
整理脚本编写的一些最基本语法,包括参数传递,赋值,循环等基本语句,方便后续的脚本编写和改动。
语句注释
单行注释:# ,多行注释:
:'
多行注释用冒号加单引号即可
'
echo 'legal'命令行参数传递
命令行传递参数的方式极其简单, $1 … $ 9 可分别代表输入的 9 个参数,第 10 个参数则使用 ${10} 表示,可以将其赋予变量后便于使用。
一些特殊参数:
$0脚本本身的名称$#输入参数的数量$$进程 ID$*|$ @所有参数(从第一个开始$(PWD)| `pwd` 都能输出当前的工作路径
举个脚本例子如下:
# we accept args from commandline and print it to the screen
# define
args1=$1
args2=$2
# print
echo "using $ { } to get the value of val, what we receive is : ${args1} and ${args2}"
echo "$ can also show : $args1 and $args2"
# we can make those statement in a string, which may transfer to its value
echo "using $ / {} in a string can also get the value like $args1 and $args2"
echo 'using $ / {} in a string single quotes cannot get the value like $args1 and $args2'一些特殊的参数,用来描述基础信息如下:
# basic infomation of script.
name_of_script=$0
num_of_args=$#
PID=$$
args_list=$*
echo "the name of this script is ${name_of_script}"
echo "we have ${num_of_args} args"
echo "and this process' ID is $PID"
echo "$args_list"
echo "$@"
echo "${PWD}"
echo "`pwd`"基本数据类型
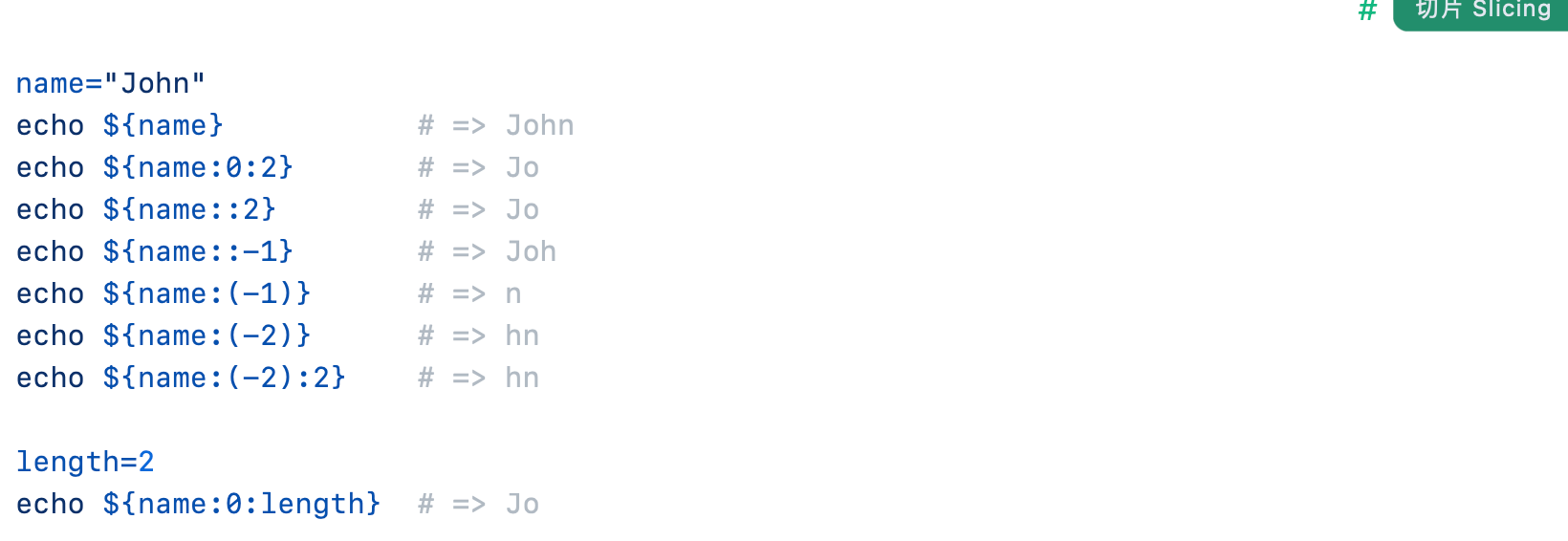
数组和字符串的通用操作:切片方法${name:位置:长度},位置可以取负值,0的话也可以省略成冒号
