
Involution
@Aiken 2021-4-8
Ariticle ;Paper;:star:Code; ZHIHU
Intro 引子
提出了一种新的神经网络算子(operator或op)称为involution,它比convolution更轻量更高效,形式上比self-attention更加简洁,可以用在各种视觉任务的模型上取得精度和效率的双重提升。
通过involution的结构设计,我们能够以统一的视角来理解经典的卷积操作和近来流行的自注意力操作。
基本思想
将传统Convolution Kernel 的两个基本特性:
- 空间不变性:在同个通道的HW上共享3*3的卷积系数,参数共享;
- 通道特异性:在每个通道上有特异的卷积核,最终使用1*1 like的方式来进行通道间的整合
反对称的修改成:
- 空间特异性: 对每个Feature有对应size $H·W·K·K·G | G<<C$ 的kernel,特异性的对不同图像的不同部分进行处理
- G表示Involution操作的分组数,如果需要下采样,就需要接步长为2的平均池化层,最终可以得到,实际上是一个分组卷积的方式,也就是说,我们K个一组的共享一个Kernel。用G去切分C,最终组合起来
- 通道不变性:对每个通道之间共享这样的kernel,然后做简单的线性整合,对每个不同的channel有相同的处理方式。
传统的卷积基于邻域相关性的思想,同时旨在同一个channel中用单一的角度去分析特征,所以有空间不变性核通道特异性的这两个特征。
而Involution实际上更像是Self-Attention这种思路,通过Whole-Size的Kernel,执行一个特异性处理?
要点分析
这一部分主要介绍一些实现上的技术/理论要点:
生成FeatureMap对应Size的Kernel
通用的公式如下,我们可以自定义对应的Kernel生成Function,这是算法的开放性和潜力所在。
其中可能会包含一些线性变换和通道缩减之类的变换,一种简单的实例化可以由下图来理解。
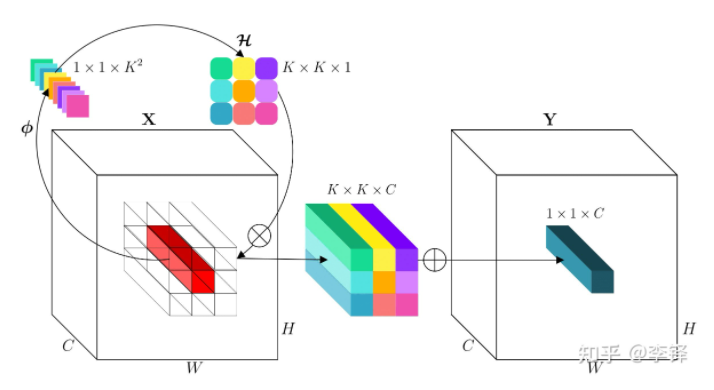
对某个index,首先转化生成对应的$K^2$,对应的Value,然后通过加权整合得到最终的OutputValue, Channel 数的放射就又我们的对应生成的Kernel数去控制。

有点NIN那味了,反正就是嵌套,架构,用MLP得到Kernel,用Kernel进行降维和信息交互。
The Author Says:👇
无论是convolution,self-attention还是新的involution都是message passing和feature aggregation的组合形式,尽管外表各异,本质上没有必要割裂开来看。
