
@Aiken 2020.9.16
对基本注意力机制的一些资料和理解做一些简单的汇总,着重分析基本思想原理,应用和实现(即 structure),还有一些Weakness和相应的解决方案。
1.TODO-List:
- 根据Lil’Log的Attention?Attention!进行初步的整理
- 各个分类的具体含义分开整理,理解一部分整理一部分,可能结合实际的应用去整理吧。
- 其中很重要的一点是数学分析的部分,需要对数学原理进行整理和领会。
What’s Attention In Deep Learning
在某种程度上,注意力是由我么如何关注视觉图像的不同区域或者我们如何关联同一个句子中的不同单词所启发的:针对于问题的不同,我们会对图像的某些具体的区域重视(某些区域在视觉中呈现高分辨率,而另一些则是低分辨率的情况),或者句子中的某些词重视的情况。

可以解释一个句子中紧密的上下文单词之间的关系,比如我们看到eating就会期待看到food,而color对于我们来说就没有那么重要。
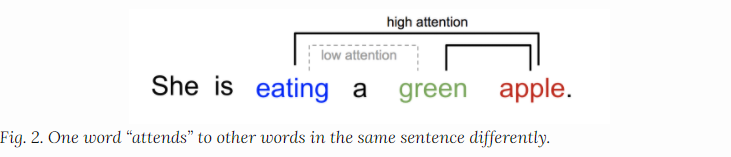
简而言之,深度学习中的注意力就是针对不同问题下的重要性权重的向量,比如我们根据关联性,给上面的每个单词赋予一个相关性的向量权重,然后基于注意力加权后的总和作为目标的近似值。
What’s Wrong with Seq2Seq Model
seq2swq旨在将再encoder-decoder的架构下,将输入序列转换为新序列,对两个序列的长度没有要求。
- Encoder:将输入序列转换成固定长度的context vector,用来概括整个源序列的信息
- Decoder:使用context vector初始化,来进行解码(转换)
这样的Encoder和Decoder架构都是Recurrent Neural Networks,就像LSTM和GRU架构。
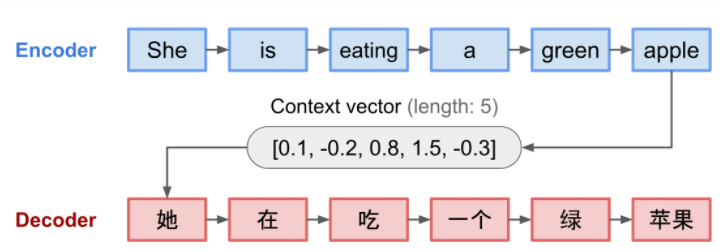
缺陷:固定长度的context vector可能会导致序列信息的缺失,同时可能会无法记住长句子,同时也会丢失时序的对齐信息。所以Attention就诞生了。
:question:
Born for Translation
这几个部分的研究都是基于NMT自然机器翻译,来进行分析的(文本非图像)
原本的E-D是通过Encoder的最后一个hidden states构建单个Context Vector,而Attention 做的就是在Context Vec和Source之间建立一个Shortcut(简单的Feed Forword Network),而源和目标的对齐由上下文向量来学习和控制。而上下文中应该consumes(包含)几个维度的信息
Encoder的hidden States;
Decoder的hidden States;
Source 和 Target之间的对齐信息;
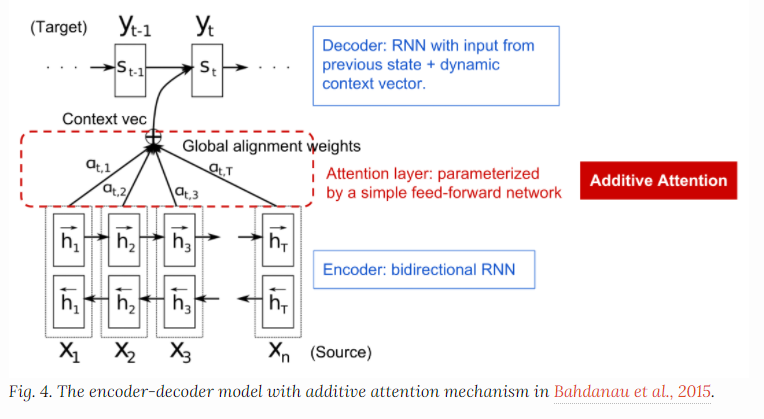
Encoder Decoder实际上都是RNN的架构,S实际上就是H,隐层状态,Decoder对EOS输出了一个初始的预测Y以后,推进Decoder的进程。
双向的recurrent network(bidirectional RNN)使得Encoder隐态同时考虑前后单词。而在Decoder中
s_t = f(s_{t-1},y_{t-1},c_t)
其中上下文向量c_t是输入序列的隐态之和,通过alignment score来进行加权。