数组
数组的定义基本规则是:用()定义数组,用 SPC 区分元素。
Fruits_Array=('apple' 'banana' 'ogange')
Array1=({A..D}) # => A B C D还可以使用声明 的方式构造数组:
Bash 的变量定义可以不需要指定类型,但是声明的方式,可以在定义的同时指定变量的类型,其中参数列表可以参考跳转链接。
declare -a Numbers=(1 2 3)
# 不支持{}的方式构造,会只剩下最后一个元素,这个问题还需要深究。数组的调用和大部分语言一样使用 [] 结合索引来调用其中的元素,元素的索引从 0 开始,同时在使用 echo 等特殊情况下,调用数组的时候,由于 [] 的存在所以要使用 ${} 来引用。不能只是用 $
echo ${Array1[0]}Append 操作支持使用 += 实现数组的延伸,如下所示:
Array1+=(2 3)数组的拼接、添加、删除等操作,其中拼接,添加等操作存在一致性,从文件中获取数组的方式更是一个比较实用的命令,但是注意能不能自动识别其中的分隔符,或者自定义呢?
Array2=("${Array1[@]}" "New Element")
# 如果不添加的话也可以用作赋值,同样也可以用这样的方式连接两个数组。
Array1+=("new element")
# 通过正则表达式删除的方法暂时还没掌握,占位。
unser Array1[2] # 删除一项
# 从文件中获取数组
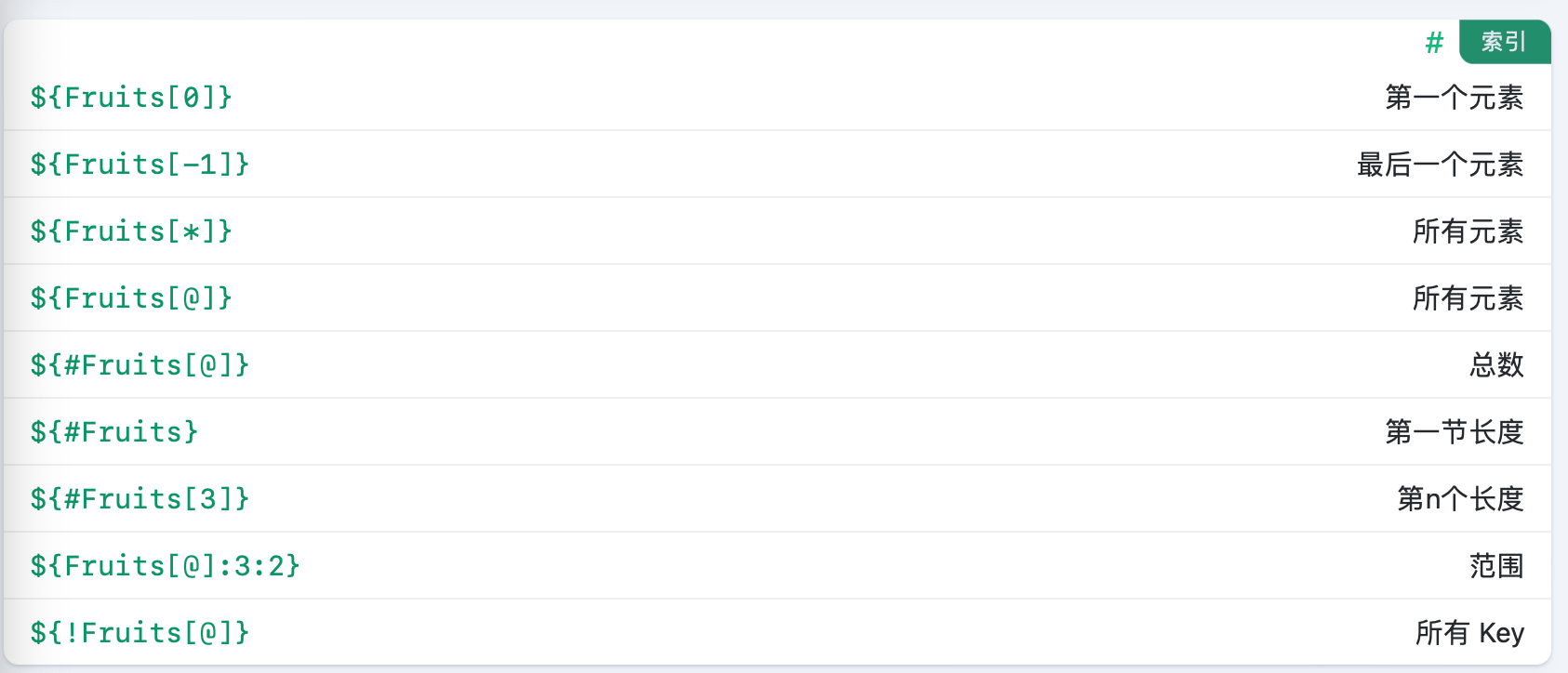
Lines=(`cat "logfile"`)数组的快速索引列表:便于调用或者分析数组的状态,其中范围的用法暂时比较不明确,暂时不使用,后续进行补充。
字符串
在大多语言中,对字符串的操作和数组的操作都会有很多的共通性,同样在bash中也是如此,例如切片之类的行为都和数组是一致的,在这里我们基于独有的共通的来描述。
字符串定义
name="AikenHong.bash"字符串操作
- 删除第一个匹配(前缀)的字符串"suffix"
echo ${name%bash} # 会输出AikenHong.- 删除最后一个匹配(后缀)的字符串"prefix"
echo ${name#AikenHong} # 会输出.bash- 删除(长后缀)
%%,和删除(长前缀)##和非长版本的区别如下,实际上可以理解为删除第一个匹配到的或者最后一个匹配到的,长的版本最好是使用通配符来使用比较好理解。