与Self-Attention的联系
将Self-Attention的QKV展开成WX的形式,可以发现实际上Involution是Self-Attention的一个General的表达形式,
- self-attention中不同的head对应到involution中不同的group(在channel维度split)
- self-attention中每个pixel的attention map $QK^T$对应到involution中每个pixel的kernel
同时两者在操作后都会加一个线性变换和残差链接,这和Involution中的对应BottleNet也存在一致
Position encoding
self-attention中的计算是loacation-agnostic的所以需要进行position-encoding,但是involution,生成的元素本身就是按照location排列的,所以不需要进行位置编码。
此外,Involution保留了CNN中locally的优先特性。:
因此,我们重新思考self-attention在backbone网络结构中有效的本质可能就是捕捉long-range and self-adaptive interactions,通俗点说是使用一个large and dynamic kernel,而这个kernel用query-key relation来构建则并不是必要的。另一方面,因为我们的involution kernel是单个pixel生成的,这个kernel不太适合扩展到全图来应用,但在一个相对较大的邻域内应用还是可行的),这同时也说明了CNN设计中的locallity依然是宝藏,因为即使用global self-attention,网络的浅层也很难真的利用到复杂的全局信息。
所以我们所采用的involution去除了self-attention中很多复杂的东西,比如我们仅使用单个pixel的特征向量生成involution kernel(而不是依靠pixel-to-pixel correspondence生成attention map),在生成kernel时隐式地编码了pixel的位置信息(丢弃了显式的position encoding),从而构建了一个非常干净高效的op。
Mathematical
画一下计算图来看看实际上是怎么运行的,这里最后的size变换还没弄清楚计算的规则
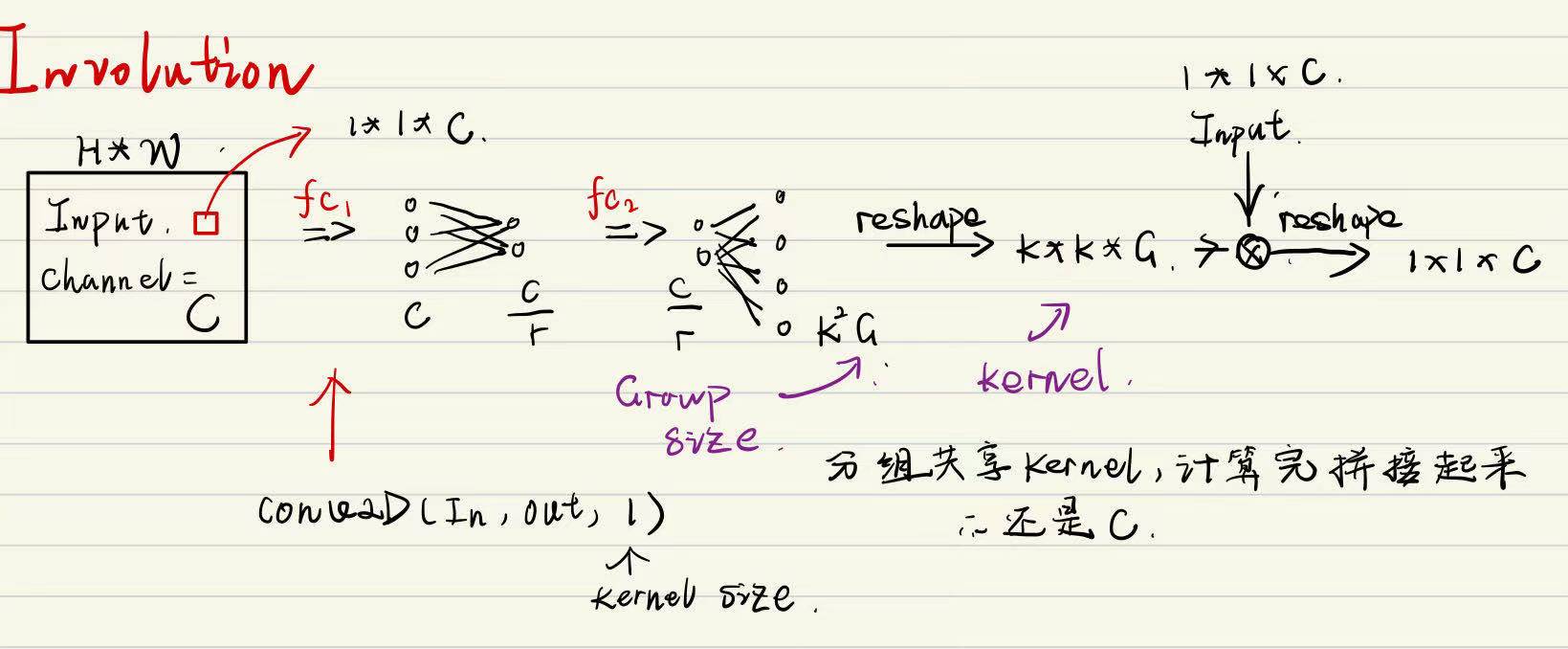
Involution