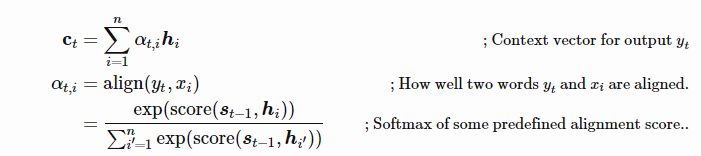
$a_{t,i}$ 将作为输入i对输出t的隐态加权(相关性),在网络中共同训练,通过tanh来进行激活处理。Score则使用下面的策略:
其中V, W都是对齐模型中学到的参数
最终对齐完成以后就会是:

A Family of Attention Mechanism
Summary
由于这个良好的理论基础和实现效果,以及对序列的良好兼容性,这样的算法就被很快的拓展到了计算机视觉的领域中。(学 科 交 叉)
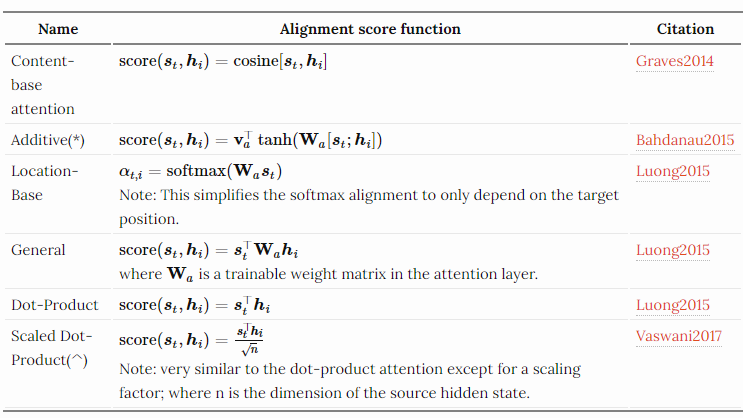
这些不同的score方法实际上就是对每个position上的input和当前位置(通常用上一个时刻的state)来进行相关性建模,针对这些相关性建模,来确定输入对于下一个状态的影响因子,也就是得到一个context向量。这实际上就是注意力机制的核心理念把。
Referred to as “concat” in Luong, et al, 2015 and as “additive attention” in Vaswani, et al, 2017.(^) It adds a scaling factor 1/n−−√1/n, motivated by the concern when the input is large, the softmax function may have an extremely small gradient, hard for efficient learning.
下面对一些更广泛类型的注意力机制做一个摘要性的总结
Self-Attention
这个已经在我的Onenote中整理过了,大概看看就好。这里只讲了一些应用上的点,
自我注意,内部注意力,也就是自我内部关联的注意力关系获取;
Soft vs Hard Attention
Image Caption《show, attend and tell》,CNN获取特征,LSTM解码器利用卷积功能来逐一生成单词。通过Attention 来学习权重,可视化如下:

根据注意力是访问整个图像还是访问图像的一个patch来定义hard和soft attention。
**Soft Attention:**就是普通的全图Attention,将权重放在图像的所有色块上,基本没啥区别
- Pro: 模型平滑容易微分
- Con:expensive when the source image is large
**Hard Attention:**一次只处理一小块图像,其实就相当于用0/1去对图像区域进行硬编码 ,只对一部分的图像进行处理,但是这种方式的技术实现我还是没什么概念,后面可以专门研究一下。
- Pro:推理计算需求比较小
- Con:不可微分,需要用更复杂的技术来进行训练(例如variance reduction or reinforcement learning)
Global vs Loacal Attention
Global实际上就和soft是类似的,而局部注意力机制更像是hard和soft之间的一个融合,对改进hard使其可以微分;
the model first predicts a single aligned position for the current target word and a window centered around the source position is then used to compute a context vector.