name2="aikenhong.github.bash.aikenhong"
echo ${name2%%.*} # 输出aikenhong
echo ${name2%.*} # 输出aikenhong.github.bash
echo ${name2# *.} # 输出github.bash.aikenhong
echo ${name2## *.} # 输出 aikenhong只要记住前缀后缀删除的关键命令分别是#和%即可,同理,替换的关键词是/from/to和//from(all)/to一个代表替换第一个,一个代表替换所有。
- 替换命令
echo ${name/AikenHong/Metis} # 会输出metis.bash全部替换的话
echo ${name//n/i} # 会输出aikeihoig.bash- 大小写切换,切换大写使用
^,切换小写使用,,全部切换使用,,或^^,或使用foo[@],和foo[@]^^

字符串的路径处理
SRC="/path/to/foo.cpp"
BASEPATH=${SRC##*/}
echo $BASEPATH # => "foo.cpp"
DIRPATH=${SRC%$BASEPATH}
echo $DIRPATH # => "/path/to/"字典
bash 对字典的支持是后续引入的,如果 bash 在旧的版本可能会出现 declare -A 参数无效的问题。
字典类型有点像是原生之外拓展的类型,只能用 declare 来进行声明,声明后的定义方式借助数组,下面举个例子:
declare -A myDict接着给字典赋值,一种是用来赋初值,另一种是动态赋值方法:
myDict=([key1]="value1" [key2]="value2" [key3]="value3")
myDict['key']=value调用变量进行打印的时候参照定义数组的方式:
echo ${myDict[key1]}其他的一些常见索引,和数组是类似的,但是注意的是!输出的是 key,默认的输出的是 value:

字典的拼接好像没有很方便,建议是使用循环来进行复制实现复制。
基础运算符
- 这里还需要搞清楚两个括号和一个括号的区别˙ Shell 中test 单中括号[] 双中括号的区别
与或非
[[ ! EXPR ]]:Not[[ X && Y ]]|[ -a ]:And[[ X || Y ]]|[-o ]:Or
if [ "$1" = 'y' -a $2 -gt 0 ];
then echo "yes"
fi
if [[ X && Y ]];
then ...
