
RL-DouZero
Desc: GAME, RL
Finished?: Yes
Tags: Paper
URL1: https://arxiv.org/abs/2106.06135
URL2: https://github.com/kwai/DouZero
URL3: https://github.com/datamllab/rlcard-showdown)
使用蒙特卡洛方法进行自我对弈不断更新预测模型的方法,这实际上也是普通人对于强化学习如何在self-play中实现自我更新的最基础的想法把:
自我对弈(记录动作序列)- 用最终的胜负(价值)更新网络。
算法的设计和思路
算法的目标是学习一个价值网路。网络的输入是当前状态和一个动作,输出是在当前状态做这个动作的期望收益(比如胜率)。简单来说,价值网络在每一步计算出哪种牌型赢的概率最大,然后选择最有可能赢的牌型。蒙特卡罗方法不断重复以下步骤来优化价值网络:
- 用价值网络生成一场对局
- 记录下该对局中所有的状态、动作和最后的收益(胜率)
- 将每一对状态和动作作为网络输入,收益作为网络输出,用梯度下降对价值网络进行一次更新
其实,所谓的蒙特卡罗方法就是一种随机模拟,即通过不断的重复实验来估计真实价值。
如下图所示,斗零采用一个价值神经网络,其输入是状态和动作,输出是价值。首先,过去的出牌用 LSTM 神经网络进行编码。然后 LSTM 的输出以及其他的表征被送入了 6 层全连接网络,最后输出价值。
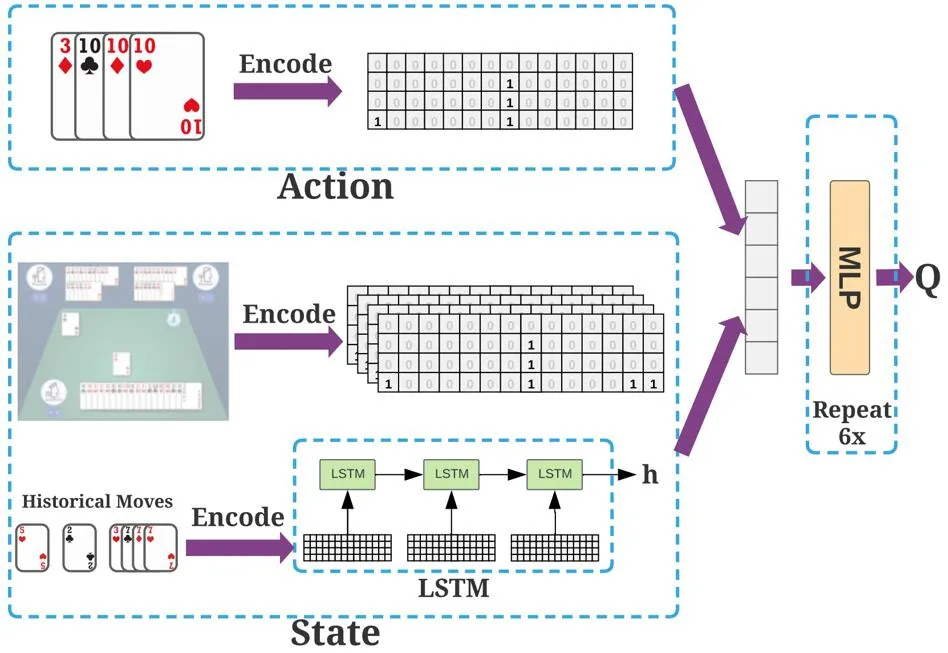
系统训练的主要瓶颈在于模拟数据的生成,因为每一步出牌都要对神经网络做一次前向传播。斗零采用多演员(actor)的架构,在单个 GPU 服务器上,用了 45 个演员同时产生数据,最终数据被汇集到一个中央训练器进行训练。比较有趣的是,斗零并不需要太多的计算资源,仅仅需要一个普通的四卡 GPU 服务器就能达到不错的效果。这可以让大多数实验室轻松基于作者的代码做更多的尝试。
该方法的设计和实现上听起来都挺简单的,可以找个时间自己测试一下,玩一玩这个东西,对于我来说,看看他们怎么用这个lstm去进行历史编码的,以及在对transformer了解后,看看如何用transformer去替代这样的lstm是我这边的研究重点。
蒙特卡洛方法存在的问题
蒙特卡罗方法在强化学习领域中被大多数研究者忽视。学界普遍认为蒙特卡罗方法存在两个缺点:
蒙特卡罗方法不能处理不完整的状态序列
蒙特卡罗方法有很大的方差,导致采样效率很低。
但是斗地主中,可以产生转正的状态序列,同时很容易通过并行来采集大量的样本降低方差,主要是实现上简单,但是可能也是需要大量的数据把。
蒙特卡洛方法在该任务上存在的优势
- 很容易对动作进行编码。斗地主的动作与动作之前是有内在联系的。以三带一为例:如果智能体打出 KKK 带 3,并因为带牌带得好得到了奖励,那么其他的牌型的价值,例如 JJJ 带 3,也能得到一定的提高。这是由于神经网络对相似的输入会预测出相似的输出。动作编码对处理斗地主庞大而复杂的动作空间非常有帮助。智能体即使没有见过某个动作,也能通过其他动作对价值作出估计。
- 不受过度估计(over-estimation)的影响。最常用的基于价值的强化学习方法是 DQN。但众所周知,DQN 会受过度估计的影响,即 DQN 会倾向于将价值估计得偏高,并且这个问题在动作空间很大时会尤为明显。不同于 DQN,蒙特卡罗方法直接估计价值,因此不受过度估计影响。这一点在斗地主庞大的动作空间中非常适用。
- 蒙特卡罗方法在稀疏奖励的情况下可能具备一定优势。在斗地主中,奖励是稀疏的,玩家需要打完整场游戏才能知道输赢。DQN 的方法通过下一个状态的价值估计当前状态的价值。这意味着奖励需要一点一点地从最后一个状态向前传播,这可能导致 DQN 更慢收敛。与之相反,蒙特卡罗方法直接预测最后一个状态的奖励,不受稀疏奖励的影响。
Reference
DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning
RL-DouZero