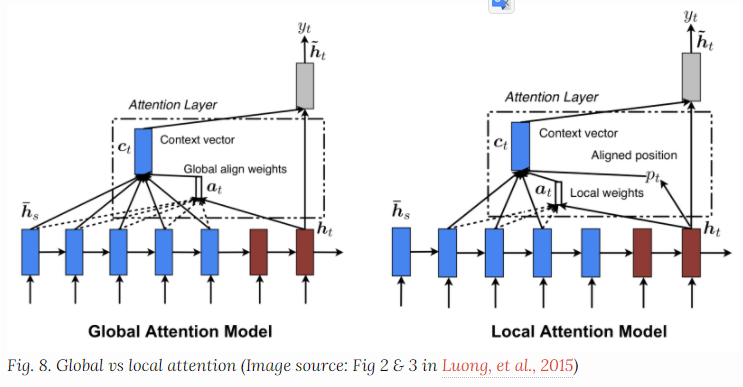
后面提到了一些神经图灵机的内容就是一些基本的计算机制,实际上可能是启发LSTM设计擦除算法设计的根源。
Neural Turing Machines
Attention Mechanisms
可以将权重的看作一个神经图灵机的寻址权重:(基于位置或者基于内容的两种方式)
Content-based addressing:
基于内容寻址的权重设置从输入行和存储行提取的键值向量之间的相似度来创建关注向量:权重的具体计算通过余弦相似度后进行softmax归一化来进行权重的分配。
另外通过β系数来放大或者减弱分布的焦点。
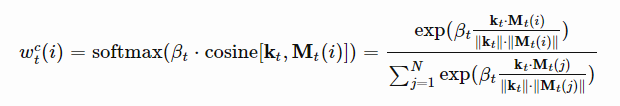
Interpolation 通过interpolation gate scalar $g_t$ 将生成的上下文向量和上一步生成的注意力权重进行混合
Location-baesd addressing 基于位置的寻址,对注意力向量中不同位置的值进行求和,通过对允许的整数偏移位置中的权重来进行参数加权。这相当于是一个一维卷积来测试偏移量。
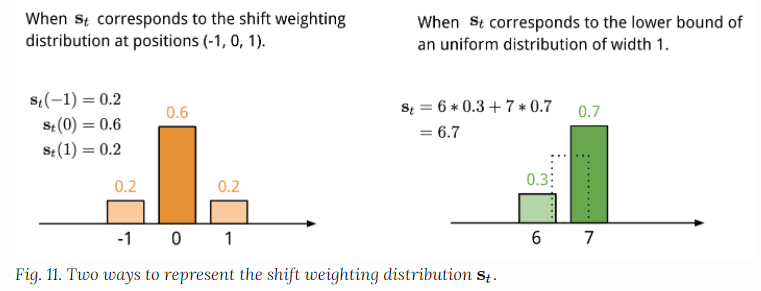
然后对注意力的分布进行锐化处理,使用γ参数
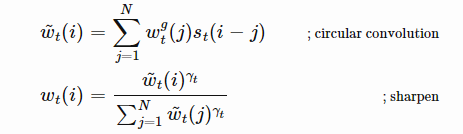
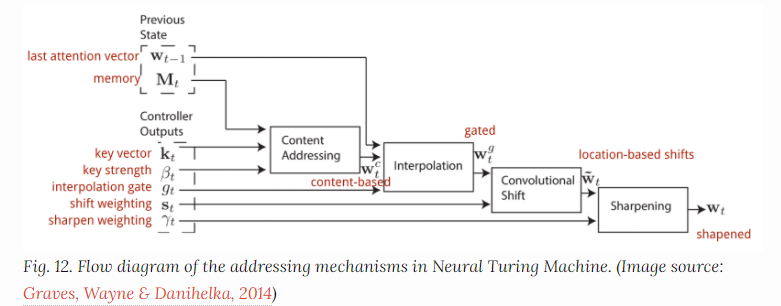
完整的注意力workflow为:
Pointer Network
解决的是输入输出都是顺序数据的问题。
Transformer Introduction
Attention is all u need :提出的重要的Transformer的这种架构,使得算法能够完全基于注意力机制,而不需要序列对齐的recurrent Network。
Key,Value and Query
这一块还是详细解读一下,这里说的太粗略了,没讲清楚。