fi数字比较运算符
用于 [[]] 的比较运算符如下
-eq|-ne:(equal)等于 & 不等于-lt|-le:(less than)小于 & 小于等于(less or equal)-gt|-ge:(greater than)大于 & 大于等于
[[ NUM -eq NUM ]]用于 (()) 情况下的比较运算符
<|<=|>|>=
( NUM < NUM )字符串比较运算符
[[ -z STR ]]:空字符串[[ -n STR ]]:非空字符串[[ STR == STR ]]|[[ STR = STR ]]|[[ STR != STR]]:相等 | 不相等[[ STR < STR ]]|[[ STR > STR ]]:基于 ASCII 的大于小于[[ STR =~ re ]]:正则表达式(re)
if [[ -z "$string" ]]; then
echo "String is empty"
elif [[ -n "$string" ]]; then
echo "String is not empty"
else
echo "This never happens"
fi文件比较运算符
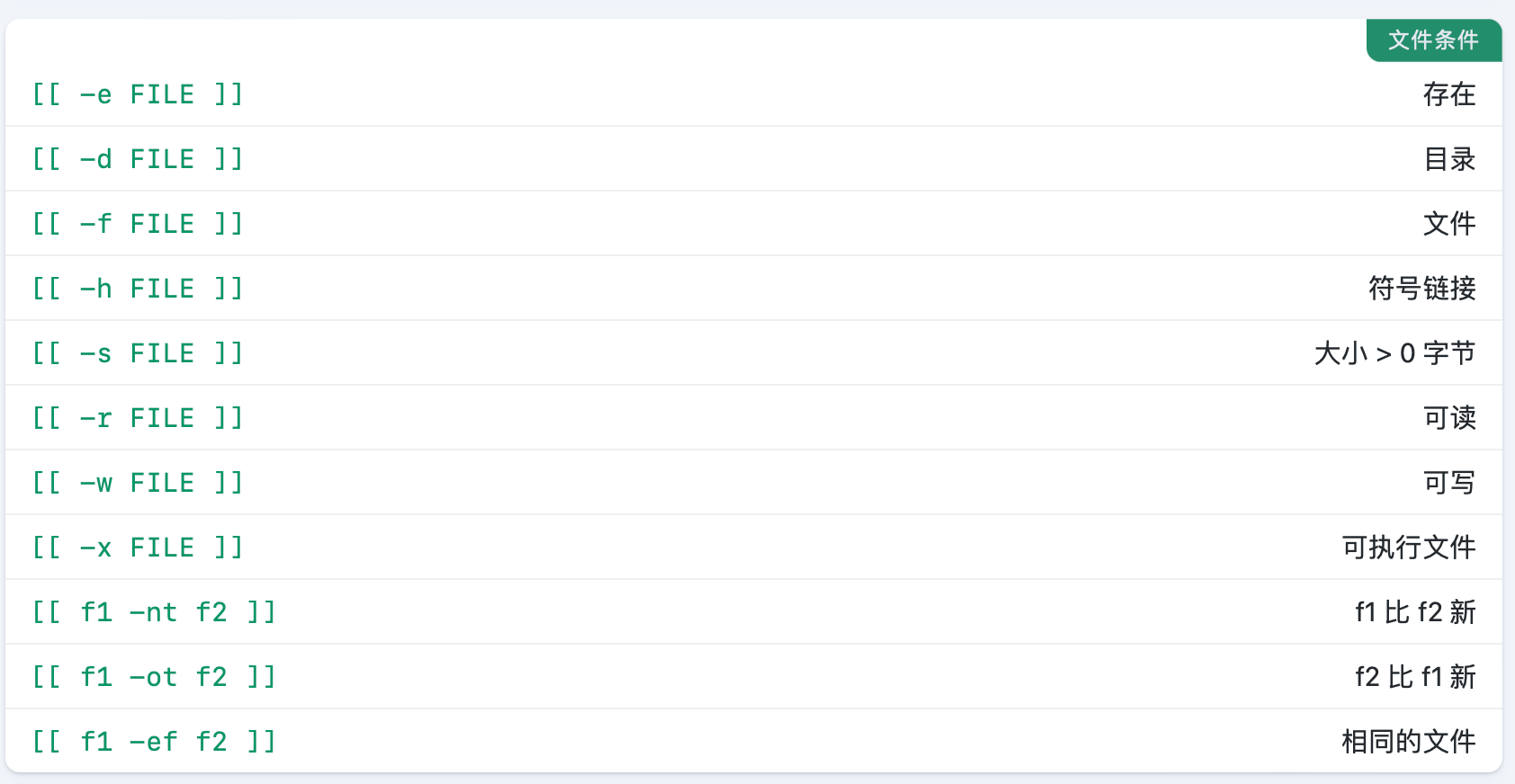
循环语句
Shell 中的循环语句主要分为以下的几种,for | while | until 模式,以循环输出数字给出例子。for 和 while 和其他语言中的一致,until 为当条件不满足的时候一直进入循环,直到满足条件的时候退出循环(和 while 相反)
在描述循环之前,先解释一下生成序列的一些方法(下面都能生成 1 到 n 的序列),就像range:
seq 1 n | seq 1 step n
{1..n} | {1..n..step}
"a b c d" # 会产生 a b c d 的序列
‘word1’ ‘word2’ # 也会产生相应的序列break和Continue的用法和其他语言中的是一致的,这里不再赘述。
for 循环
for … in … 模式: 和 python 类似,针对任何类型的列表进行循环,可以结合上述的序列生成方法进行循环。
echo 'using seq to generate list'
for i in `seq 1 3`;
do
echo $i
done
for i in $(seq 1 3);
do
echo $i
done
echo 'using {...} to generate list'
for i in {1..3};
do
echo $i
donec 模式:类似 c 语言系列的 for 循环,相比于 list 相对灵活一些,较好构造。
for ((i=0;i<3;i+=2));
do
echo $i
done利用 for 循环遍历文件:和*一起使用可以方便的遍历文件,算是 for 循环的一个优势。
for i in *.sh; do
