
@Langs: python, torch @reference: d2l-pytorch,transfer_torch
This Note focus on the code part. 模型微调和模型预训练,在Pytorch中的使用方式对比汇总。
How to Design the Fine Tune
这一部分主要集中于我们对于微调任务的拆解,有几种不同的预训练和微调的方式,在不同的情景下,对应的参数应该怎么设置和调整是问题的重点。
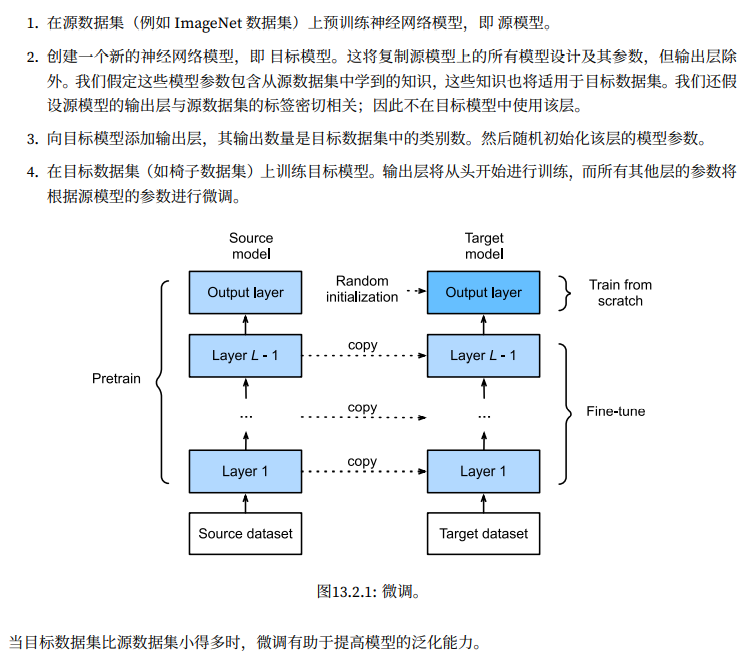
基于这种Transfer的策略,我们能够学习到一个更通用,泛化能力更强,有助于识别边缘,色彩,等等有助于下游任务的通用特征提取。
在Transfer任务中,有几种不同的调整方式:
- 固定Bakcbone,只训练Classifier
- 同步微调网络
- 区分学习率,微调Backbone,训练Classifirer
为了实现这几种不同的Transfer方式,需要用到以下的几种方式:梯度截断,lr区分设置等。
Code Part
不同lr设置
微调Backbone,训练Classifier作为最经典的Transfer设定,在Code上也较为复杂,所以我们首先举个这种例子。
相关的文档可以参考:torch.optim
# get dataset
train_img = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
# get new model
pretrained_new = model.expand_dim(dim=out_dim,re_init=True)
# pre train it 定义一个用于微调的函数
# pytorch可以通过字典的形式来区分对设置lr
def train_fine_tuning(net, learning_rate, batch_size=128, num_epoch=5, diff_lr=True):
# set dataloader
train_iter = torch.utils.Dataloader(train_img, batch_size=batch_size, shuffle=True)
test_iter = ...
# set loss
loss = nn.CrossEntropyLoss(reduction='none')
# set diff lr for diff part of it
if diff_lr:
params_1x = [param for name, param in net.name_parameters() if name not in ["fc.weight", "fc.bias"]]
trainer = torch.optim.SGD([{'params': params_1x},
{'params': net.fc.parameters(),
'lr': learning_rate *10}],
lr=learning_rate, weight_decay=0.001
)
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate, weight_decay=0.001)同时不用担心,scheduler可以将我们的两组lr同时进行更新,可以基于下面的代码进行测试
optimizer = torch.optim.SGD([{'params': [torch.rand((2,2), requires_grad=True)]},
{'params': [torch.rand((2,2), requires_grad=True)],'lr': 0.01}],
lr=0.1, momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.1, verbose=False)
for epoch in range(1,10):
scheduler.step()
print('Epoch-{0} lr: {1}'.format(epoch, optimizer.param_groups[0]['lr']))
print('Epoch-{0} lr: {1}'.format(epoch, optimizer.param_groups[1]['lr']))梯度截断
保留Backbone,训练Classifier,截断网络向Backbone的回传,设置学习率仅训练分类器。
表面上写的梯度截断,实际上我们需要做的就是不让优化器优化模型即可,不需要截断梯度的运算,也就是在optim的参数种不添加其他部分的网络即可,
也就是反向一下上面的params_1x即可,然后添加对应的参数。
还有另一种方式,也是官方的实现,也就是使用require_grad来对不需要进行梯度计算的单元进行覆盖设置。 具体的代码可以参考如下:
for name, params in model.name_parameters():
if name not in['fc.weight', 'fc.bias']:
params.require_grad = False
parameters = [p for p in model.parameters() if p.require_grad]
assert len(parameters) == 2加载部分模型
在自监督学习中,只加载Backbone或者只加载Classifier的情况是非常常见的,这就需要我们仅仅加载部分的参数,为了实现该目标,我们可以按照如下的方式进行操作
# 读取训练好的模型参数,获取当前模型的字典
ckpt = torch.load(pretrain_opt['pth'])['model']
model_dict = model.state_dict()
# 获取特定的‘key’将该字典用来更新模型的参数
pretrain_dict = {k:v for k,v in ckpt.items() if 'backbone' in k and 'fc' not in k}
# 更新模型的dict后进行载入
model_dict.update(pretrain_dict)
model.load_state_dict(model_dict)函数中的update需要参数的key和模型中的字典完全匹配,结构相同也不行,因此,在这里还会遇到一个另外的问题就是,模型名称失配问题。
而为了解决这个问题,最简单直接的方法就是,修改对应的key,最内层基本都是一致的,名称上的区别只在于,我们外层的结构不同。
pre_projector_dict = {k.replace('classifier.', ''):v for k,v in ckpt.items() if 'classifier' in k}由此便可以完成对部分模型的加载和匹配。