Transformer的主要重要的架构在于multi-head和self-attention,Transformer将输入堪称一个key-value pairs,均为输入长度n。
Key Value Query 到底都是些什么东西。
Encoder-Decoder and Taxonomy of Attention
基本的encoder-decoder是基于对序列处理的问题提出的,通常情况下针对的是输入输出都是序列的计算模型。下图a展示了典型的E-D机制,以及加入了self-attention的情况b。(文中提到了一些E-D机制的问题)
Seq2Seq的RNN序列模型Encoder需要把之前的输入最终转化成单一的ht(定长),可能会造成序列信息的丢失,同时他只能平权的考虑输入,不能有所重点。同时对于时序对齐信息也会丢失,这对结构化特别重要
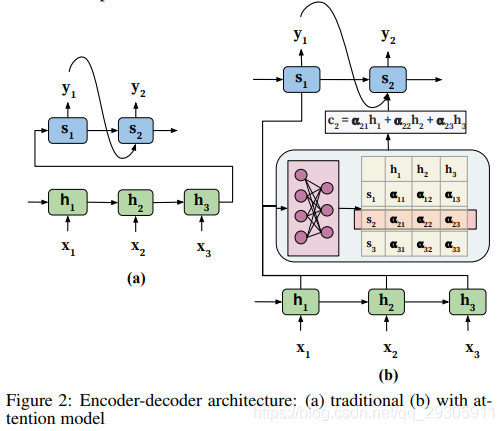
注意力机制,在实现上就是通过在体系架构中,嵌入一个额外的前馈神经网络,来进行学习额外的参数(作为Decoder的补充输入,作为序列和之前信息的补充),而且通常,这个前馈的神经网络是需要和encoder-decoder协同训练的,也就是需要和整体网络共同训练。
训练层面是否存在一些特殊的情况,对于一些特殊的Attention 模型,是否需要一些特殊的训练机制。这点如果看到的话,建议需要整理一下
在Survey中,对注意力机制基于多种标准进行了分类,具体的分类情况可以依下图所示,还有一些具体方法的实现。
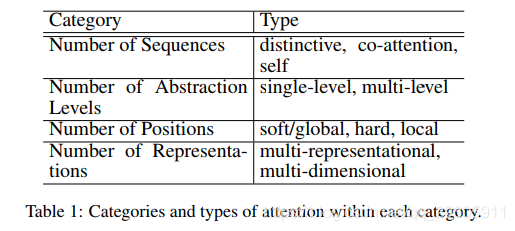

对于几种分类方式,可以参考几个译文的解读,但是我觉得说的并不清楚,后续就分别针对各种方法进行分析吧。
BTW:在RNN等循环结构不能并行化处理的条件下,提出的类似AM的Transformer(Attention is all u need)结构,他的encoder和decoder由两个子层堆叠而来:Feed Forward Network 和 Multi-head self attention。