echo $i
done
for i in /etc/rc.*; do
echo $i
done需要注意的事:如果 do 和循环同行的话就需要分号,如果执行了换行就不需要分号了。
while 循环
当条件满足的时候进入循环,用法如下:
i=3
while [[ $i -gt 0 ]]; do
echo "Number: $i"
((i--))
done典型的用法就是用来读取文件,这种时候可以通过管道命令来使用 while;
cat file.txt | while read line; do
echo $line
doneuntil 循环
until 是当条件不满足的时候进入循环,用法如下:
count=0
until [ $count -gt 10]; don
echo "$count"
((count++))
done基本函数定义和使用
函数定义
get_name() {
echo "Aikenhong"
}
echo "you are $(get_name)"也可以使用 function 的关键字来替换
function get_name() {
echo "Aikenhong"
}
echo "you are $(get_name)"函数的参数传递:函数相当于另一个命名空间,所以其中的传入的函数参数列表和函数的参数列表本身是互不影响独立的。
# 假设此时的脚本的参数输入$1=Aikenhong
print_string(){
echo $1
echo $2
}
echo "author is $1"
print_string hello world
# 最终会输出author is Aikenhong hello world传入参数的方式也如上面的例子所示。
函数的返回值: https://www.runoob.com/linux/linux-shell-func.html
myfunc() {
local myresult='some value'
echo $myresult
}
result="$(myfunc)"函数用于抛出错误:
myfunc() {
return 1
}
if myfunc; then
echo "success"
else
echo "failure"
fiReference
In Addition
g++ helloworld.cpp -o a
./a <input >output更新 Mac 的 bash 版本
- 安装新版 bash 版本
brew install bash - 查看安装完的 bash 路径
which -a bash并通过bash --version确认新bash - 注册新 bash:
sudo vim /etc/shells,将新路径加在最后一样,重启终端即可。 - Zsh 不需要操作,重启后会自动使用新的这个 bash。
- 但是注意执行的时候可能需要改成 bash 而不是 sh,sh 我们并没有更新。