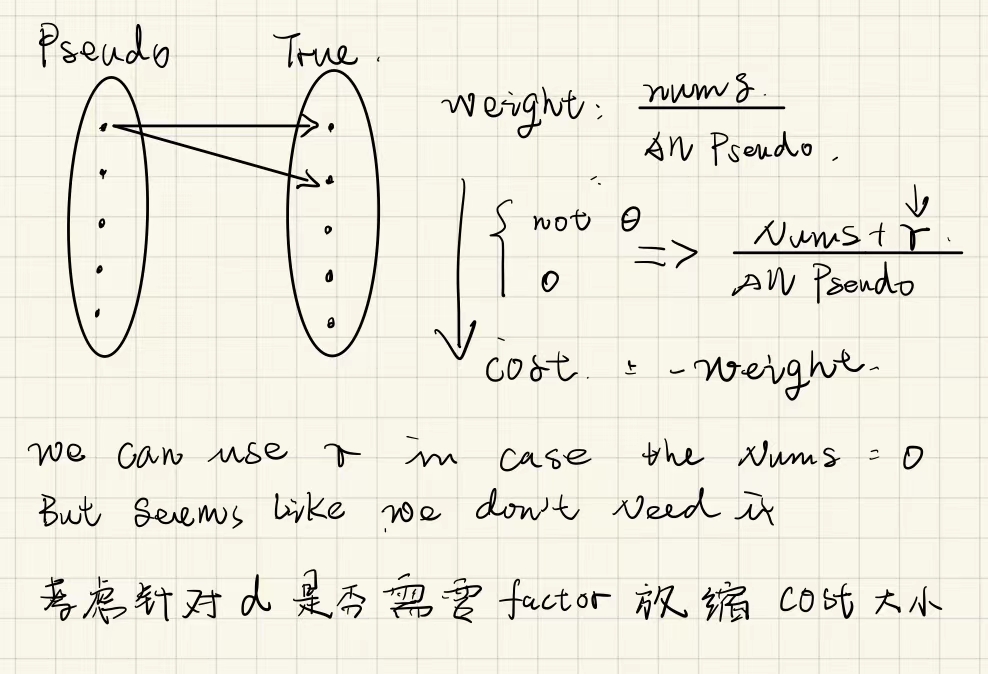
伪标签的处理#
具体问题:
- 在什么阶段将标签转化为对应的伪标签
- 如何和真实标签进行一个对照分析,如何保存并实现验证和真实环境的匹配度
暂定解决方案:
再labelGe中仿照人类标注,按照绝大多数类别的真是标签来确定伪标签,然后再初始化蒸馏训练中,将训练集中的数据替换为伪标签,而test数据集中仍然是真实标签,就解决了验证的问题和伪标签和真实标签之前缺乏一次映射的问题。
RoadMap#
开发路线图部分,主要分为基本的模块,和不同的训练方式两个阶段,用来集成完整的Framework.
Deadline Settting#
具体时间节点,主要是为了给自己明确当前的任务,后续可能会继续细化,时间上也会随着实验的顺利与否进行调整。
| Task | Desc | |
|---|---|---|
| 部分功能重写 | config,dataloader(read data and load in GPU) by define collate_fn function | 完成 |
| 数据处理 | 几个部分的数据还有整体的数据:New(FS divide into phase?)-Old(LT)-Cloud(无关数据) | 完成 |
| 调整运行Swin | 交织在多个任务中并行,时不时的调整参数测试一下 | 待定 |
| 长尾模块功能实现 | 在cifar数据集上用resnet先进行实验和swin的实验并行 实现对长尾的优化 | 进行 |
| 小样本模型和聚类模型嵌入 | 1. 确定数据混合策略 2. EnAet中训练的策略集成到该函数中 3 确定标签的输出和参与的形式 | 进行 |
| 蒸馏架构实现 | 架构编写,实现蒸馏框架的嵌入 测试双模型之间的蒸馏的结果 | 完成 |
| 模型实验和测试 |
Data#
数据集收集和初始数据的采样处理:
分析一下数据的使用场景:
首先我们使用Unbalance的数据进行初始模型的构建,然后我们需要在训练的过程中加入小样本的新类别。
可以额外的构建小样本的数据集来训练小样本模型,但这不在我们的Workflow里,不作为我们的主题框架中的代码。
| Function | Stage | Desc |
|---|---|---|
| New Class(Larget version) | done | like mini-imagenet,mv some cls to other dir |
| Unbalance | done | sampling data in differ rate |
| Mix data | done | mix old knowledge and the new data,the point: whether we want to use meta-learning or pnot |
| Few Shot | done | testing the model only have few data |
所以数据准备工作应该分为两步:
(Script)数据集预处理,将一部分类别抽离出去,建立新的文件夹,但是对于Cifar这种数据集好像都是一次性载入的,思考一下怎么写成对应的函数进行处理。
(Load)初始数据的Unbalance处理,通过不同的采样策略使得数据不均衡
此外,我们在进行新类训练的时候会将旧数据和新数据进行混合,我们需要设计对应的数据混合策略,进行小样本模型的训练和聚类的训练
Model#
| Functional Part | Stage | KeyWord/Method |
|---|---|---|
| Basic Training | abjust | ImageNet1k Using ImageNet to Pretrain or Self-Training |
| Backbone | todo | Swin(abjust params and train on ImageNet) |
| LT and Confidence | done | two-stage rebalance causal analysis |
| FSL | doing | Self-Supervise Cluster |
| Cluster | todo | New-Descover K-Means Self-Supervised + linear |
Framework#
| Training Process | Stage | KeyWord/Method |
|---|---|---|
| Meta Training | TBD | / |
| Multi-Stage Training | Intergrate with Framwork | / |
| Distill Training | done | Incremental learning, |
| Unsupervised | todo | MAE |
| Clustering | doing | Projector-Head + Kmeans |
Swin-T#
问题描述:在cifar10,或者ImageNet数据集上训练的时候,损失曲线过早收敛,识别准确率很低;
问题分析:
- LR 过高,没有办法学到好的解
框架中学习率设置的问题,同理可以分析其他的和config中的冲突
数据集标签的问题
模型定义的问题
损失函数设计,模型的体量问题
解决方法拟定:
- 直接使用官方的模型和官方的数据集进行训练后比对
- 加载并编写论文中提到的各种trick
- 对比官方的模型和自己编写的模型之间的差异
Dataset#
这一部分描写使用到的dataset的具体参数,主要至少包含一下的一些信息
| Name | Class | EachNum | Resolution | Useage |
|---|---|---|---|---|
| Cifar10 | 10 | 5000+1000 | 32*32 | Cls LT |
| Cifar100 | 100 | 500+100 | 32*32 | Cls NC LT |
| TinyImageNet | 200 | 500+50+50 | 64*64 | Cls NC LT |
| MiniImageNet | 100 | 500+100 | 86*86 | Cls NC LT |
| ImageNet-1k | 1000 | 700-1300 | resize to (256*256) avg:469*387 | PreTrain |
If Need List the dataset here :
Tiny-ImageNet-200 | Tiny-ImageNet-Plus
Reference#
Confidental
ResNet
Pytorch.org 、官方实现解读 、ResNet详解与分析 、Pytorch手工实现
Mini ImageNet
Swin Transformer