Position-wise FFN:获取输入的顺序,在encoder阶段,对于每一个token既生成content embedding也生成position encoding。
Multi-Head Self-Attention:在每个子层中使用self - attention来关联标记及其在相同输入序列中的位置,几个注意力层并行堆叠,对于相同的输入有不同的线性转换。这使得模型能够捕获输入的不同方面,提高表达能力。
Transformer and Self-Attention
参考论文以及参考资料1 AND 《Attention is all you need》
Self-Attention :
下图这一段整的明明白白,把整个框架说的比较明白,对输入的embedding(分别做3次卷积,图像输入的情况),分成Query,Key,Value,然后如图进行后续的操作
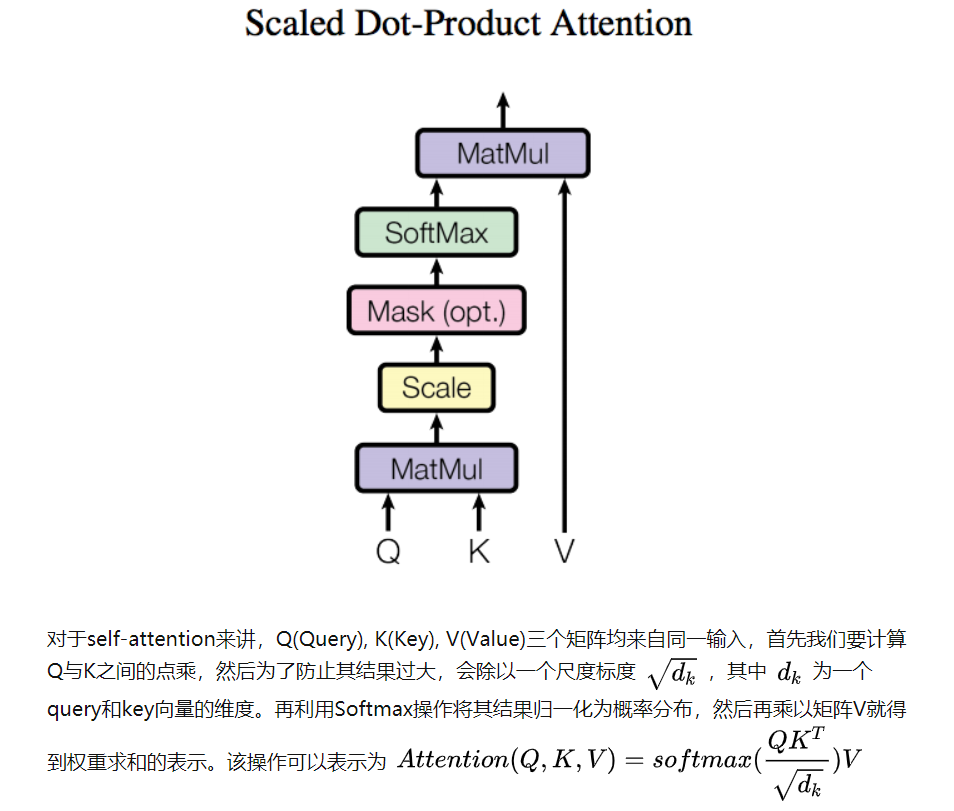
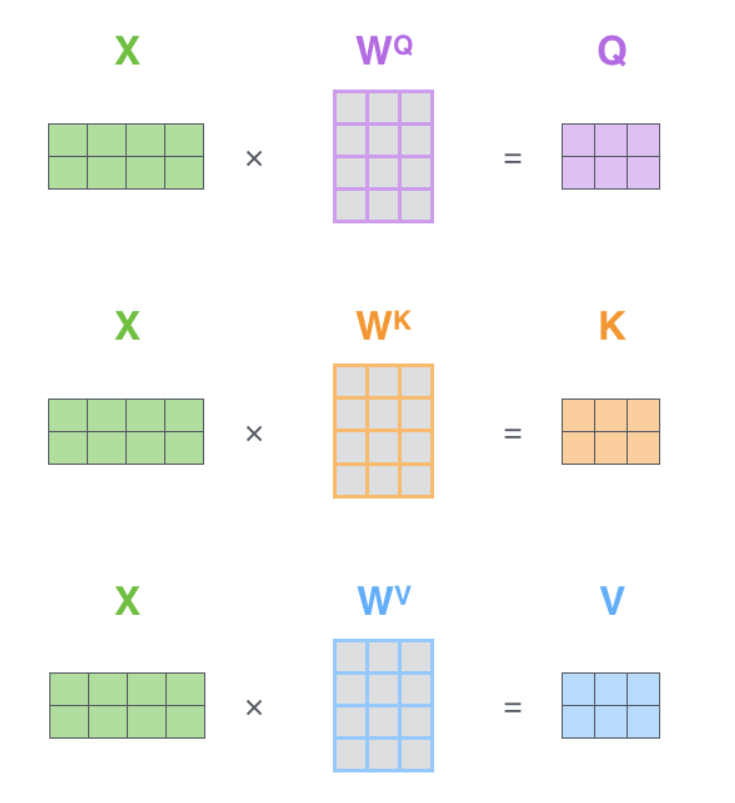
图2就表示了在CV领域,为什么需要将输入做完卷积以后再成进去,而其中的scale由于图片和序列是不一致的,他们的size本来就是统一的(基本规范的数据集中),那么就可以省略掉这一步,从而直接进行softmax,相当于在预处理的时候已经进行了这样的归一操作。
self-attention 是 Transformer的基础,通过多个Self-Attention组成的Multi-head Attention 就是Transformer模型的基本结构。
Multi-head Attention
Reference
参考资料
Attention机制详解2:self-attention & Transformer
Survey:
Transformer:
- 《Attention is all you need》Mendeley &OneNote